Data Mesh is a new architecture paradigm that gets a lot of buzzes these days. Every data and platform vendor describes how to build the best Data Mesh with their platform. The Data Mesh story includes cloud providers like AWS, data analytics vendors like Databricks and Snowflake, and Event Streaming solutions like Confluent. This blog post looks into this principle deeper to explore why no single technology is the perfect fit to build a Data Mesh. Examples show why an open and scalable decentralized real-time platform like Apache Kafka is often the heart of the Data Mesh infrastructure, complemented by many other data platforms, to solve business problems.
Data at Rest vs. Data in Motion
Before we get into the Data Mesh discussion, it is crucial to clarify the difference and relevance of Data at Rest and Data in Motion:
- Data at Rest: Data is ingested and stored in a storage system (database, data warehouse, data lake). Business logic and queries execute against the storage. Everyday use cases include reporting with business intelligence tools, model training in machine learning, and complex batch analytics like shuffling or map and reduce. As the data is at rest, the processing is too late for real-time use cases.
- Data in Motion: Data is processed and correlated continuously while new events are fed into the platform. Business logic and queries execute in real-time. Common real-time use cases include inventory management, order processing, fraud detection, predictive maintenance, and many other use cases.
Real-time Data Beats Slow Data
Real-time beats slow data in almost all use cases across industries. Hence, ask yourself or your business team how they want or need to consume and process the data in the next project. Data at Rest and Data in Motion have trade-offs. Therefore, both concepts are complementary. For this reason, modern cloud infrastructures leverage both in their architecture. Serverless Event Streaming with Kafka combined with the AWS Lakehouse is a great resource to learn more.
However, while connecting a batch system to a real-time nervous system is possible, the other way round – connecting a real-time consumer to batch storage – is not possible. The Kappa vs. Lambda Architecture discussion gives more insights into this.
Kafka is a database. So, it is also possible to use it for data at rest. For instance, the replayability of historical events in guaranteed ordering is essential and helpful for many use cases. However, long-term storage in Kafka has several limitations, like limited query capabilities. Hence, for many use cases, event streaming and other storage systems are complementary, not competitive.
Data Mesh – An Architecture Paradigm
Data mesh is an implementation pattern (not unlike microservices or domain-driven design) but applied to data. Thoughtworks coined the term. You will find tons of resources on the web. Zhamak Dehghani gave a great introduction about “How to build the Data Mesh Foundation and its Relation to Event Streaming” at the Kafka Summit Europe 2021.
Domain-driven + Microservices + Event Streaming
Data Mesh is not an entirely new paradigm. It has several historical influences:
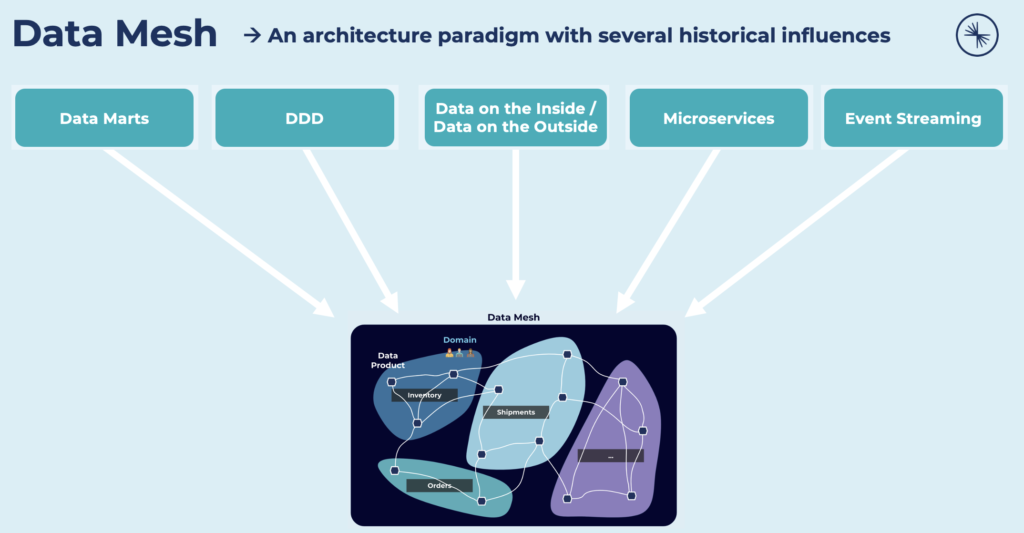
The architectural paradigm unlocks analytical data at scale, rapidly unlocking access to an ever-growing number of distributed domain data sets for a proliferation of consumption scenarios such as machine learning, analytics, or data-intensive applications across the organization. A data mesh addresses the common failure modes of the traditional centralized data lake or data platform architecture.
