See how products, libraries, and frameworks that full under ‘streaming data analytics’ use cases are categorized and compared.
Streaming Analytics processes data in real time while it is in motion. This concept and technology emerged several years ago in financial trading, but it is growing increasingly important these days due to digitalization and Internet of Things (IoT). The following slide deck from a recent talk at a conference covers:
- Real world success stories from different industries (Manufacturing, Retailing, Sports)
- Alternative Frameworks and Products for Stream Processing
- Complementary Relationship to Data Warehouse, Apache Hadoop, Statistics, Machine Learning, Open Source R, SAS, Matlab, etc.
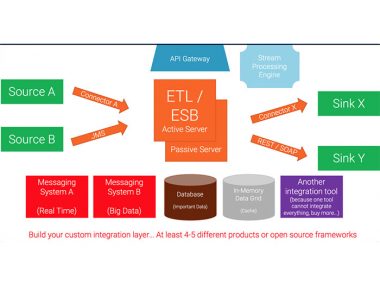
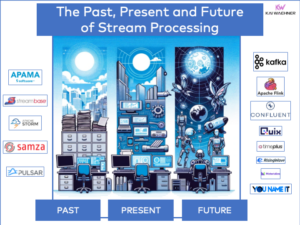
Stream Processing Frameworks and Products
The following picture shows the key differences between frameworks (no matter if open source such as Apache Storm, Apache Flink, Apache Spark or closed source such as Amazon Kinesis) and products (such as TIBCO StreamBase / Live Datamart, IBM InfoSphere Streams, Software AG’s Apama).

Of course, you can implement everything by writing code and using one or more frameworks. However, besides several other benefits, the key differentiator of using a product is time to market. You can realize projects in weeks instead of months or even years. Delivering quickly is the number one priority of most enterprises these days in a world where the only constant is change!
Fast Data and Streaming Analytics in the Era of Hadoop, R and Apache Spark
The following slide deck discusses the above topics in much more detail:
Click on the button to load the content from www.slideshare.net.
Parts of this (extensive) slide deck were used for talks at several international conferences such as JavaOne 2015 in San Francisco. I appreciate any feedback about the content to improve it continuously…If you want to learn more about Streaming Analytics and its relation to Big Data and Apache Hadoop, I recommend the following InfoQ article: Real-Time Stream Processing as Game Changer in a Big Data World with Hadoop and Data Warehouse.