Apache Flink
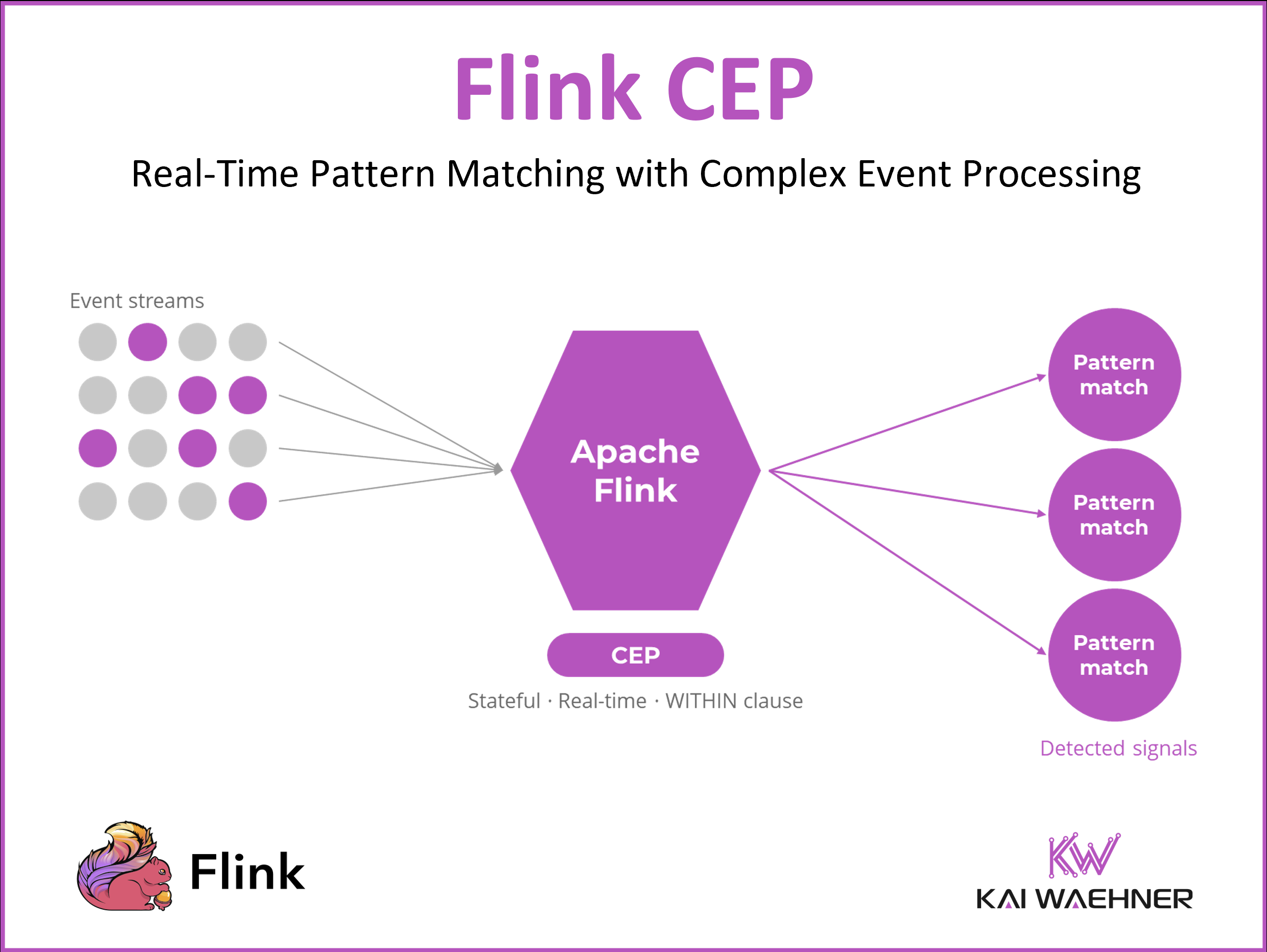
Complex Event Processing is the most underused capability in Apache Flink. It detects meaningful event sequences in real time, fires only when a pattern is

Complex Event Processing is the most underused capability in Apache Flink. It detects meaningful event sequences in real time, fires only when a pattern is