Data Mesh is a Logical View, not Physical!
Data mesh shifts to a paradigm that draws from modern distributed architecture: considering domains as the first-class concern, applying platform thinking to create a self-serve data infrastructure, treating data as a product, and implementing open standardization to enable an ecosystem of interoperable distributed data products.
Here is an example of a Data Mesh:
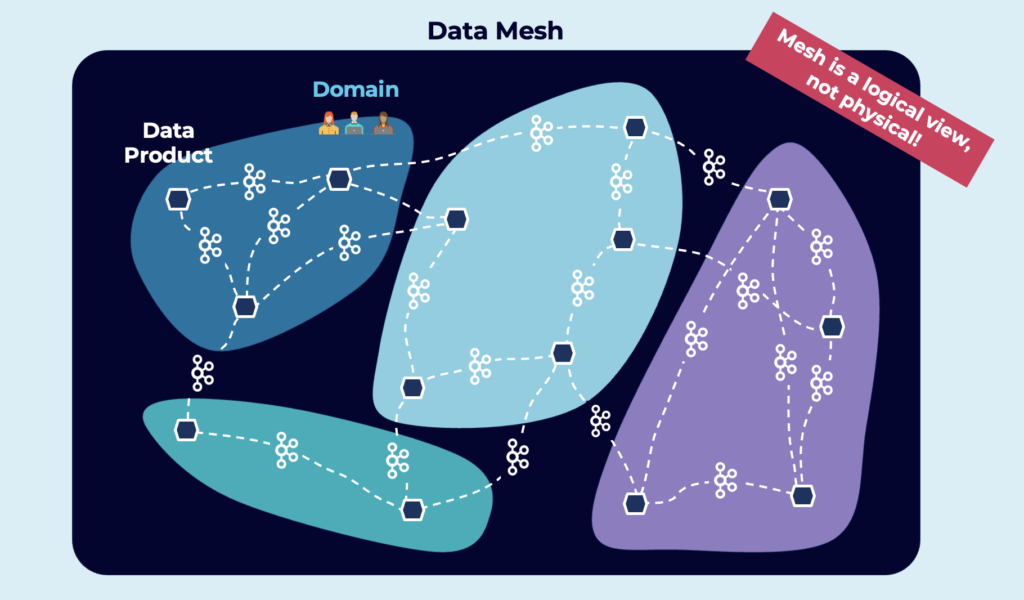
TL;DR: Data Mesh combines existing paradigms, including Domain-driven Design, Data Marts, Microservices, and Event Streaming.
Data as the Product
However, the differentiating aspect focuses on product thinking (“Microservice for Data”) with data as a first-class product. Data products are a perfect fit for Event Streaming with Data in Motion to build innovative new real-time use cases.
A Data Mesh with Event Streaming
Why is Event Streaming a good fit for data mesh?
Streams are real-time, so you can propagate data throughout the mesh immediately, as soon as new information is available. Streams are also persisted and replayable, so they let you capture both real-time AND historical data with one infrastructure. And because they are immutable, they make for a great source of record, which is helpful for governance.
Data in Motion is crucial for most innovative use cases. And as discussed before, real-time data beats slow data in almost all scenarios. Hence, it makes sense that the heart of a Data Mesh architecture is an Event Streaming platform. It provides true decoupling, scalable real-time data processing, and highly reliable operations across the edge, data center, and multi-cloud.
Kafka Streaming API – The De Facto Standard for Data in Motion
The Kafka API is the de facto standard for Event Streaming. I won’t explore this discussion again and again. Here are a few references before we move to the “Kafka + Data Mesh” content…
- Why Kafka became a Standard API like Amazon S3
- Comparison of event streaming and Kafka vendors like Red Hat, Cloudera, Confluent, Amazon MSK
- Apache Kafka versus Apache Pulsar
A Kafka-powered Data Mesh
I highly recommend watching Ben Stopford’s and Michael Noll’s talk about “Apache Kafka and the Data Mesh“. Several of the screenshots in this post are from that presentation, too. Kudos to my two colleagues! The talk explores the key concepts of a Data Mesh and how they are related to Event Streaming:
- Domain-driven Decentralization
- Data as a Self-serve Product
- First-class Data Platform
- Federated Governance
Let’s now explore how Event Streaming with Kafka fits into the Data Mesh architecture and how other solutions like a database or data lake complement it.
