
Apache Kafka
Nine years at Confluent: from a Silicon Valley startup with 100 people to an $11 billion IBM acquisition. A personal reflection on the Apache Kafka

Nine years at Confluent: from a Silicon Valley startup with 100 people to an $11 billion IBM acquisition. A personal reflection on the Apache Kafka
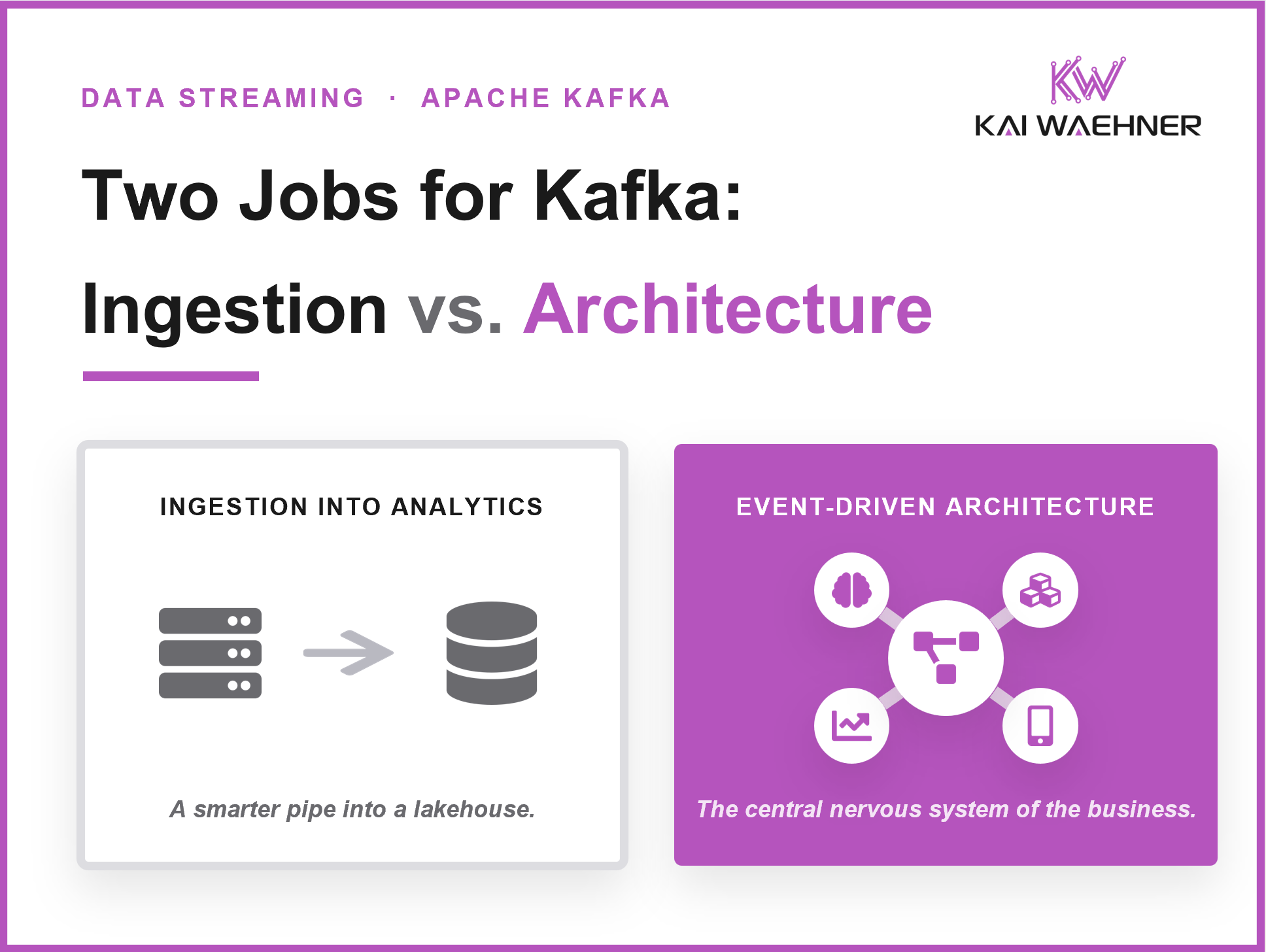
