The Rise of Kappa Architecture in the Era of Agentic AI and Data Streaming
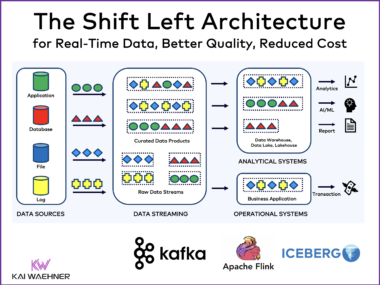
The shift from Lambda to Kappa architecture reflects the growing demand for unified, real-time data pipelines that serve both analytical and operational needs. With the rise of Agentic AI and streaming-first systems, Kappa—powered by Apache Kafka and Apache Flink—delivers low-latency, event-driven infrastructure that supports modern applications, from scalable data products to autonomous AI agents. Open table formats and Shift Left principles further establish Kappa as the foundation for consistent, governed, and future-ready data platforms.