
Analytics
Confluent and Databricks enable a modern data architecture that unifies real-time streaming and lakehouse analytics. By combining shift-left principles with the structured layers of the

Confluent and Databricks enable a modern data architecture that unifies real-time streaming and lakehouse analytics. By combining shift-left principles with the structured layers of the
This blog explores how Confluent and Databricks address data integration and processing in modern architectures. Confluent provides real-time, event-driven pipelines connecting operational systems, APIs, and
Mobility services like Uber, Grab, and FREE NOW (Lyft) rely on real-time data to power seamless trips, deliveries, and payments. But this real-time nature also
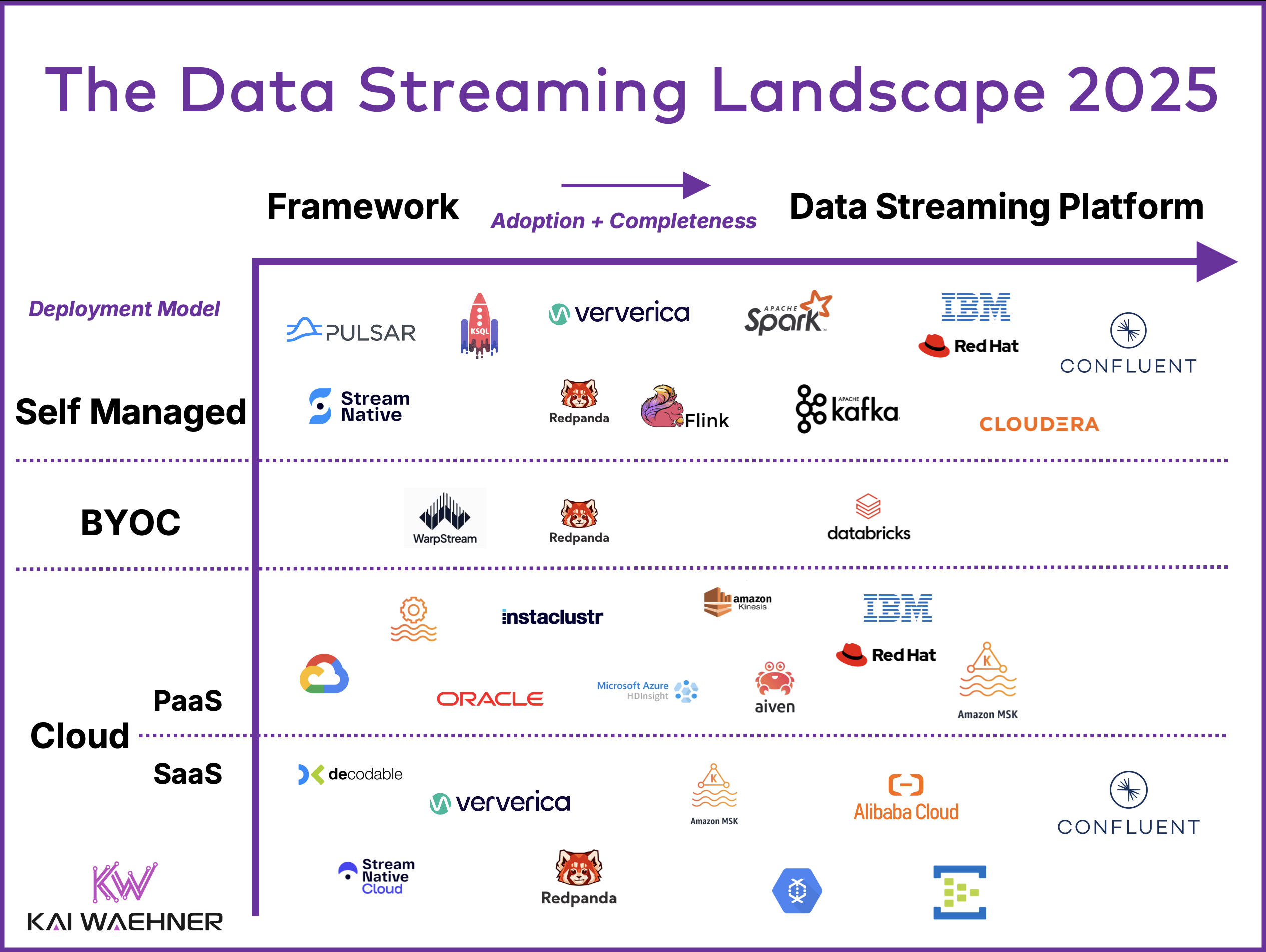
Data streaming is a new software category. It has grown from niche adoption to becoming a fundamental part of modern data architecture, leveraging open source

Apache Kafka and Apache Flink are leading open-source frameworks for data streaming that serve as the foundation for cloud services, enabling organizations to unlock the