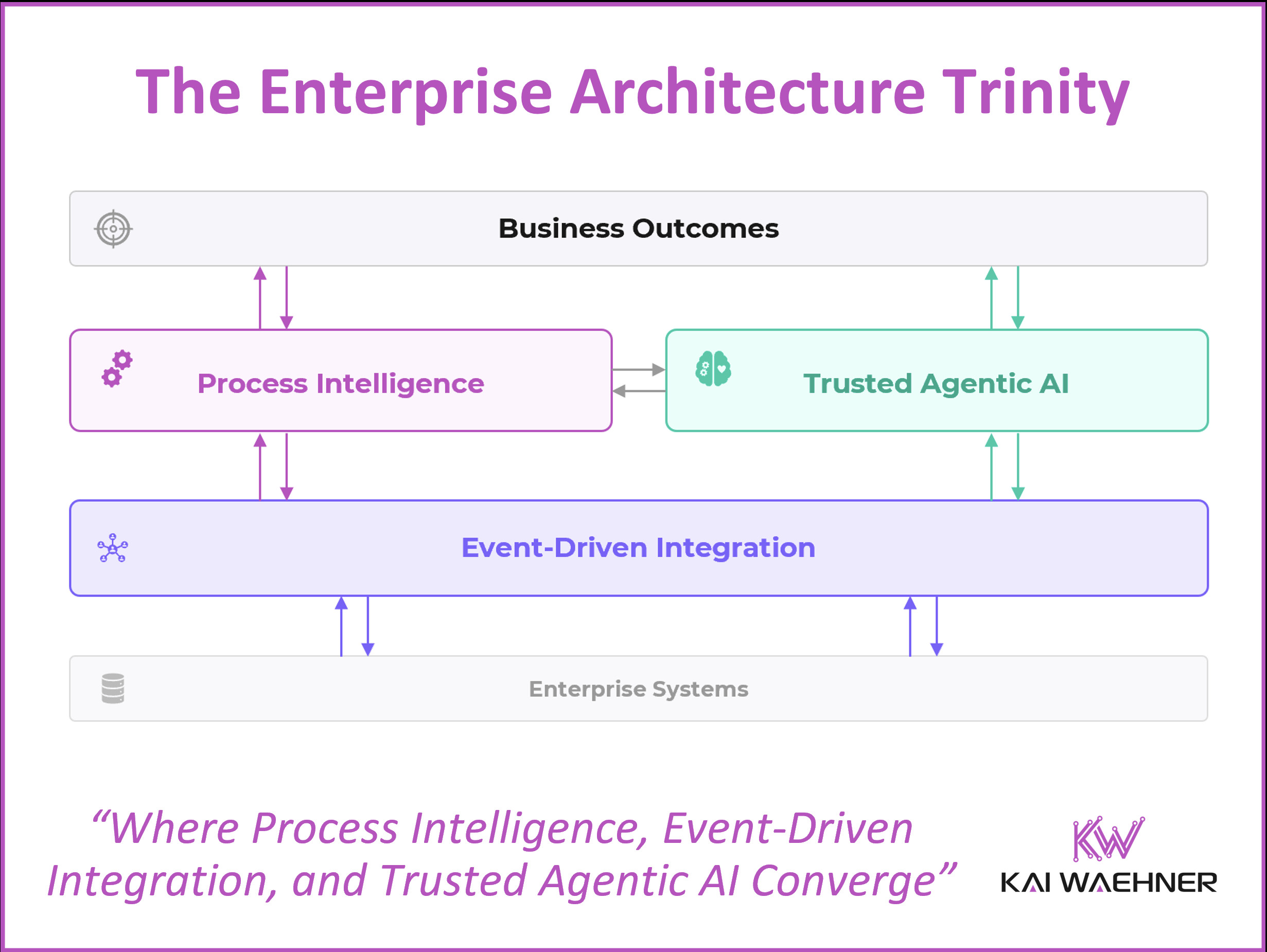
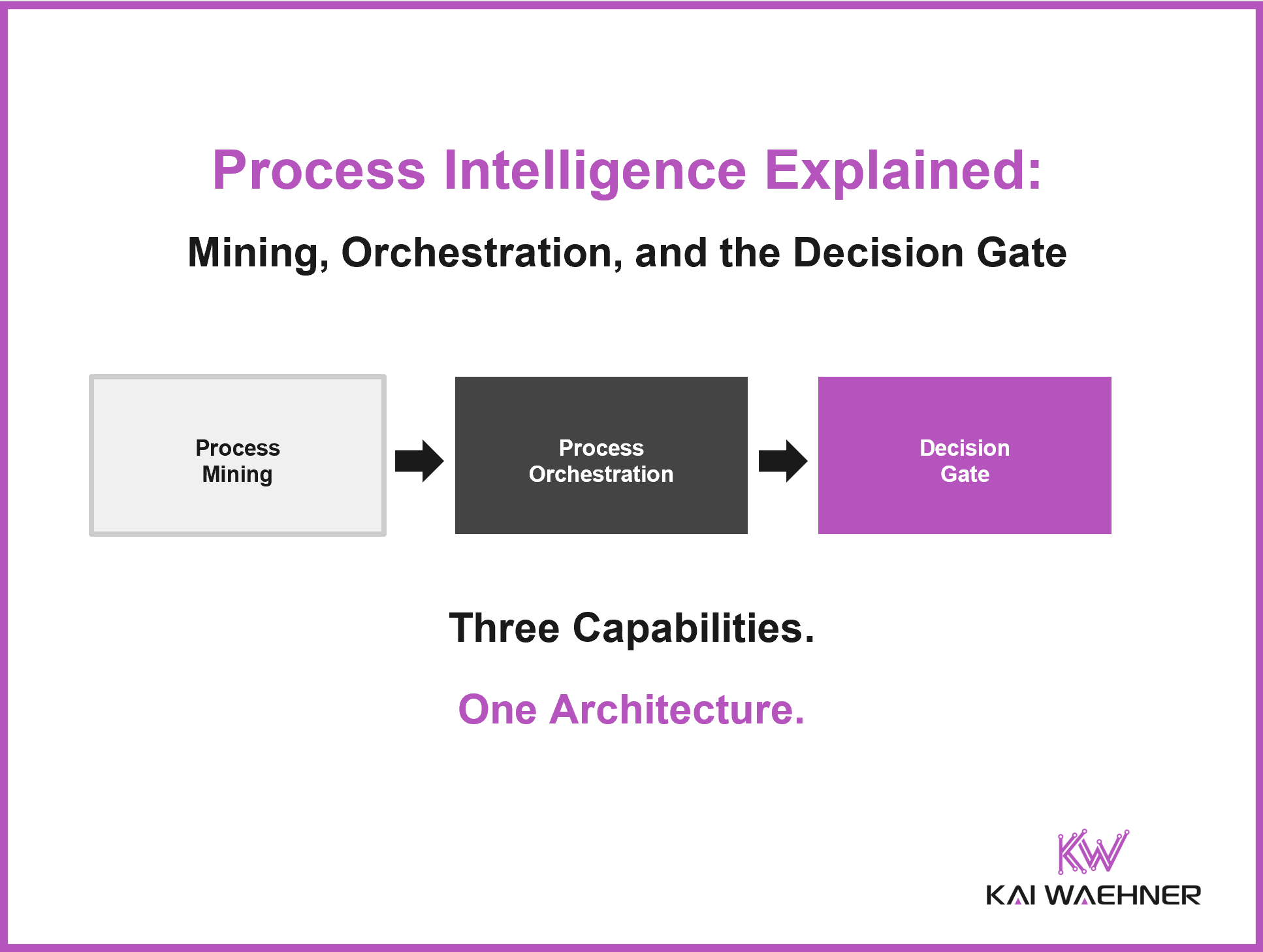
Agentic AI without governed processes is fast but ungoverned. Event-driven integration without process intelligence moves data but not decisions. Process intelligence without live data automates
