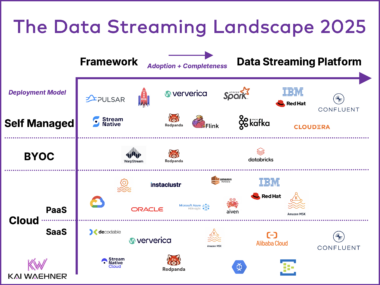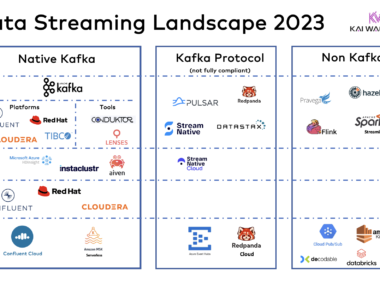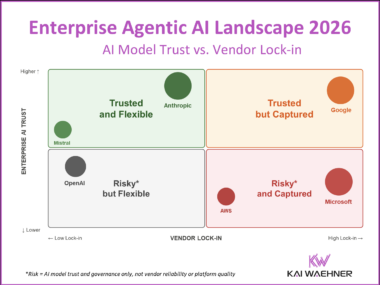
Enterprise Agentic AI Landscape 2026: Trust, Flexibility, and Vendor Lock-in
The Enterprise Agentic AI Landscape 2026 maps every major AI vendor across two dimensions that matter most: how much you trust their AI, and how much lock-in you accept. An independent, vendor-neutral analysis covering Anthropic, OpenAI, Google, Microsoft, AWS, Mistral, SAP, Salesforce, and more.