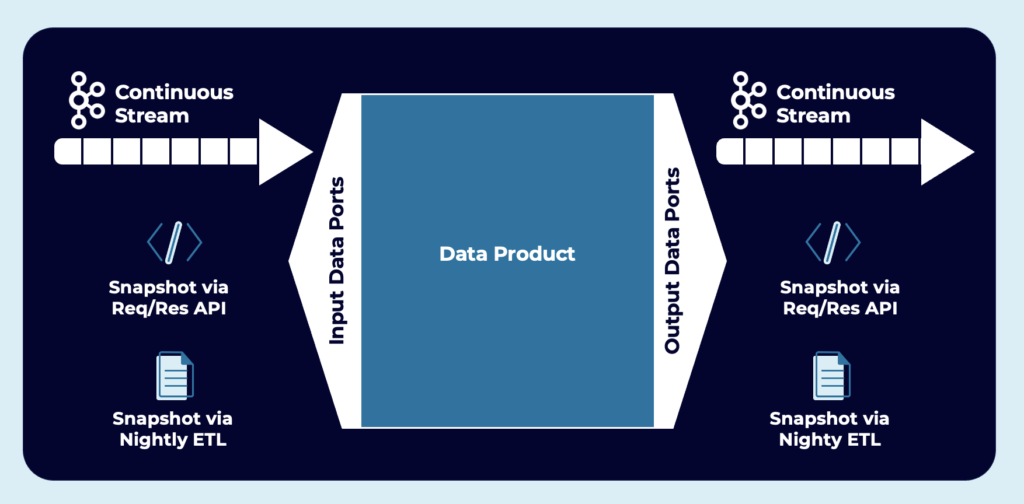
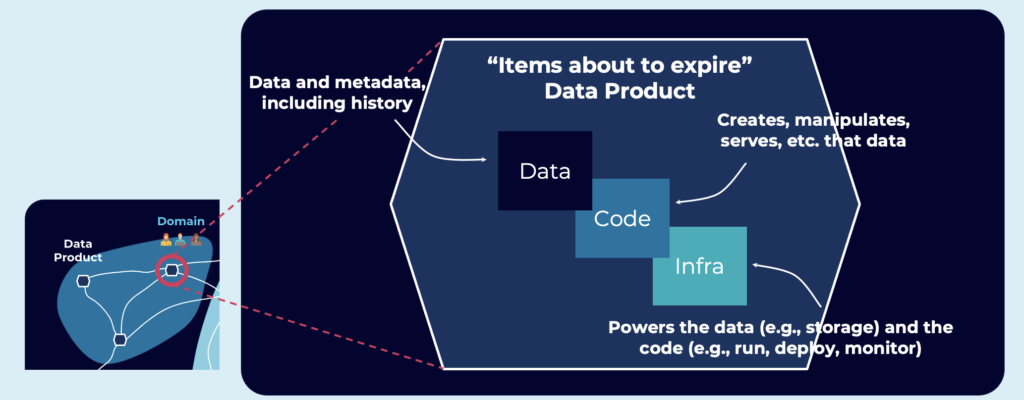
Data product, a “microservice for the data world”:
- A node on the data mesh, situated within a domain.
- Produces and possibly consumes high-quality data within the mesh.
- Encapsulates all the elements required for its function, namely data plus code plus infrastructure.
A Data Mesh is not just one Technology!
The heart of a Data Mesh infrastructure must be real-time, decoupled, reliable, and scalable. Kafka is a modern cloud-native enterprise integration platform (also often called iPaaS today). Therefore, Kafka provides all the capabilities for the foundation of a Data Mesh.
However, not all components can or should be Kafka-based. Choose the right tool for a problem. Let’s explore in the following subsections how Kafka-native technologies and other solutions are used in a Data Mesh together.