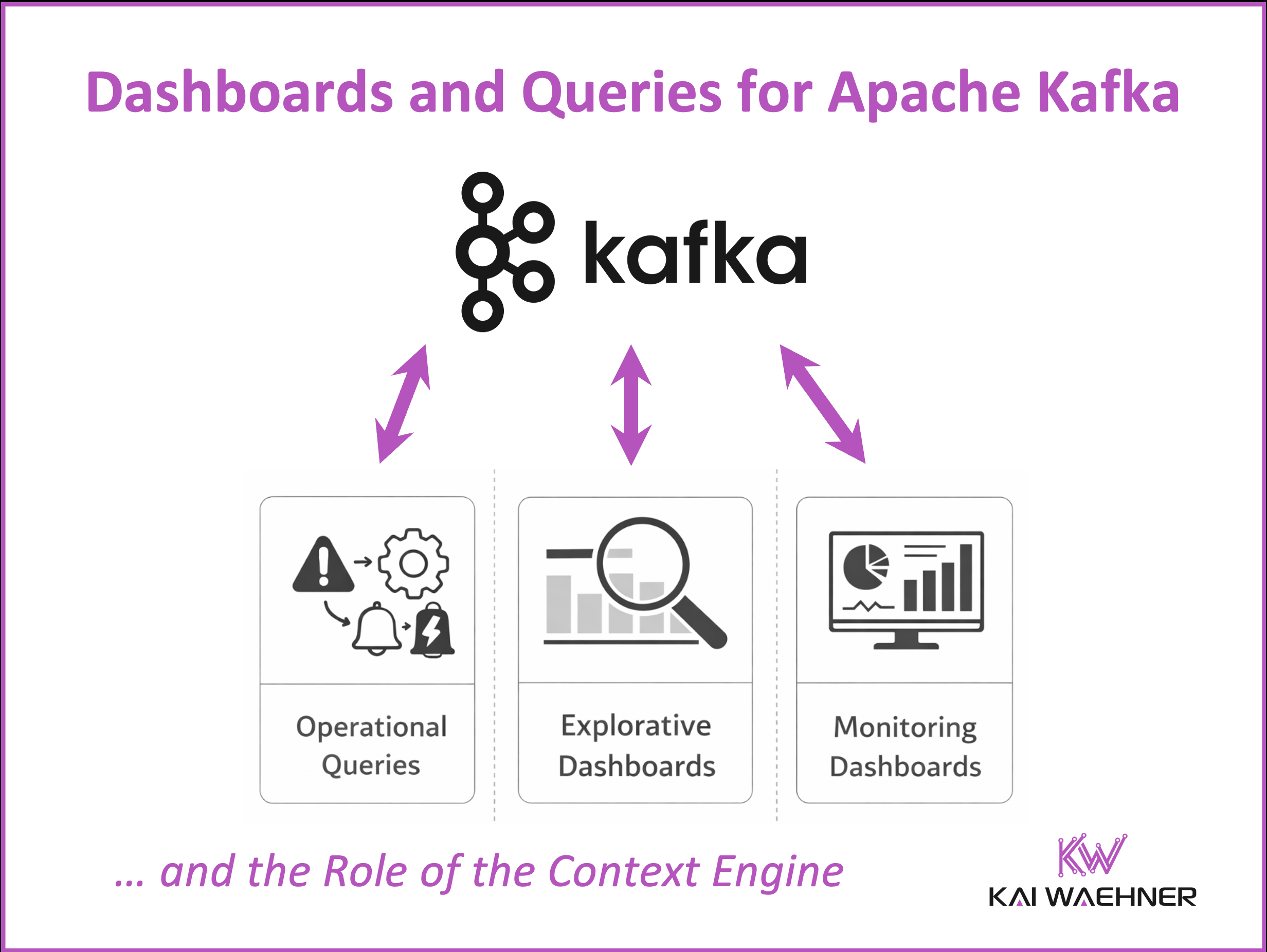
Dashboards are a popular way to make streaming data visible and useful, but they are not always the right solution. This blog post explains when

The second edition of The Ultimate Data Streaming Guide is now available as a free eBook. It includes over 70 use cases, over 20 customer
