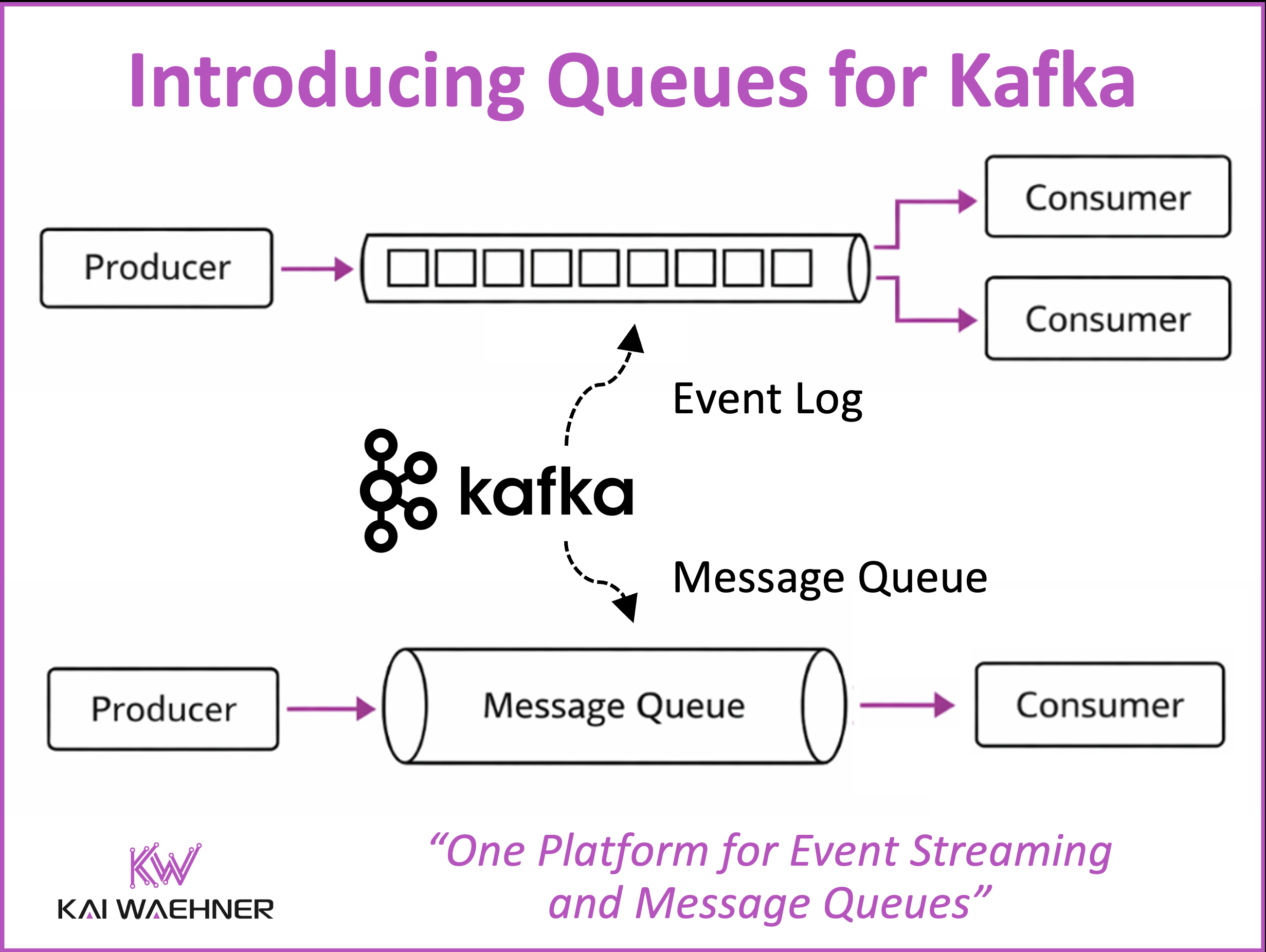
Agentic AI
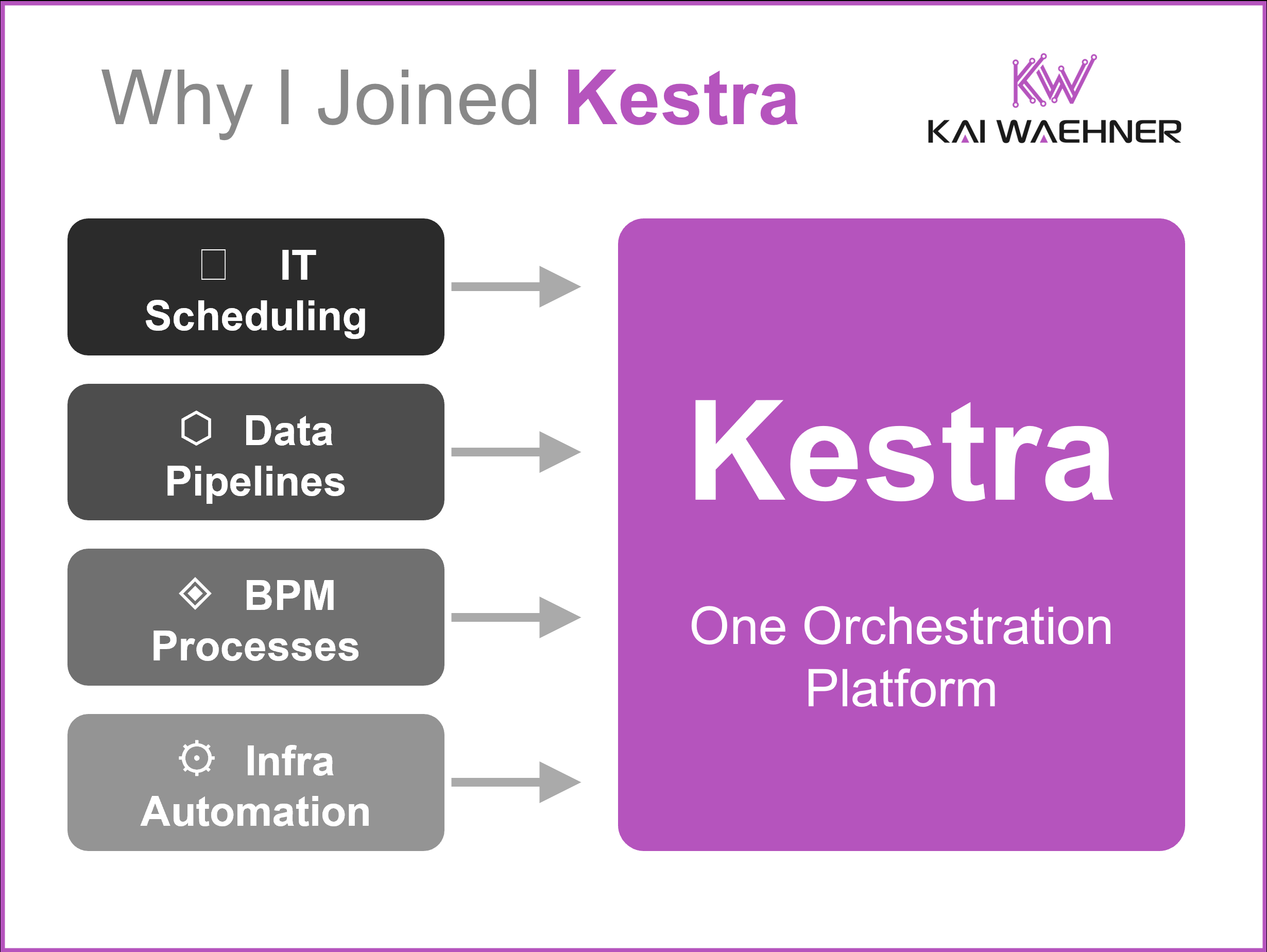
Enterprises run separate tools for IT scheduling, data pipelines, business processes, and infrastructure. None talk to each other. Modernization and agentic AI are forcing them

Enterprises run separate tools for IT scheduling, data pipelines, business processes, and infrastructure. None talk to each other. Modernization and agentic AI are forcing them
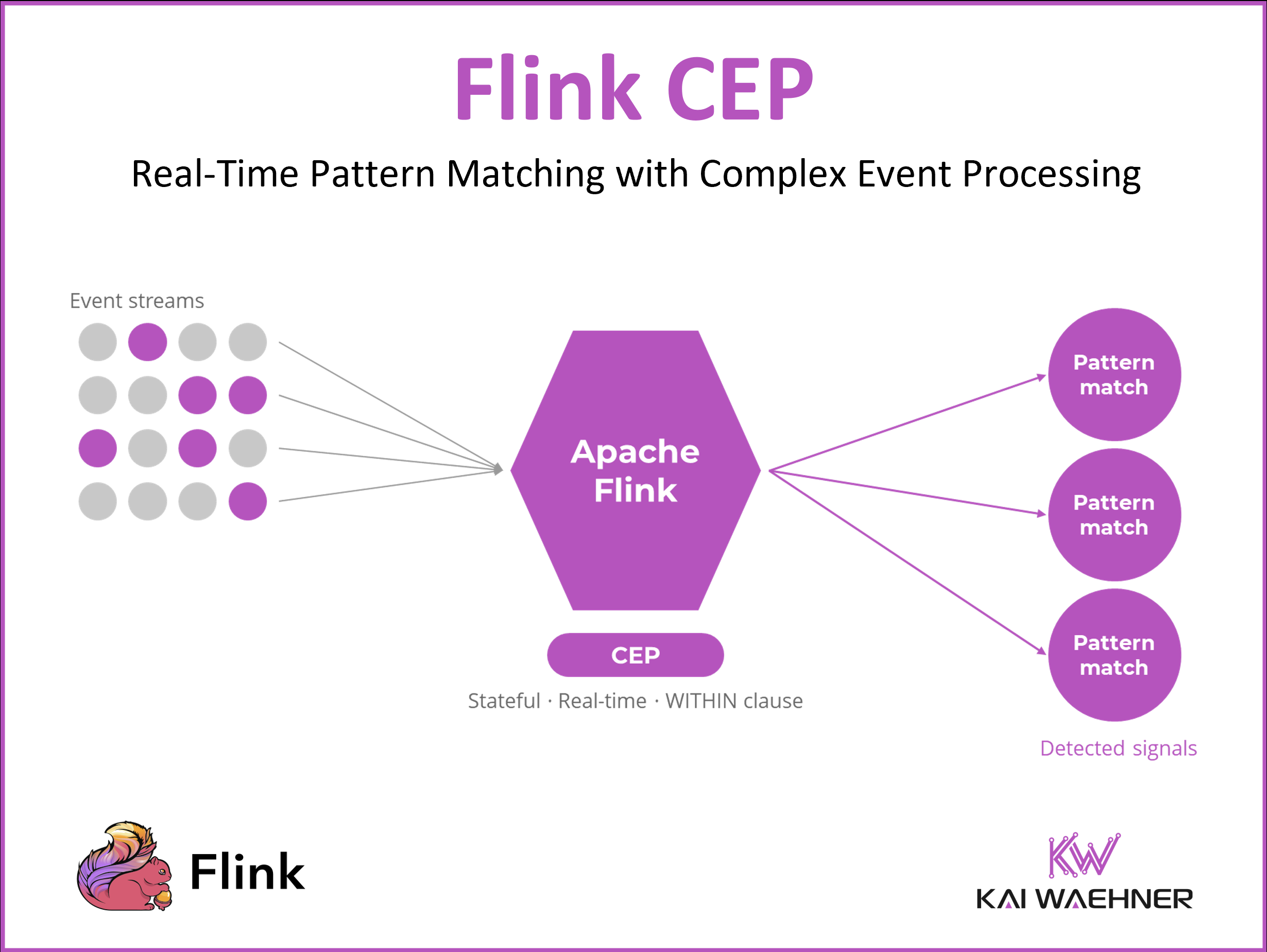
