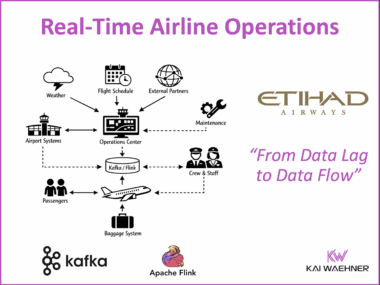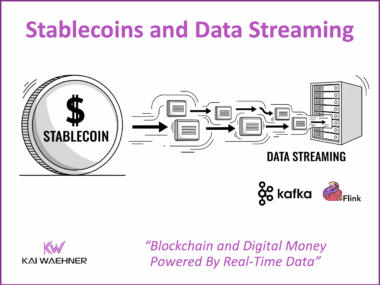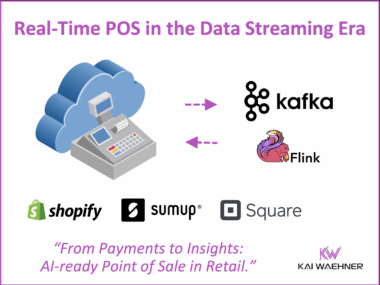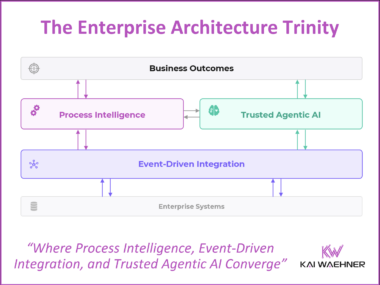
The Trinity of Modern Data Architecture: Process Intelligence, Event-Driven Integration, and Trusted Agentic AI
Agentic AI without governed processes is fast but ungoverned. Event-driven integration without process intelligence moves data but not decisions. Process intelligence without live data automates the wrong outcomes. The fix is a converged architecture. This post shows what that looks like.