
Apache Kafka
The concepts and architectures of a data warehouse, a data lake, and data streaming are complementary to solving business problems. Unfortunately, the underlying technologies are

The concepts and architectures of a data warehouse, a data lake, and data streaming are complementary to solving business problems. Unfortunately, the underlying technologies are

IT modernization and innovative new technologies change the healthcare industry significantly. This blog series explores how data streaming with Apache Kafka enables real-time data processing
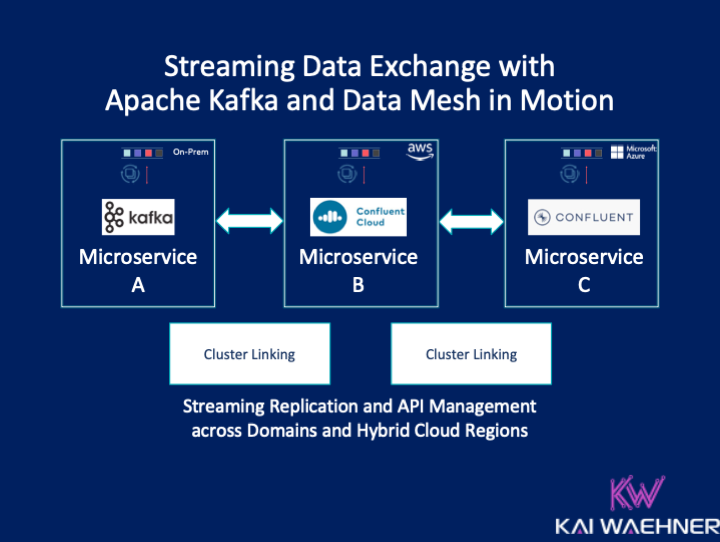
Data Mesh is a new architecture paradigm that gets a lot of buzzes these days. This blog post looks into this principle deeper to explore




You need to load content from reCAPTCHA to submit the form. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Turnstile. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Vimeo. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from YouTube. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou need to load content from reCAPTCHA to submit the form. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Elfsight. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Facebook. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More Information