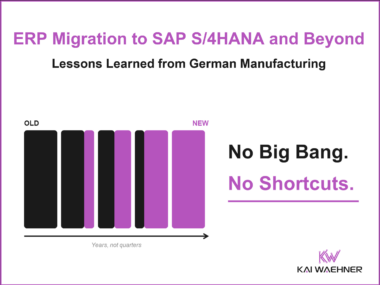
ERP Migration to SAP S/4HANA and Beyond: Lessons Learned from German Manufacturing
ERP modernization fails when the technology leads and the process work follows. Three German manufacturers ran their migrations differently, on SAP, ams.erp, and VlexPlus. The structural lessons are the same. This post covers what actually decides whether an ERP project lands.