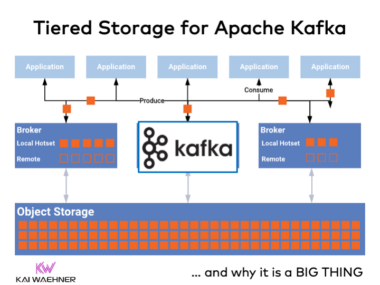
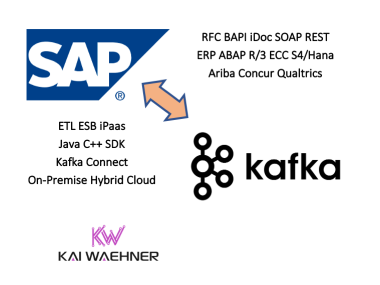
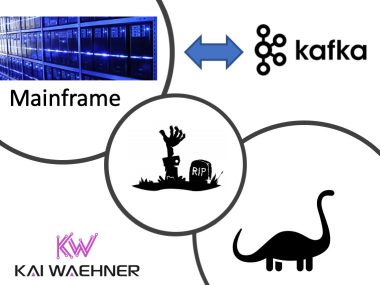
When NOT to Use Apache Kafka? (Lightboard Video)
Apache Kafka is the de facto standard for data streaming to process data in motion. With its significant adoption growth across all industries, I get a very valid question every week: When NOT to use Apache Kafka? What limitations does the event streaming platform have? When does Kafka simply not provide the needed capabilities? How to qualify Kafka out as it is not the right tool for the job? This blog post contains a lightboard video that gives you a twenty-minute explanation of the DOs and DONTs.