Complex Event Processing is the most underused capability in Apache Flink. It detects meaningful event sequences in real time, fires only when a pattern is

A Kafka proxy adds centralized security and governance for Apache Kafka. Solutions like Kroxylicious, Conduktor, and Confluent enable encryption, access control, and compliance without modifying
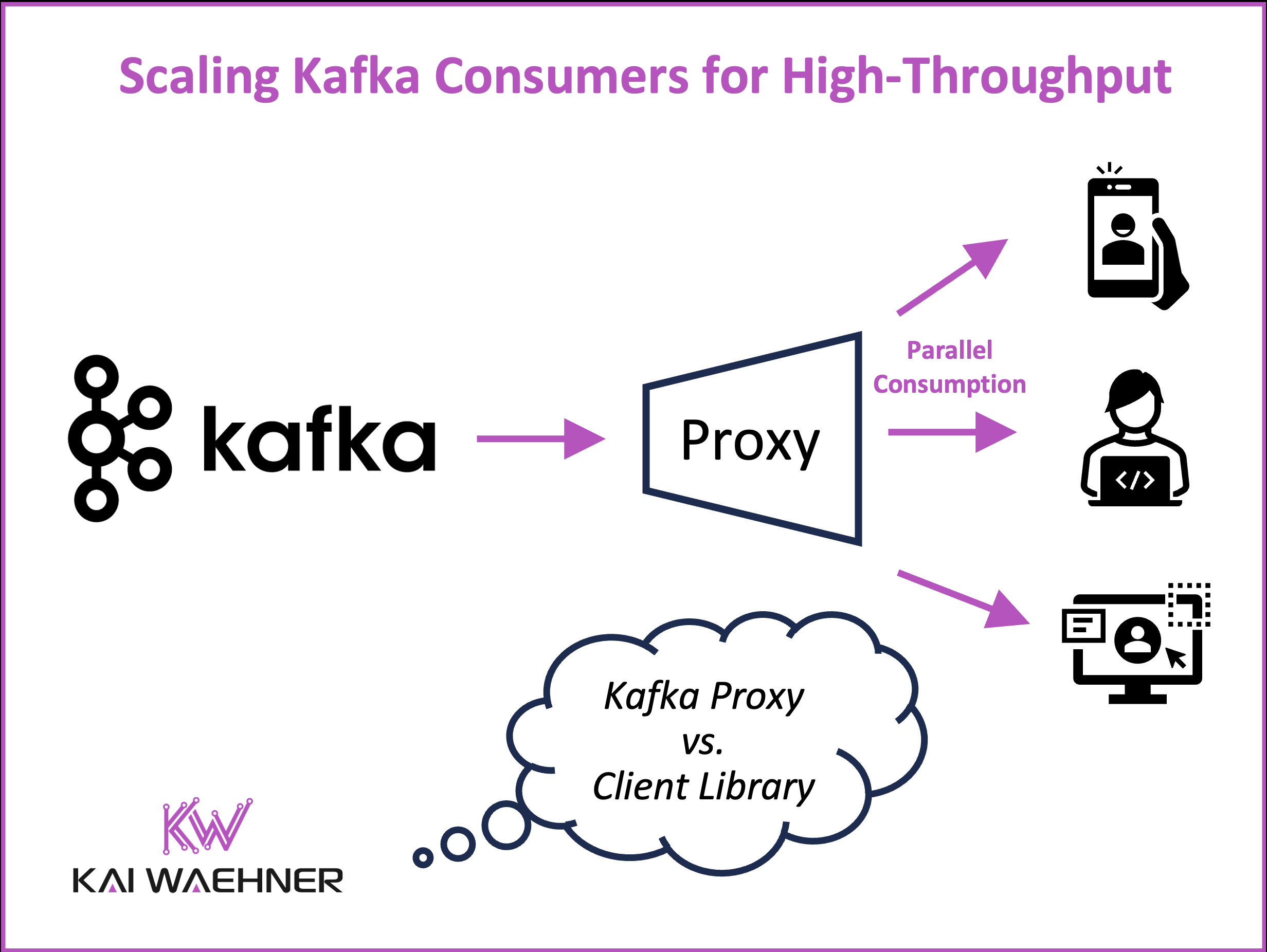
Apache Kafka’s pull-based model and decoupled architecture offer unmatched flexibility for event-driven systems. But as data volumes and consumer applications grow, new challenges emerge; from