Databricks and Snowflake now speak the Kafka protocol. But using the Kafka API to feed a lakehouse is very different from running Kafka as the
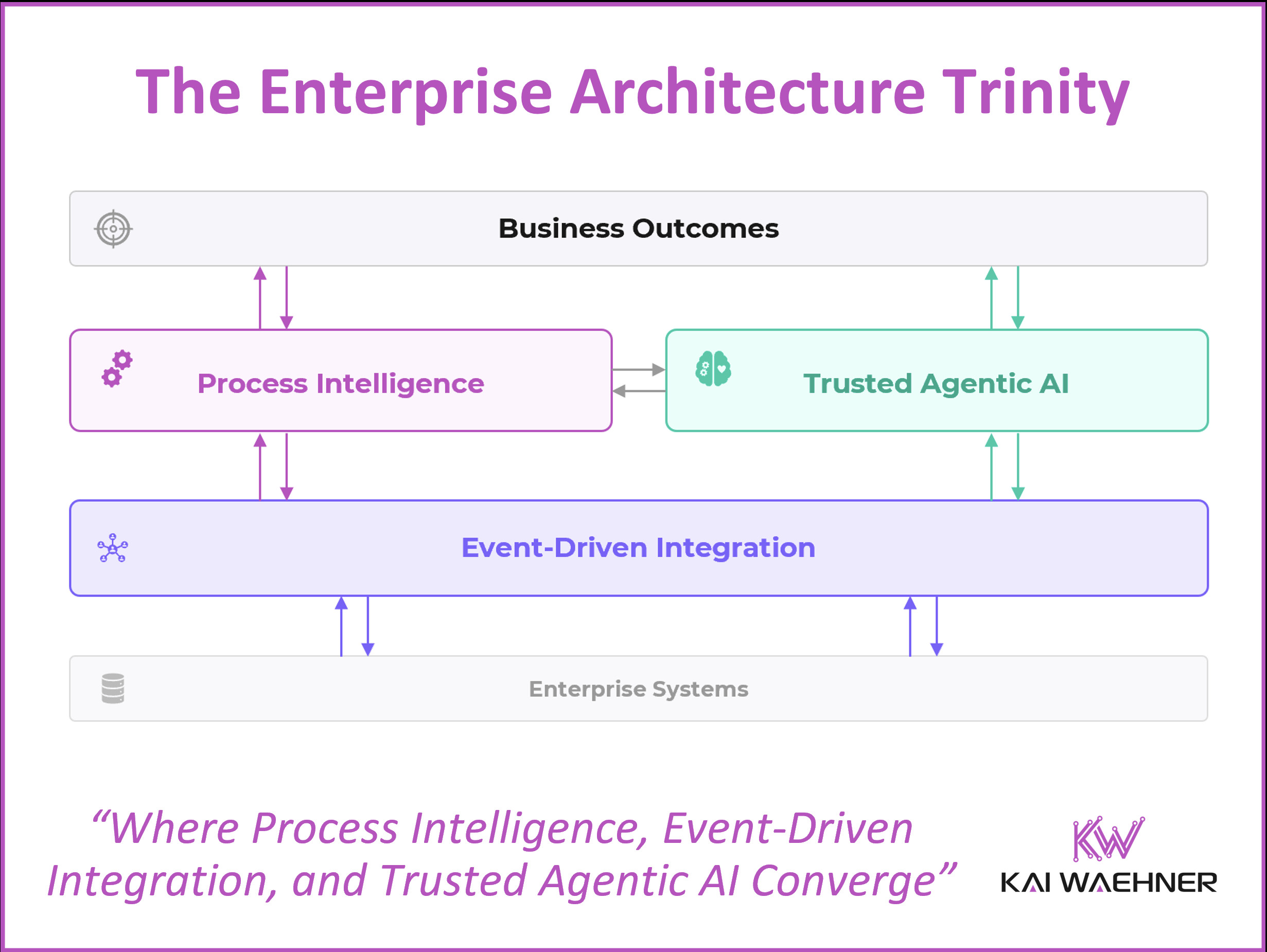
Agentic AI without governed processes is fast but ungoverned. Event-driven integration without process intelligence moves data but not decisions. Process intelligence without live data automates

