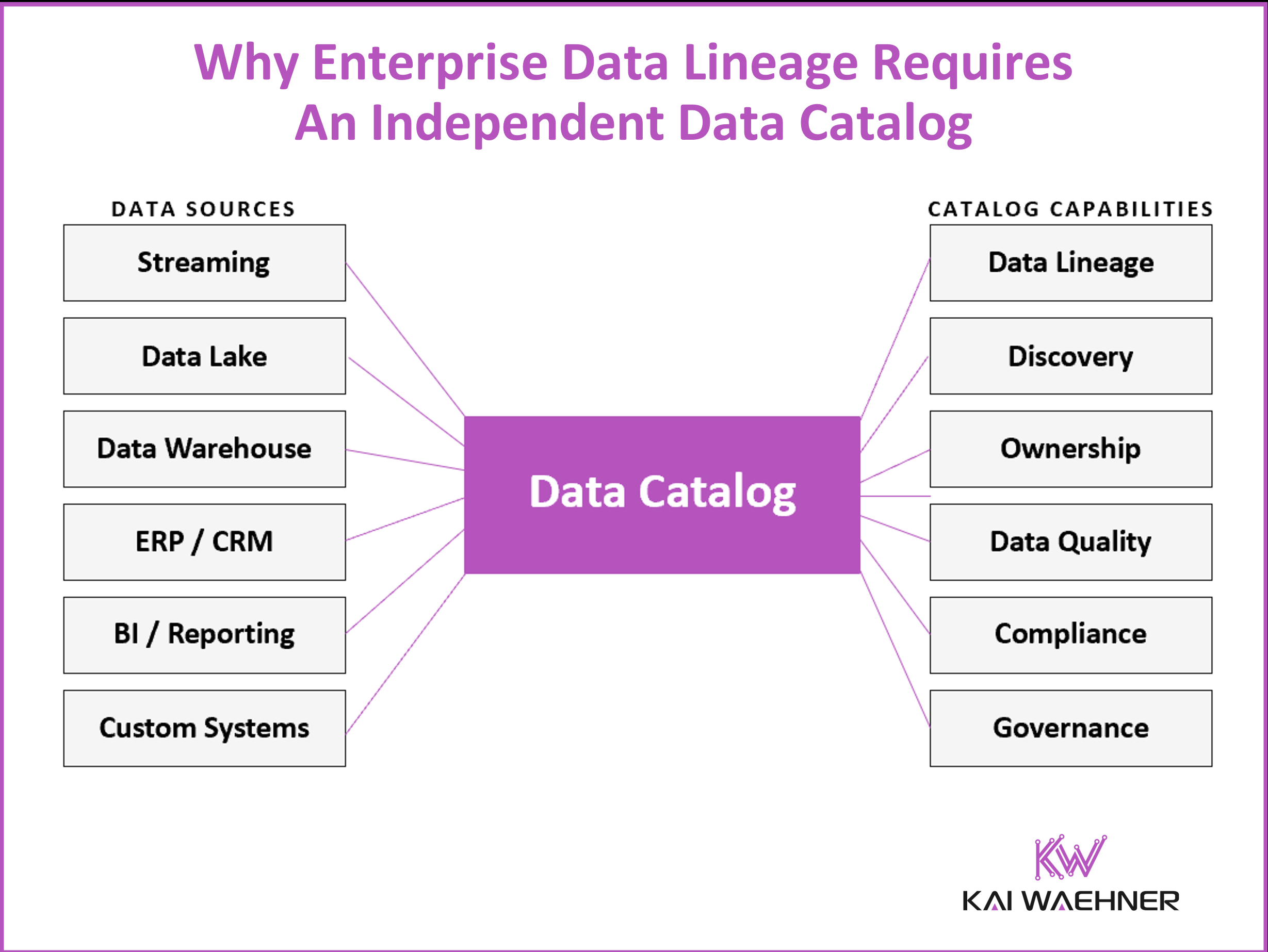
Data Catalog
Most organizations start their data governance journey by asking how to track where data comes from and where it goes. They quickly discover a harder

Most organizations start their data governance journey by asking how to track where data comes from and where it goes. They quickly discover a harder

Industrial enterprises face increasing pressure to move faster, automate more, and adapt to constant change—without compromising reliability. Siemens Digital Industries addresses this challenge by combining

Batch processing introduces delays, complexity, and data quality issues that modern businesses can no longer afford. This article outlines the most common problems with batch
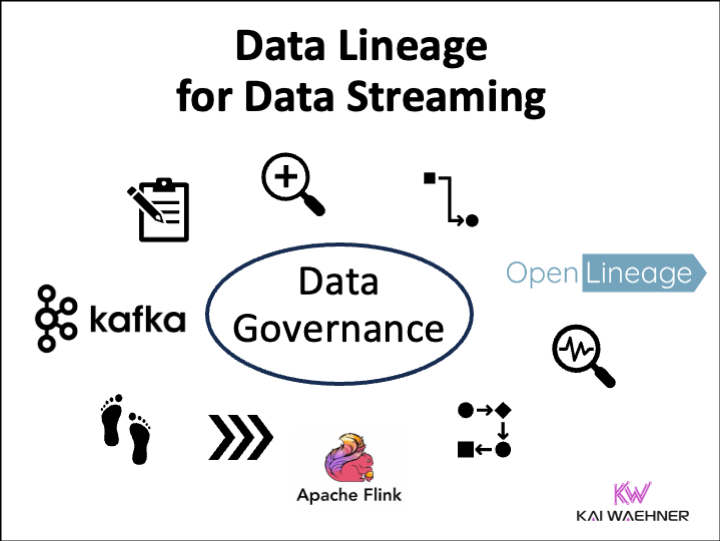
One of the greatest wishes of companies is end-to-end visibility in their operational and analytical workflows. Where does data come from? Where does it go?
Data Preparation: Comparison of Programming Languages, Frameworks and Tools for Data Preprocessing and (Inline) Data Wrangling in Machine Learning / Deep Learning Projects.




You need to load content from reCAPTCHA to submit the form. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Turnstile. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Vimeo. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from YouTube. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou need to load content from reCAPTCHA to submit the form. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Elfsight. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Facebook. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More Information