5G
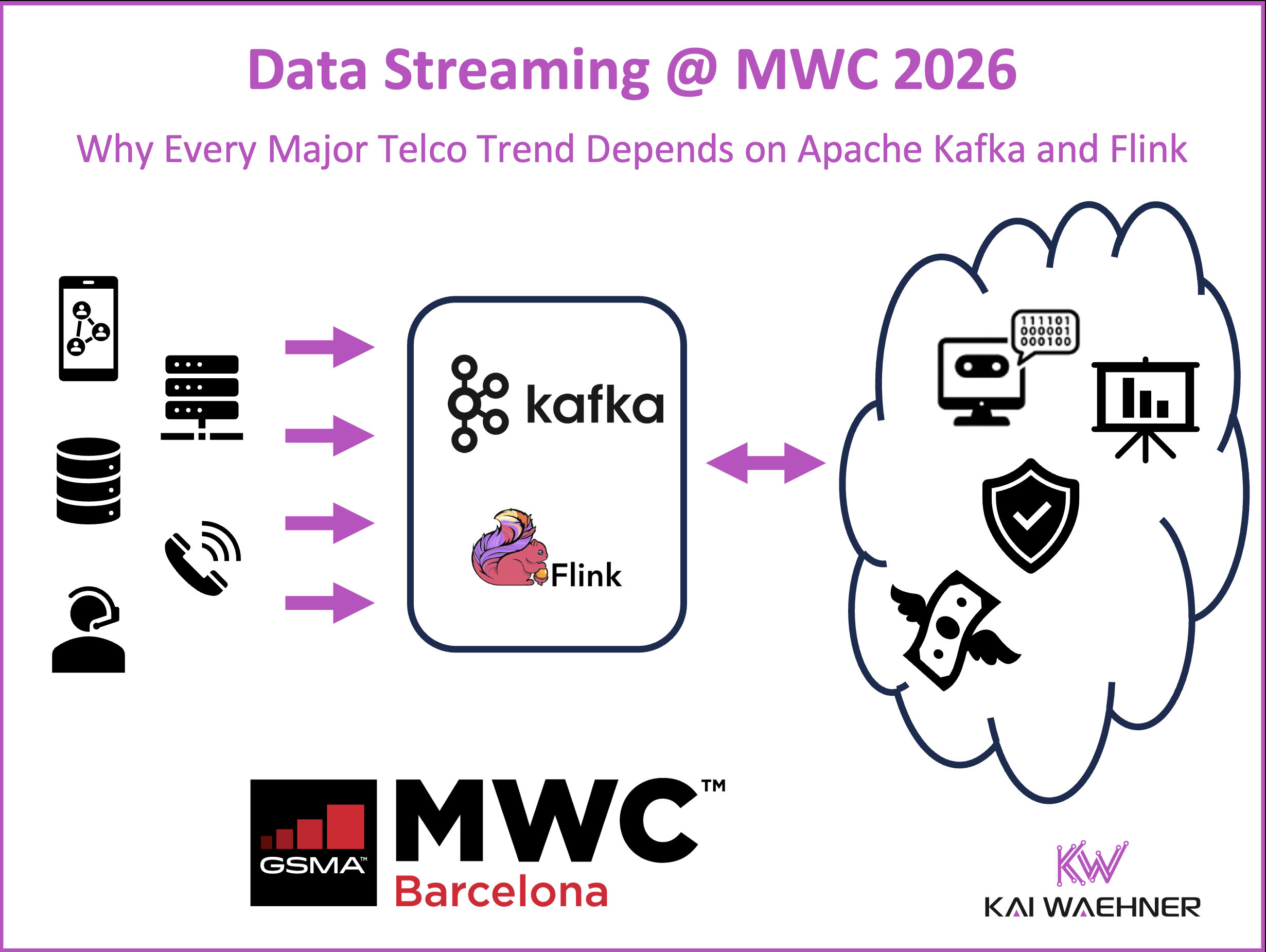
Mobile World Congress (MWC) 2026 highlights the shift from batch systems to real time data streaming in telecom. AI and agentic automation, network APIs, sovereign

Mobile World Congress (MWC) 2026 highlights the shift from batch systems to real time data streaming in telecom. AI and agentic automation, network APIs, sovereign

Cyberattacks on critical infrastructure and manufacturing are growing, with ransomware and manipulated sensor data creating severe risks. Digital twins combined with data streaming provide real-time

AI and autonomous networks took center stage at TM Forum Innovate Americas 2025 in Dallas. Leaders from AT&T, Verizon, and other telcos showed how large-scale