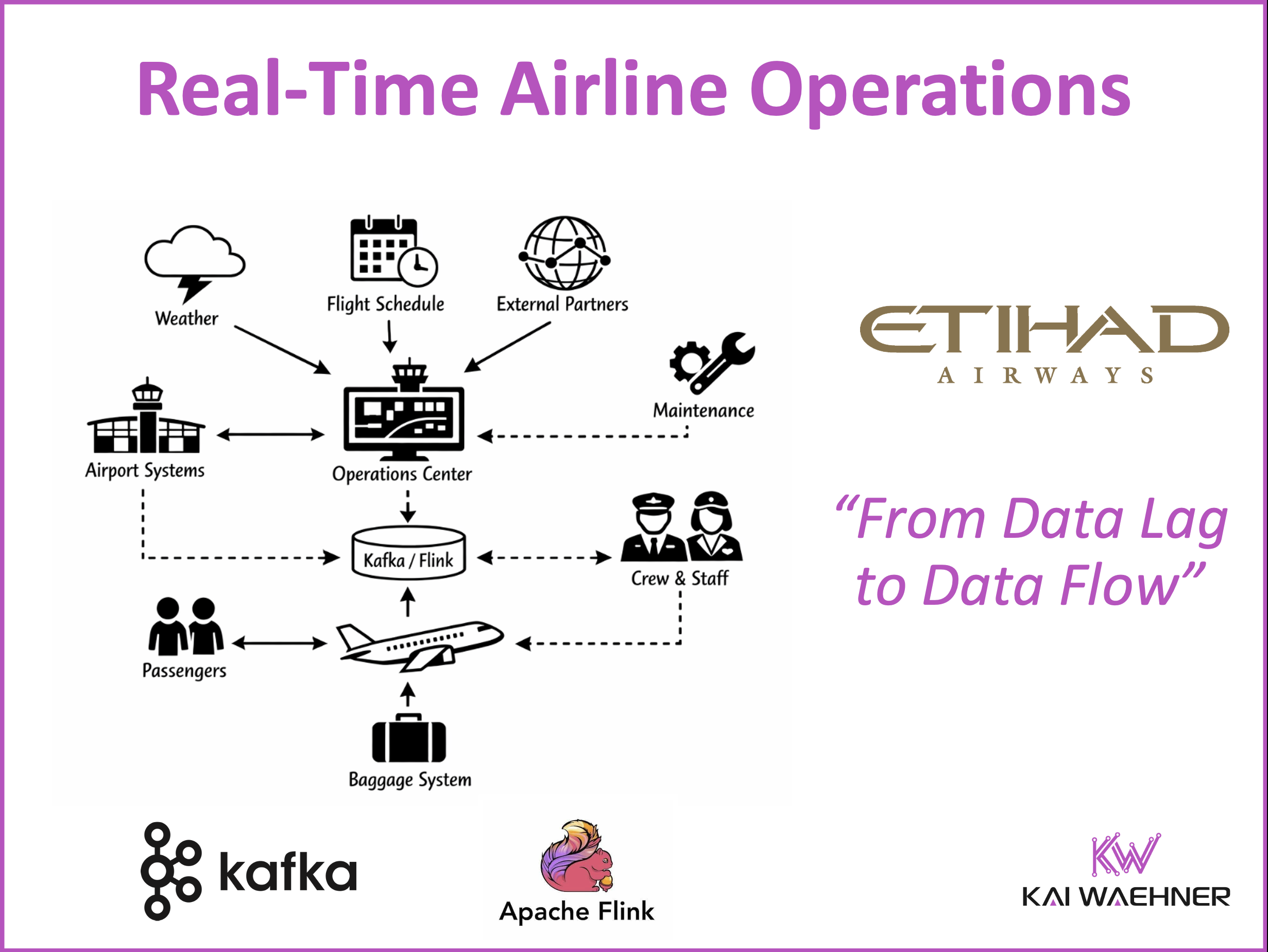
Airlines face constant pressure to deliver reliable service while managing complex operations and rising customer expectations. This blog post explores how Etihad Airways uses real-time
Financial services companies are moving from batch processing to real time data flow. A data