Agentic AI is moving into production. Autonomous, tool-using, goal-driven systems that need real-time data and context. Apache Kafka and Flink provide the event-driven foundation to
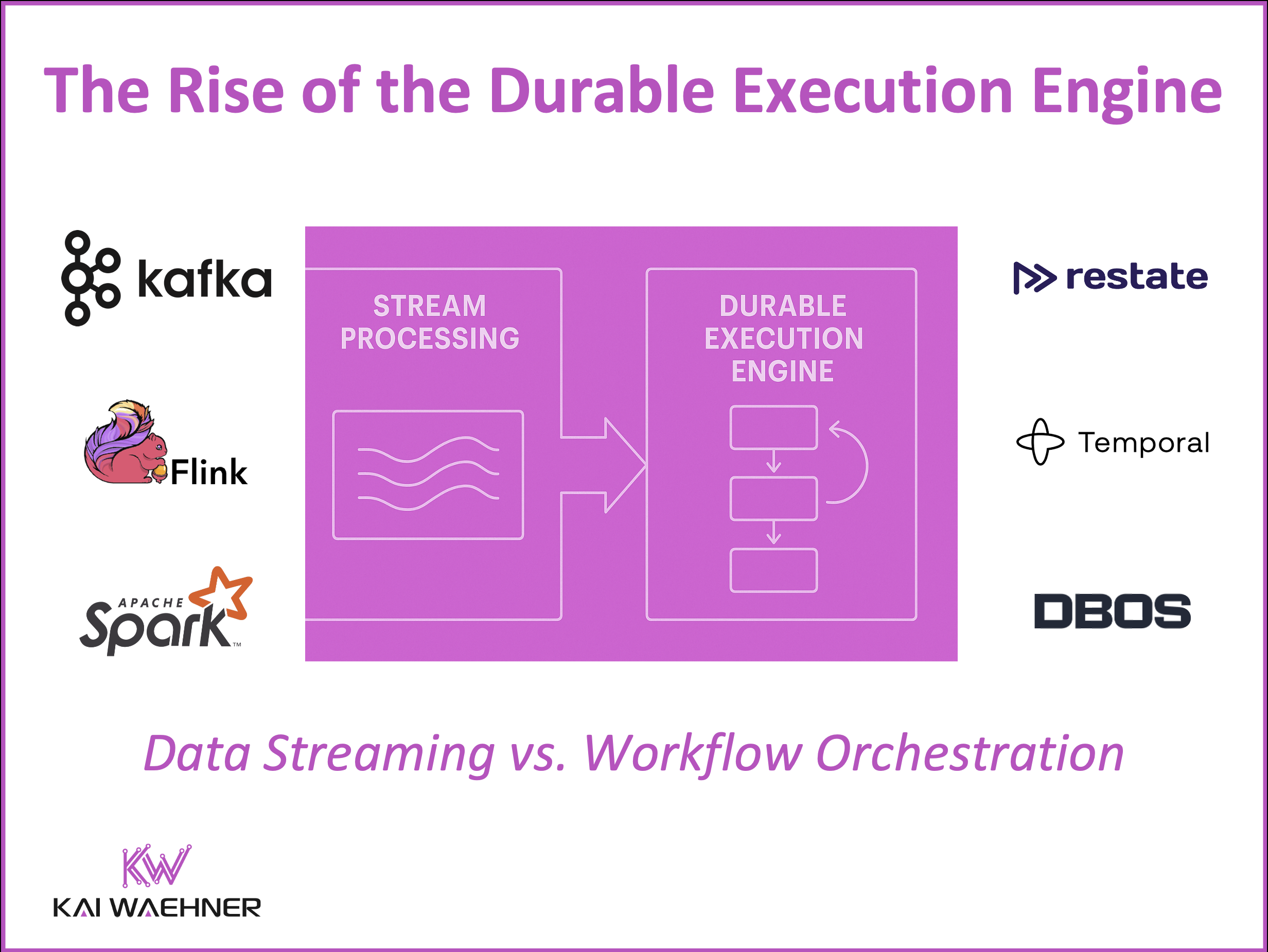
Durable execution engines like Temporal and Restate are redefining how developers orchestrate long-running, stateful workflows in distributed systems. Unlike traditional BPM tools focused on human-centric
Apache Kafka 4.0 represents a major milestone in the evolution of real-time data