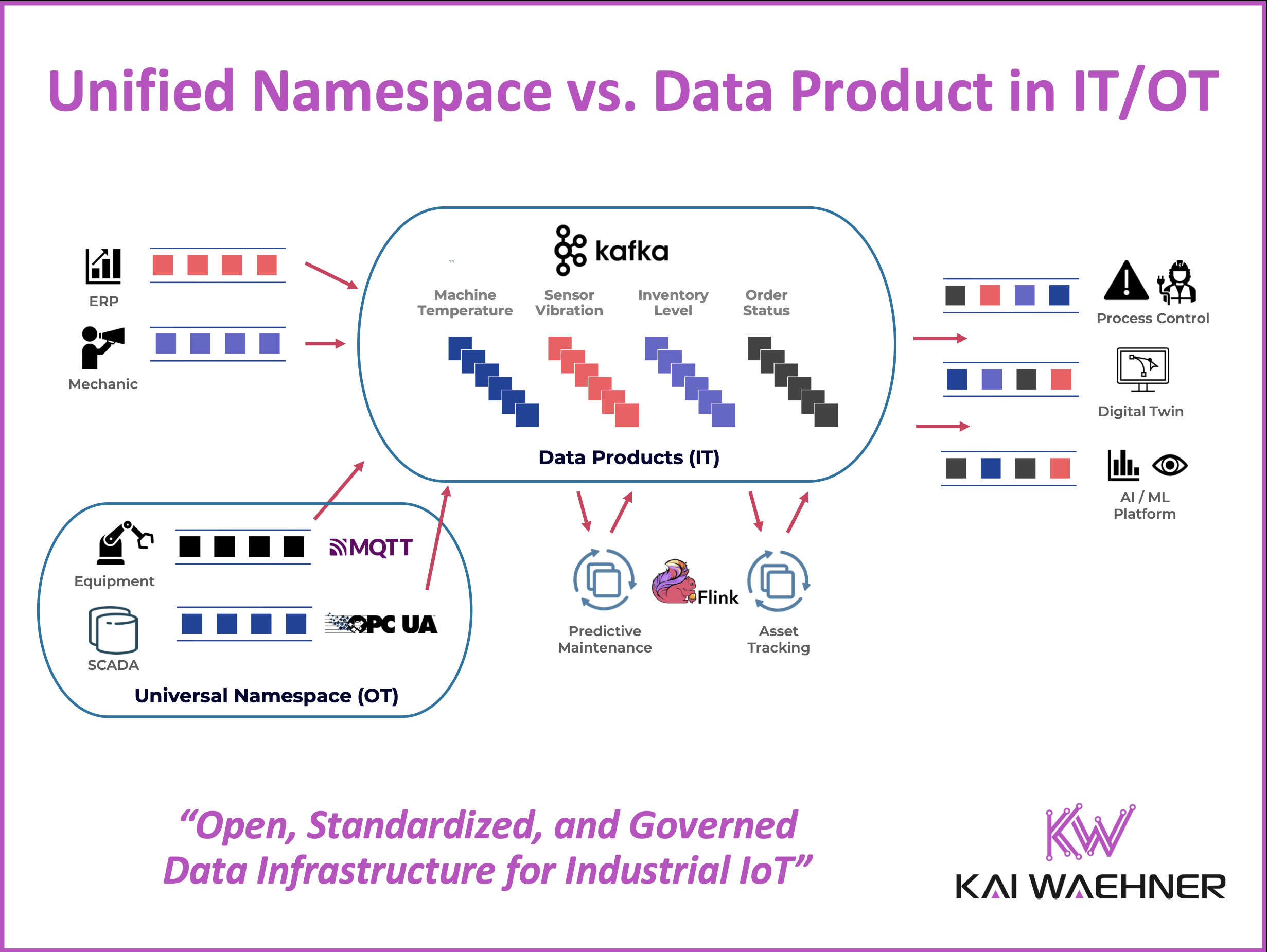
Industrial companies are connecting machines, sensors, and enterprise systems like never before. Real-time data, cloud-native platforms, and AI are driving this transformation—but only if silos
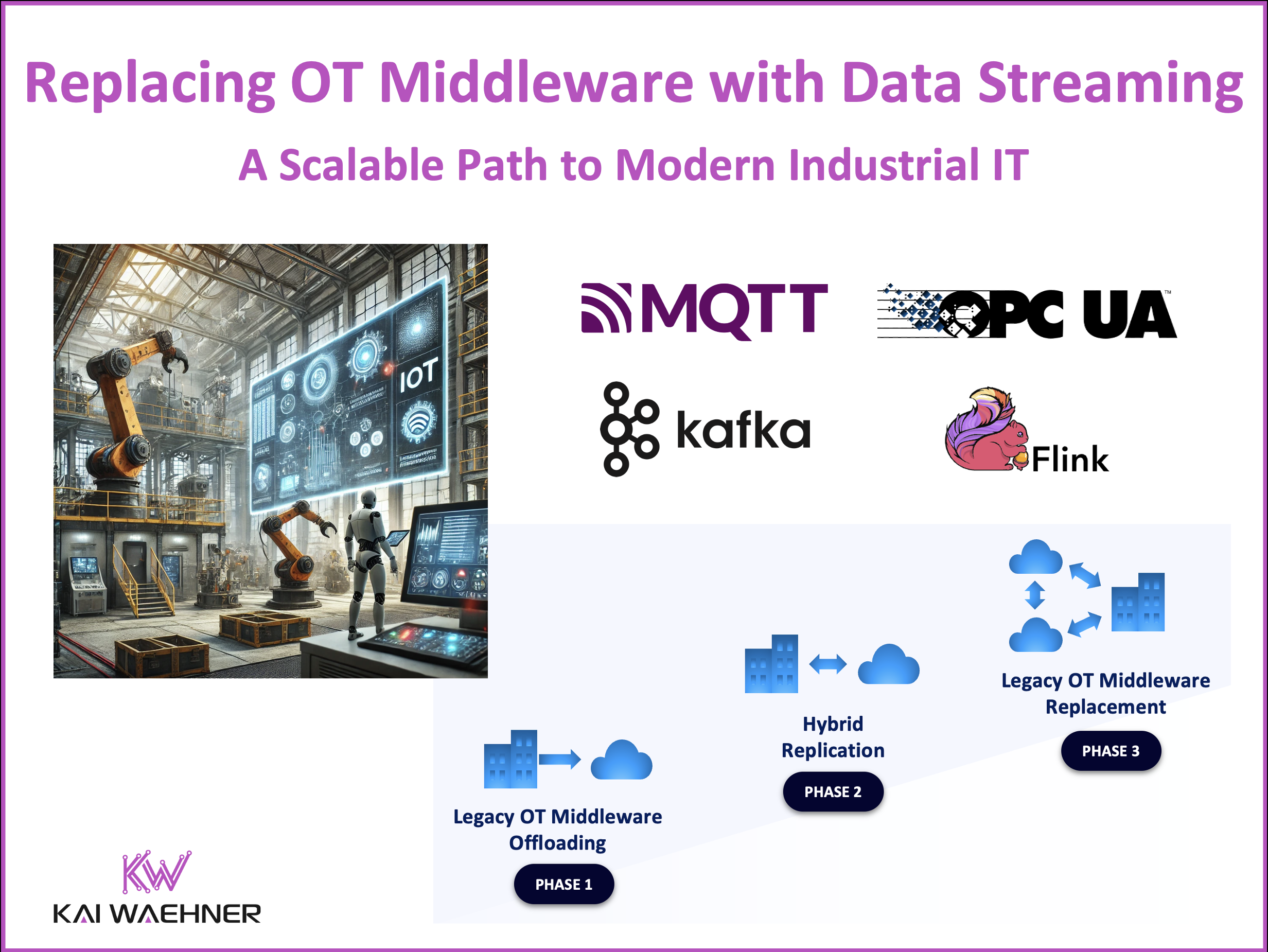
Legacy OT middleware is struggling to keep up with real-time, scalable, and cloud-native demands. As industries shift toward event-driven architectures, companies are replacing vendor-locked, polling-based
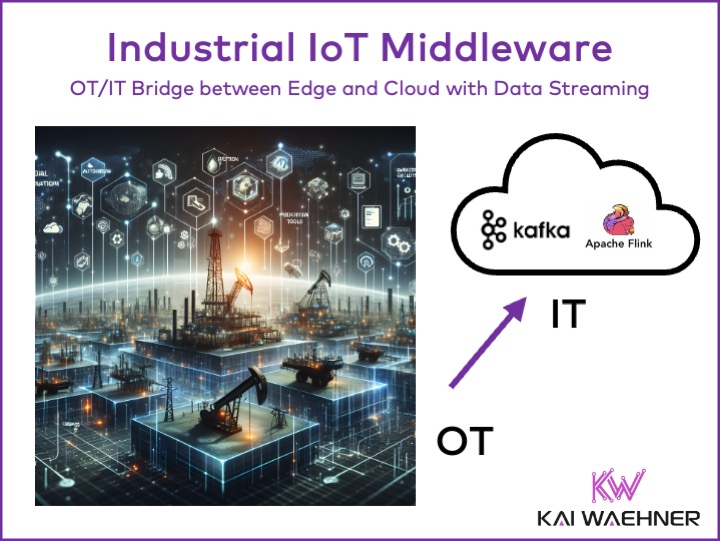
As industries continue to adopt digital transformation, the convergence of Operational Technology (OT) and Information Technology (IT) has become essential. The OT/IT Bridge is a

