In November 2016, I am at Big Data Spain in Madrid for the first time. A great conference with many awesome speakers and sessions about very hot topics such as Apache Hadoop, Spark Spark, Streaming Processing / Streaming Analytics and Machine Learning. If you are interested in big data, then this conference is for you! My two talks:
Here I wanna share the slides and a video recording of the latter one…
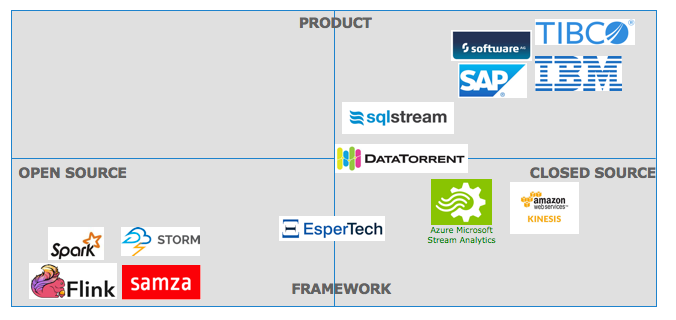
This session discusses the technical concepts of stream processing / streaming analytics and how it is related to big data, mobile, cloud and internet of things. Different use cases such as predictive fault management or fraud detection are used to show and compare alternative frameworks and products for stream processing and streaming analytics.
The focus of the session lies on comparing
The session will also discuss how stream processing is related to Apache Hadoop frameworks (such as MapReduce, Hive, Pig or Impala) and machine learning (such as R, Spark ML or H2O.ai).
The following slide deck is a more extensive version of the talk at Big Data Spain (as the conference talks were only 30 minutes):
The video recording walks you through the above slide deck:
As always, I appreciate any comments, questions or other feedback.
Data integration and workflow orchestration get confused because both ship hundreds of connectors. This post…
Process intelligence has become three things, not one: mining, orchestration, and a decision gate. Here…
AMQP, JMS, Kafka, and MQTT get compared as rivals, but a message broker, a log,…
Most vendors sell milliseconds, but most enterprise use cases do not need them. A critical…
Edge to cloud is not one integration problem. It is four: telemetry going up, control…
The Data Integration Landscape 2026 maps every major vendor across three communication paradigms: request-response, event-driven,…
{kind=link}