A Kafka proxy adds centralized security and governance for Apache Kafka. Solutions like Kroxylicious, Conduktor, and Confluent enable encryption, access control, and compliance without modifying
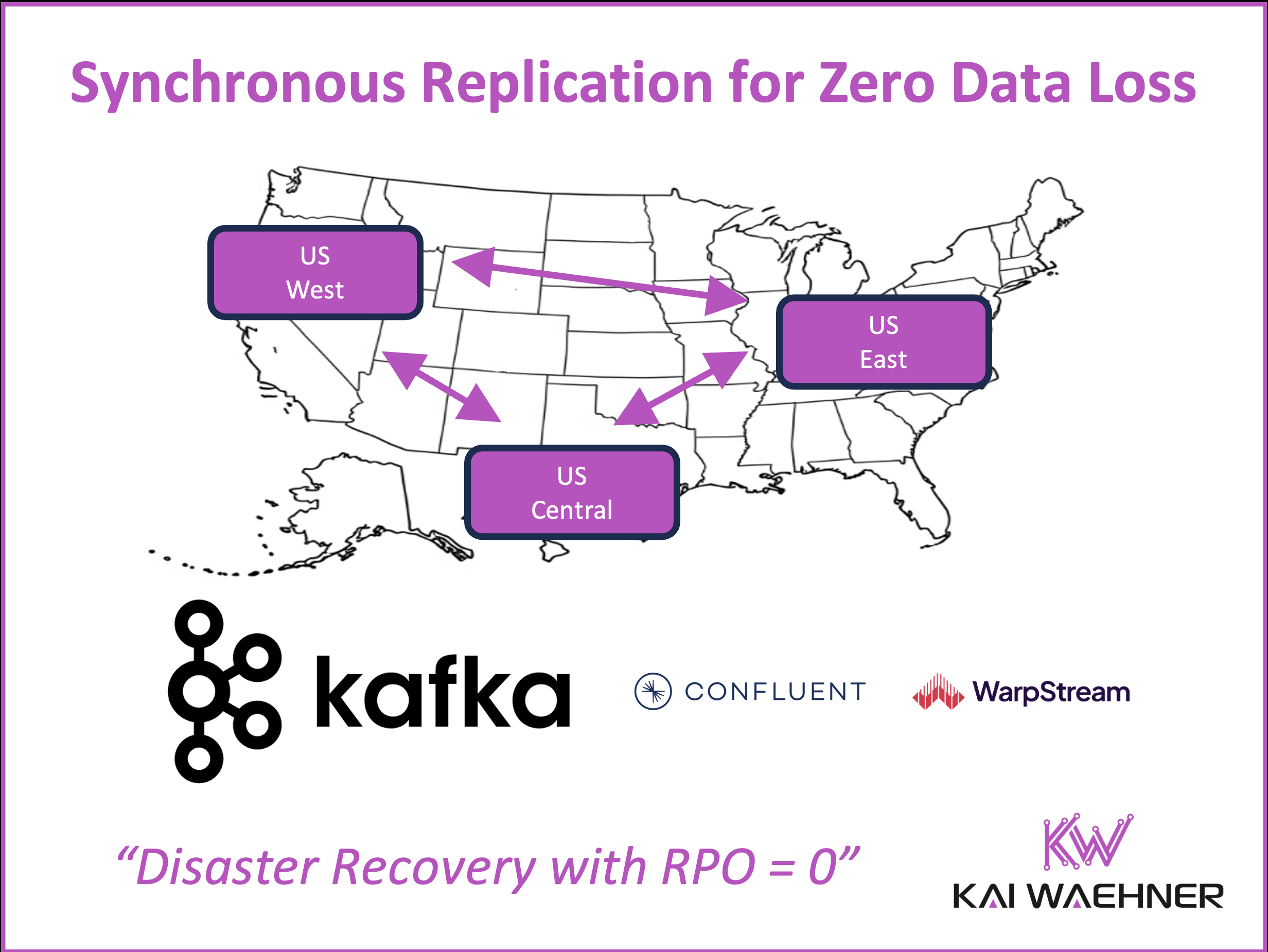
Apache Kafka is the backbone of real-time data streaming. Choosing the right deployment model – self-managed, fully managed, or bring-your-own-cloud (BYOC) – is a strategic

