I am happy that my first official Confluent blog post was published and want to link to it from by blog:
How to Build and Deploy Scalable Machine Learning in Production with Apache Kafka
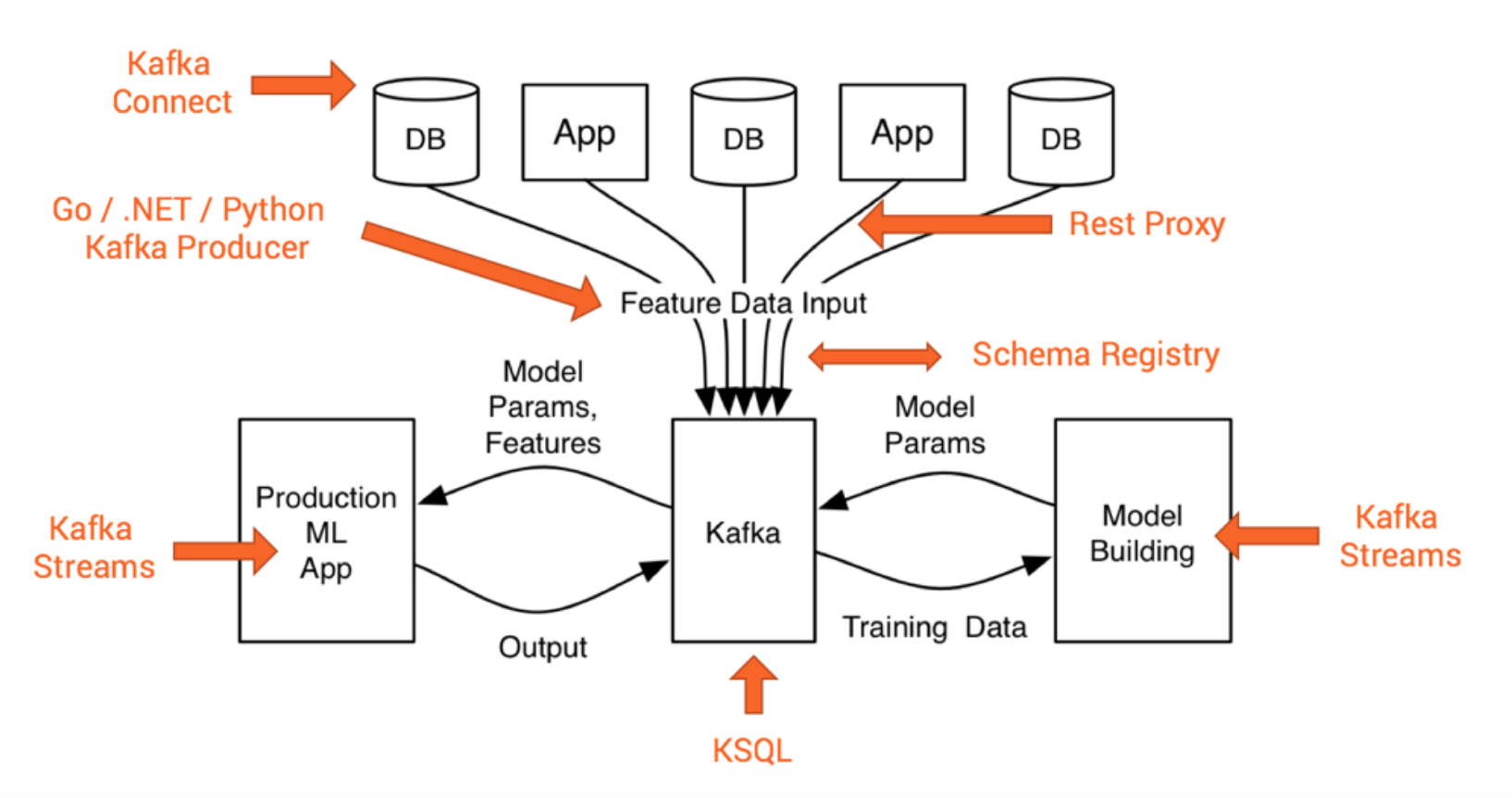
The post explains in detail how you can leverage Apache Kafka and its Streams API to deploy analytic models to a lightweight, but scalable, mission-critical streaming appilcation.
If you want to take a look directly at the source code, go to my Github project about Kafka + Machine Learning. It contains several examples how to combine Kafka Streams with frameworks like TensorFlow, H2O or DeepLearning4J.
Dashboards are a popular way to make streaming data visible and useful, but they are…
Mobile World Congress (MWC) 2026 highlights the shift from batch systems to real time data…
This blog post explores how data streaming transforms airline operations by enabling real-time visibility, faster…
The second edition of The Ultimate Data Streaming Guide is now available as a free…
Apache Kafka has long been the foundation for real-time data streaming. With the release of…
Diskless Kafka is transforming how fintech and financial services organizations handle observability and log analytics.…
{kind=link}