streaming platform enables financial institutions to connect systems, process events

Each year brings new momentum to the data streaming space. In 2026, six key trends stand out. Platforms and vendors are consolidating. Diskless Kafka and
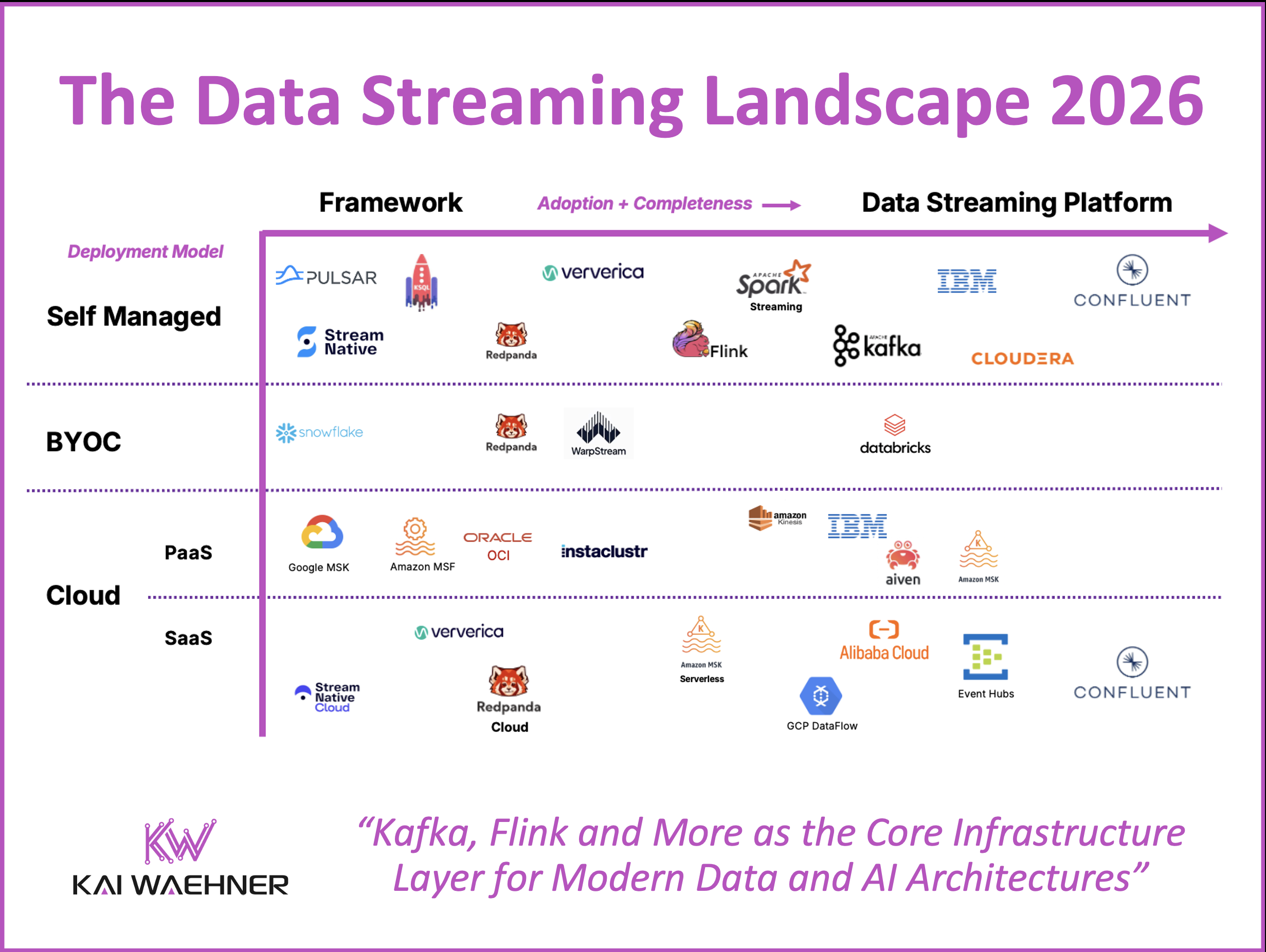
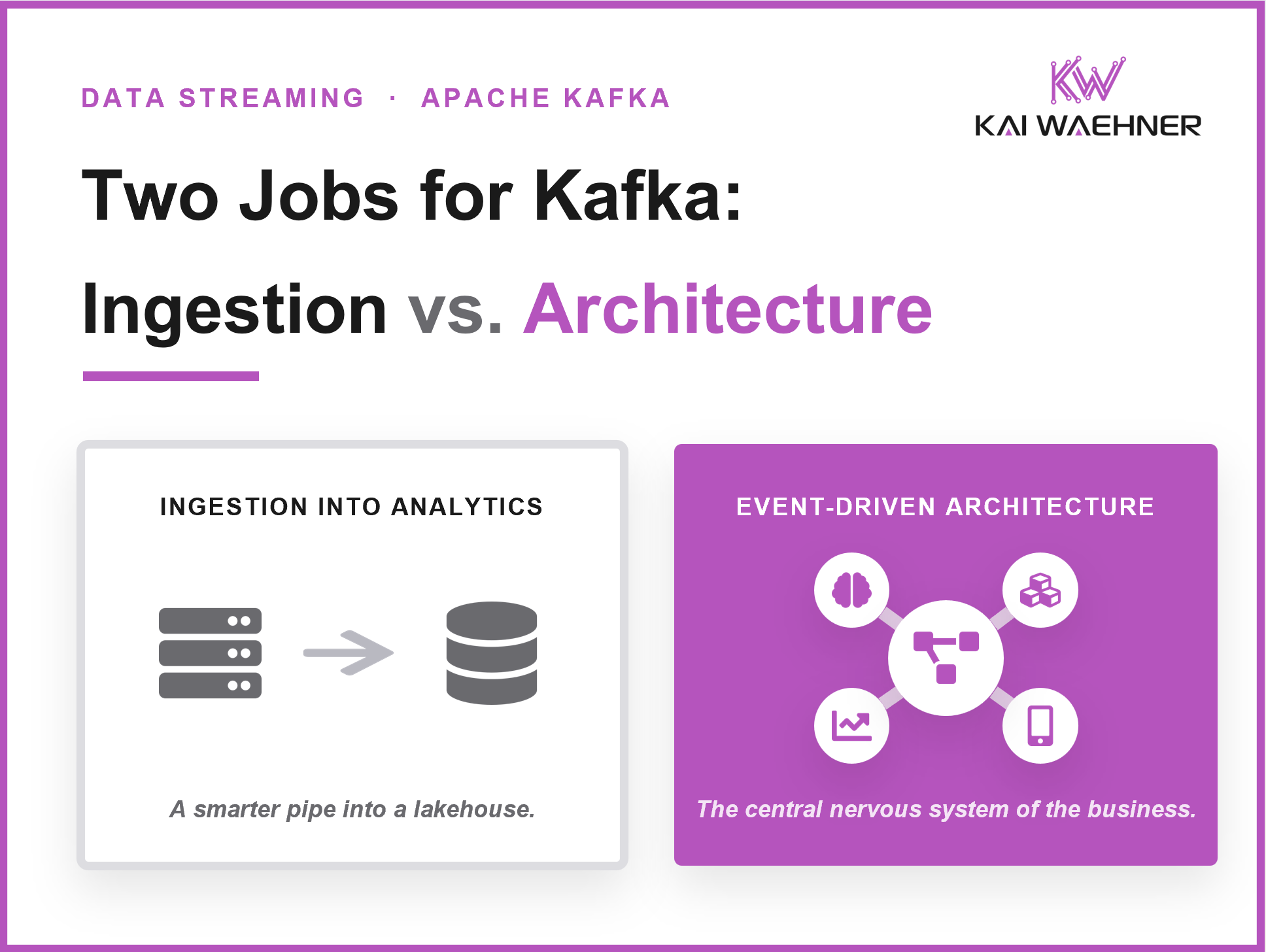