Open RAN is transforming telecom by decoupling hardware and software to unlock flexibility, innovation, and cost savings. But to fully realize its potential, telcos need
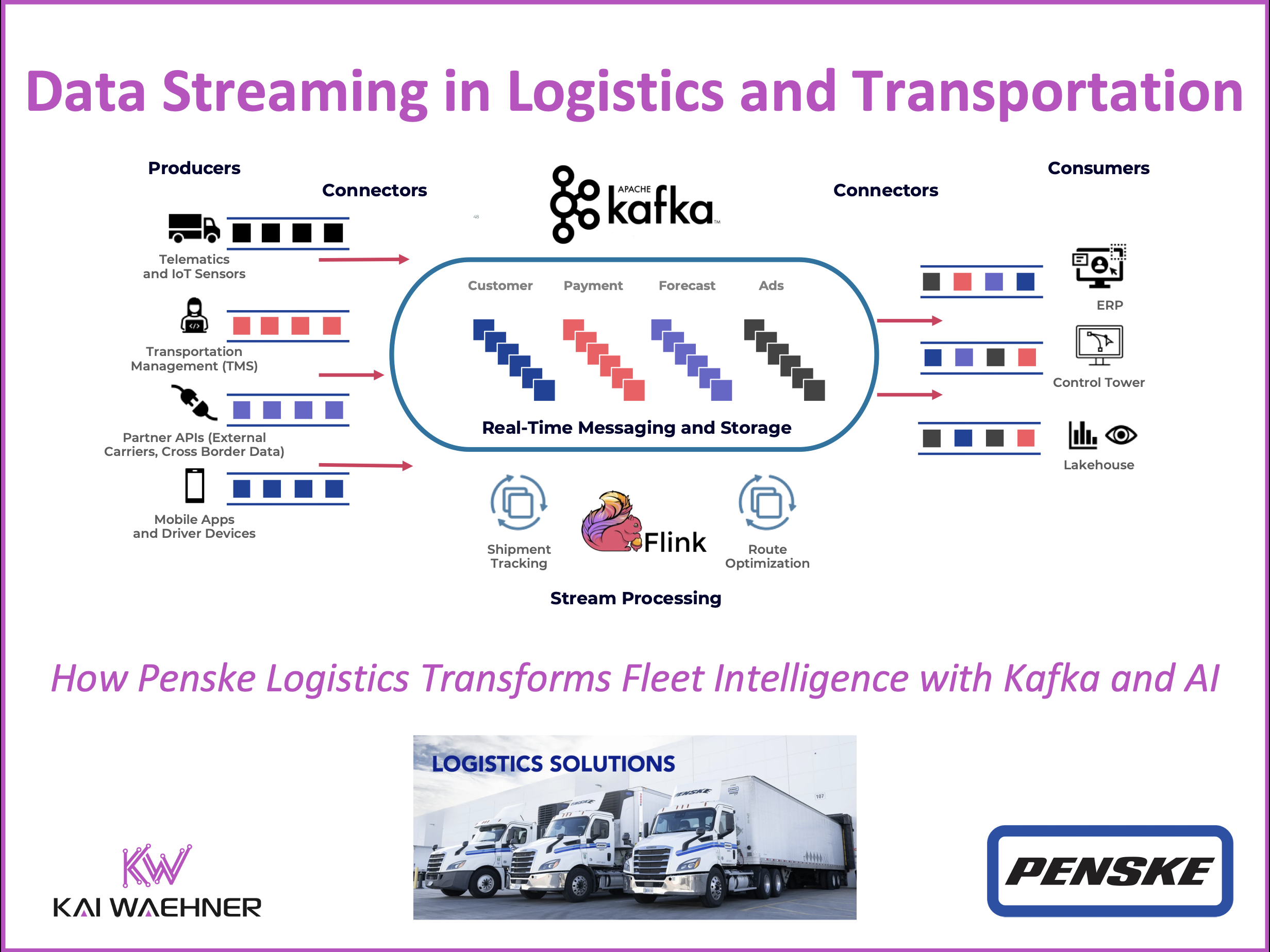
Real-time visibility has become essential in logistics. As supply chains grow more complex, providers must shift from delayed, batch-based systems to event-driven architectures. Data Streaming

Modernizing legacy systems doesn’t have to mean a risky big-bang rewrite. This blog explores how the Strangler Fig Pattern, when combined with data streaming, enables

A B2B data marketplace empowers businesses to exchange, monetize, and leverage real-time data through self-service platforms featuring subscription management, usage-based billing, and secure data sharing.

The cloud revolution has reshaped how businesses deploy and manage data streaming with solutions like Apache Kafka and Flink. Distinctions between SaaS and PaaS models




You need to load content from reCAPTCHA to submit the form. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Turnstile. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Vimeo. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from YouTube. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou need to load content from reCAPTCHA to submit the form. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Elfsight. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Facebook. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More Information