Organizations start their data streaming adoption with a single Apache Kafka cluster to deploy the first use cases. The need for group-wide data governance and

Energy trading and data streaming are connected because real-time data helps traders make better decisions in the fast-moving energy markets. This data includes things like
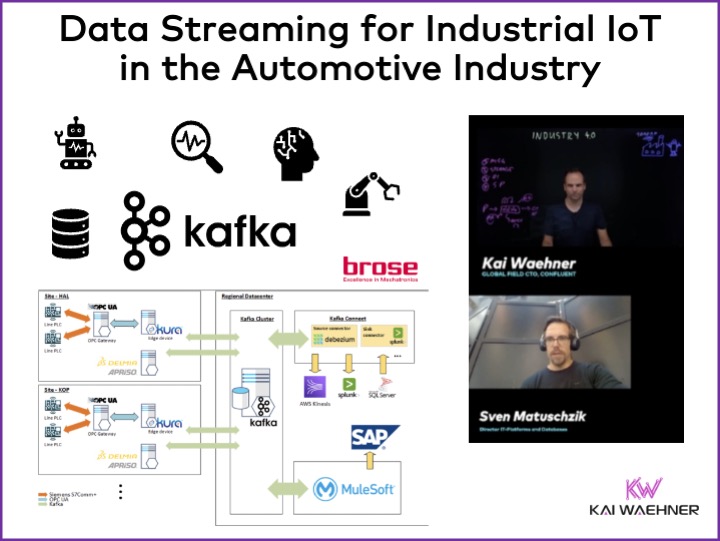
Data streaming unifies OT/IT workloads by connecting information from sensors, PLCs, robotics and other manufacturing systems at the edge with business applications and the big
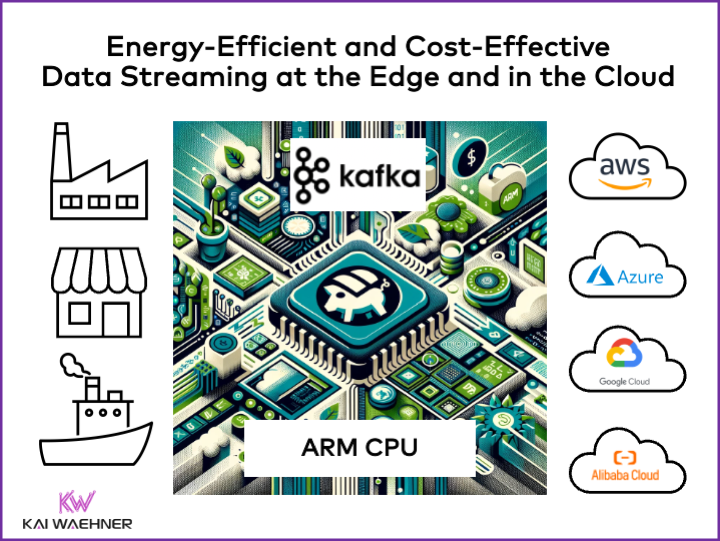
ARM CPUs often outperform x86 CPUs in scenarios requiring high energy efficiency and lower power consumption. These characteristics make ARM preferred for edge and cloud




You need to load content from reCAPTCHA to submit the form. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Turnstile. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Vimeo. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from YouTube. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou need to load content from reCAPTCHA to submit the form. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Elfsight. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Facebook. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More Information