The research company Forrester defines data streaming platforms as a new software category in a new Forrester Wave. Apache Kafka is the de facto standard
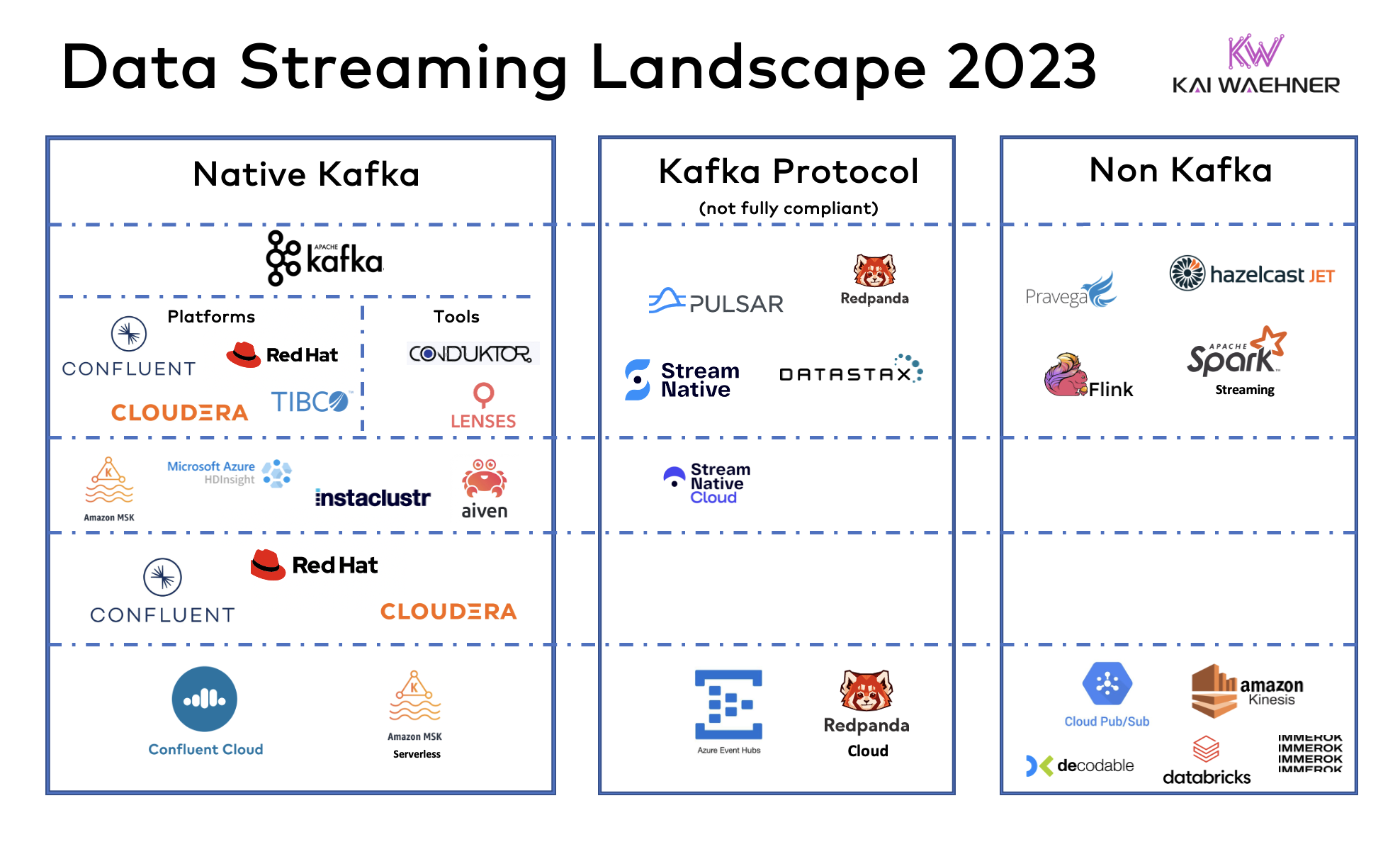
Data streaming is a new software category to process data in motion. Apache Kafka is the de facto standard used by over 100,000 organizations. Plenty

The concepts and architectures of a data warehouse, a data lake, and data streaming are complementary to solving business problems. Unfortunately, the underlying technologies are
At OOP 2018 conference in Munich, I presented an updated version of my talk about building scalable, mission-critical microservices with the Apache Kafka ecosystem and
Apache Kafka Streams to build Real Time Streaming Microservices. Apply Machine Learning / Deep Learning using Spark, TensorFlow, H2O.ai, etc. to add AI. Embed Kafka




You need to load content from reCAPTCHA to submit the form. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Turnstile. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Vimeo. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from YouTube. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou need to load content from reCAPTCHA to submit the form. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Elfsight. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Facebook. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More Information