Complex Event Processing (CEP) with Apache Flink: What It Is and When (Not) to Use It
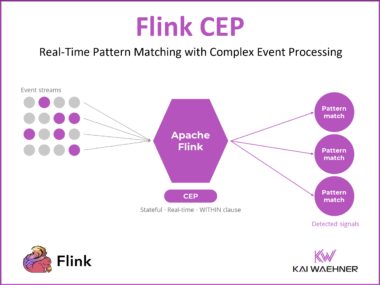
Complex Event Processing is the most underused capability in Apache Flink. It detects meaningful event sequences in real time, fires only when a pattern is confirmed, and even catches events that never arrive. This guide covers what Flink CEP is, when to reach for it instead of stream processing, how to implement it, and what happened to the legacy CEP market.