infrastructure. Used by over 150,000 organizations worldwide, Kafka has become the de
JavaScript is a pivotal technology for web applications. With the emergence of Node.js, JavaScript became relevant for both client-side and server-side development, enabling a full-stack
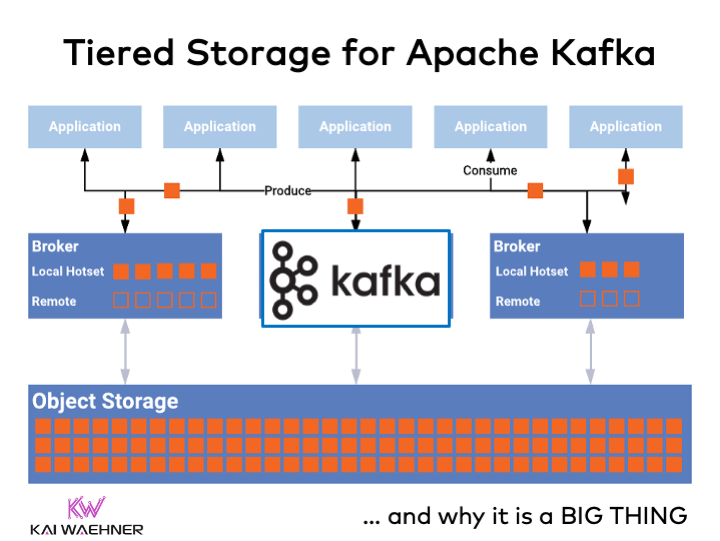
Apache Kafka added Tiered Storage to separate compute and storage. The capability enables more scalable, reliable and cost-efficient enterprise architectures. This blog post explores the




You need to load content from reCAPTCHA to submit the form. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Turnstile. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Vimeo. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from YouTube. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou need to load content from reCAPTCHA to submit the form. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Elfsight. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Facebook. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More Information