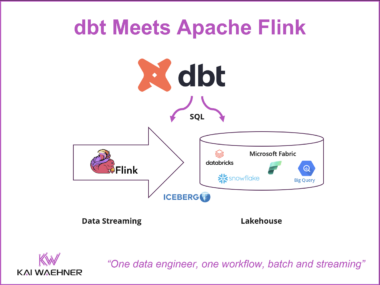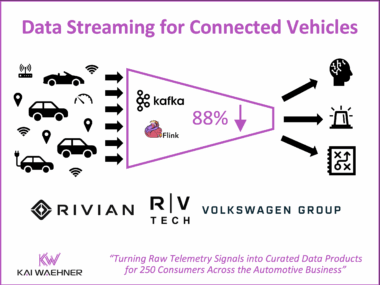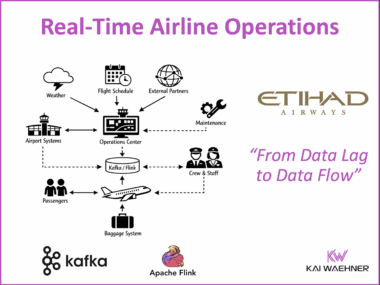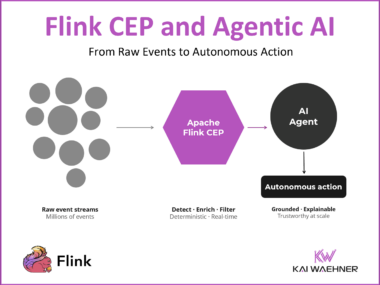
Flink CEP and Agentic AI: Real-Time Pattern Detection as the Foundation for Autonomous Decisions
AI agents fail in production when they are connected directly to raw event streams. Flink CEP is the missing layer between your data streams and your Agentic AI architecture: it detects meaningful event sequences in real time, reduces hundreds of thousands of raw events to a handful of grounded actionable signals, and makes every autonomous decision deterministic, auditable, and trustworthy enough for enterprise production.