I am happy that my first official Confluent blog post was published and want to link to it from by blog:
How to Build and Deploy Scalable Machine Learning in Production with Apache Kafka
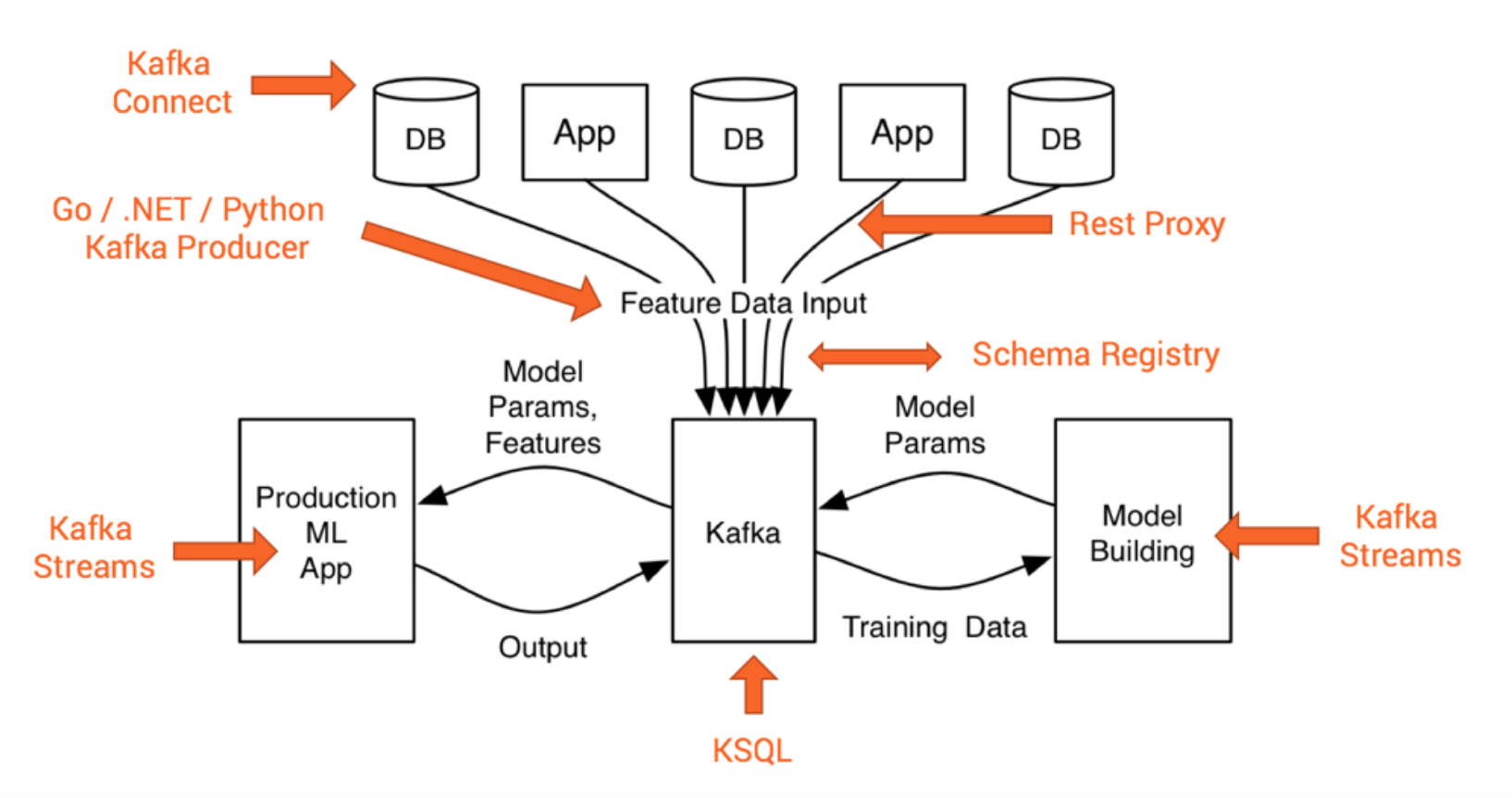
The post explains in detail how you can leverage Apache Kafka and its Streams API to deploy analytic models to a lightweight, but scalable, mission-critical streaming appilcation.
If you want to take a look directly at the source code, go to my Github project about Kafka + Machine Learning. It contains several examples how to combine Kafka Streams with frameworks like TensorFlow, H2O or DeepLearning4J.
Data integration and workflow orchestration get confused because both ship hundreds of connectors. This post…
Process intelligence has become three things, not one: mining, orchestration, and a decision gate. Here…
AMQP, JMS, Kafka, and MQTT get compared as rivals, but a message broker, a log,…
Most vendors sell milliseconds, but most enterprise use cases do not need them. A critical…
Edge to cloud is not one integration problem. It is four: telemetry going up, control…
The Data Integration Landscape 2026 maps every major vendor across three communication paradigms: request-response, event-driven,…
{kind=link}