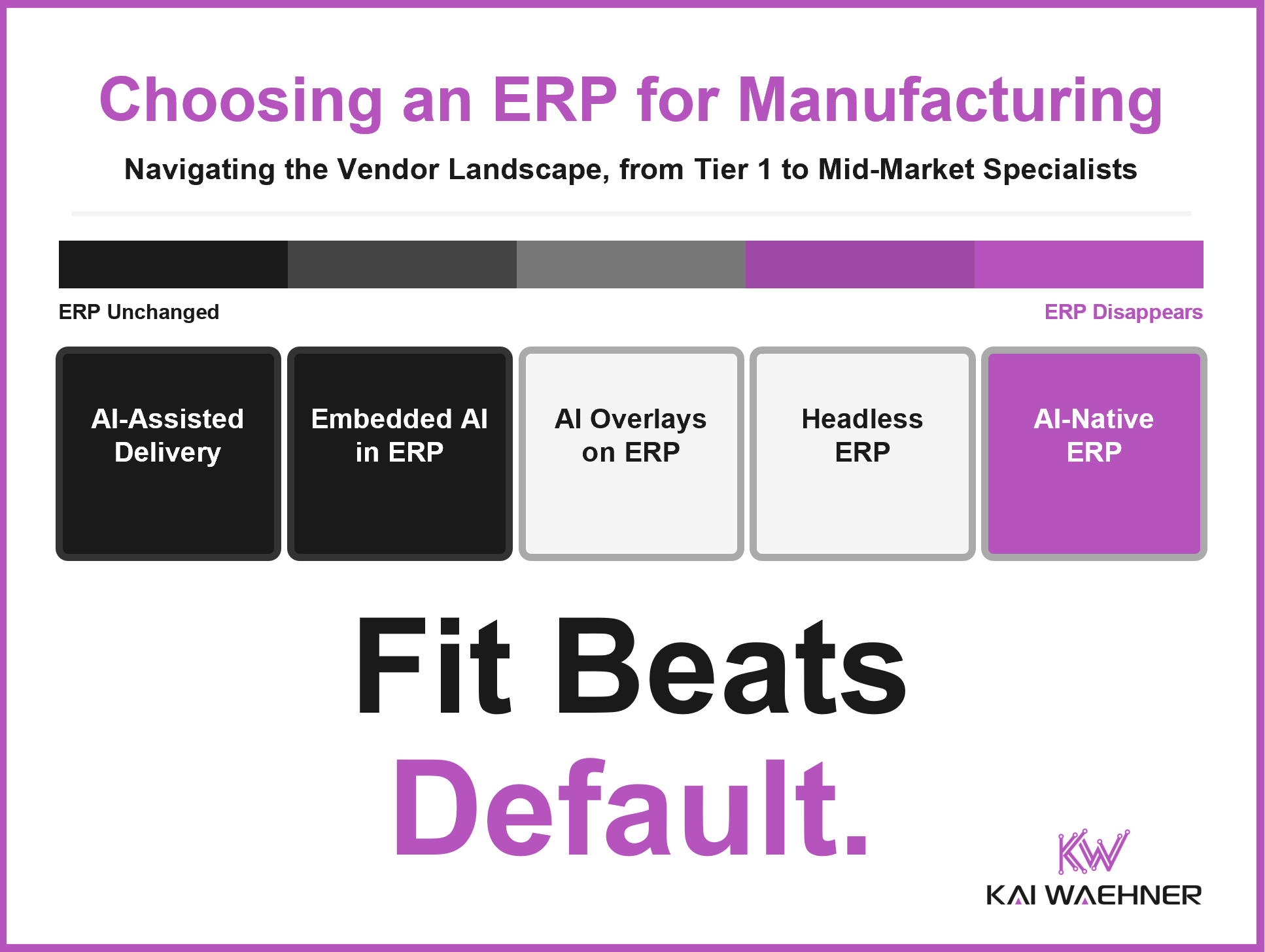
Data streaming is now a core software category in modern data architecture. It powers real-time use cases like fraud prevention, personalization, supply chain optimization, and

Social commerce is reshaping retail by merging entertainment, influencer marketing, and instant purchasing into one real-time experience. Platforms like TikTok and Instagram have become active


You need to load content from reCAPTCHA to submit the form. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Turnstile. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Vimeo. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from YouTube. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou need to load content from reCAPTCHA to submit the form. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Elfsight. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Facebook. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More Information