Stream Processing within the Data Product with Kafka Streams and ksqlDB
An event-based data product aggregates and correlates information from one or more data sources in real-time. Stateless and stateful stream processing is implemented with Kafka-native tools such as Kafka Streams or ksqlDB:
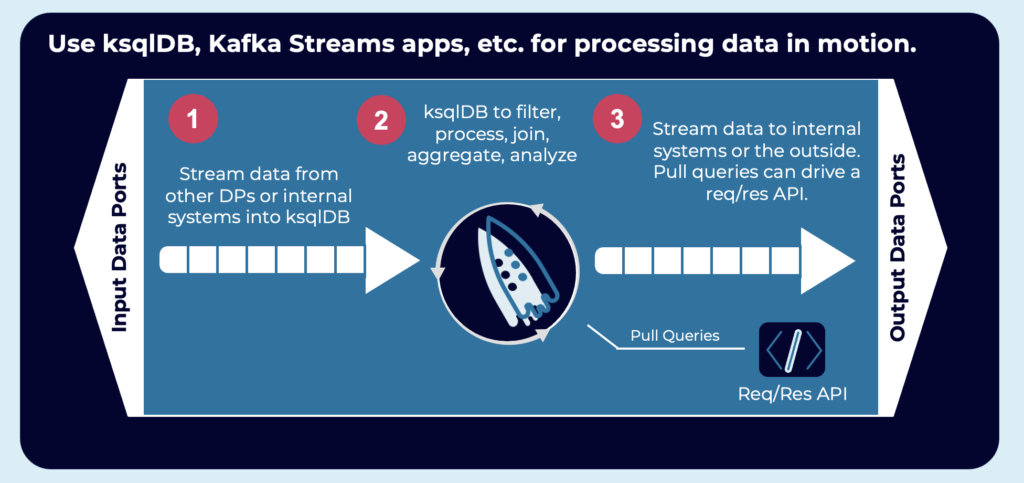
Variety of Protocols and Communication Paradigms within the Data Product – HTTP, gRPC, MQTT, and more
Obviously, not every application uses just Event Streaming as a technology and communication paradigm. The above picture shows how one consumer application could also be a request/response technology like HTTP or gRPC to do a pull query. In contrast, another application continuously consumes the streaming push query with a native Kafka consumer in any programming language, such as Java, Scala, C, C++, Python, Go, etc.
The data product often includes complementary technologies. For instance, if you built a connected car infrastructure, you likely use MQTT for the last-mile integration, ingest the data into Kafka, and further processing with Event Streaming. The “Kafka + MQTT Blog Series” is an excellent example from the IoT space to learn about building a data product with complementary technologies.
Variety of Solutions within the Data Product – Event Streaming, Data Warehouse, Data Lake, and more
The beauty of microservice architectures is that every application can choose the right technologies. An application might or might not include databases, analytics tools, or other complementary components. The input and output data ports of the data product should be independent of the chosen solutions:

Kafka Connect is the right Kafka-native technology to connect other technologies and communication paradigms with the Event Streaming platform. Evaluate if you need another integration middleware (like an ETL or ESB) or if the Kafka infrastructure is the better enterprise integration platform (iPaaS) for your data product within the data mesh.
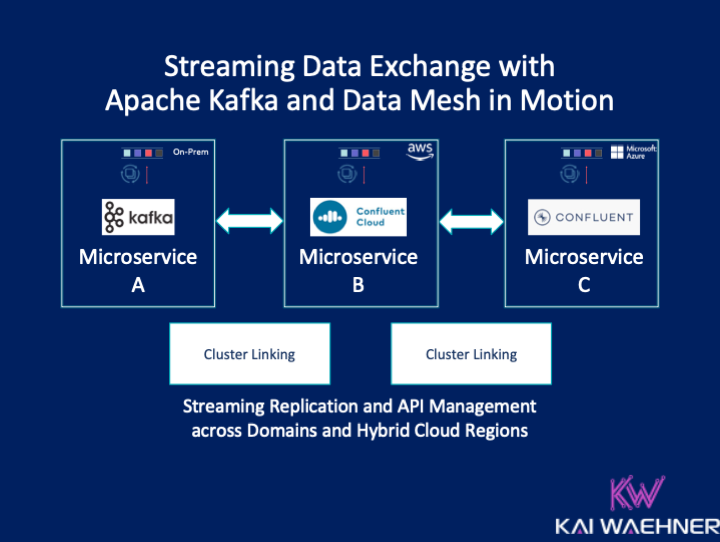
A Global Streaming Data Exchange
The Data Mesh concept is relevant for global deployments, not just within a single project or region. Multiple Kafka clusters are the norm, not an exception. I wrote about customers using Event Streaming with Kafka in global architectures a long time ago.
Various architectures exist to deploy Kafka across data centers and multiple clouds. Some use cases require low latency and deploy some Kafka instances at the edge or in a 5G zone. Other use cases replicate data between regions, countries, or continents across the globe for disaster recovery, aggregation, or analytics use cases.
Here is one example spanning a streaming Data Mesh across multiple cloud providers like AWS, Azure, GCP, or Alibaba, and on-premise / edge sites:
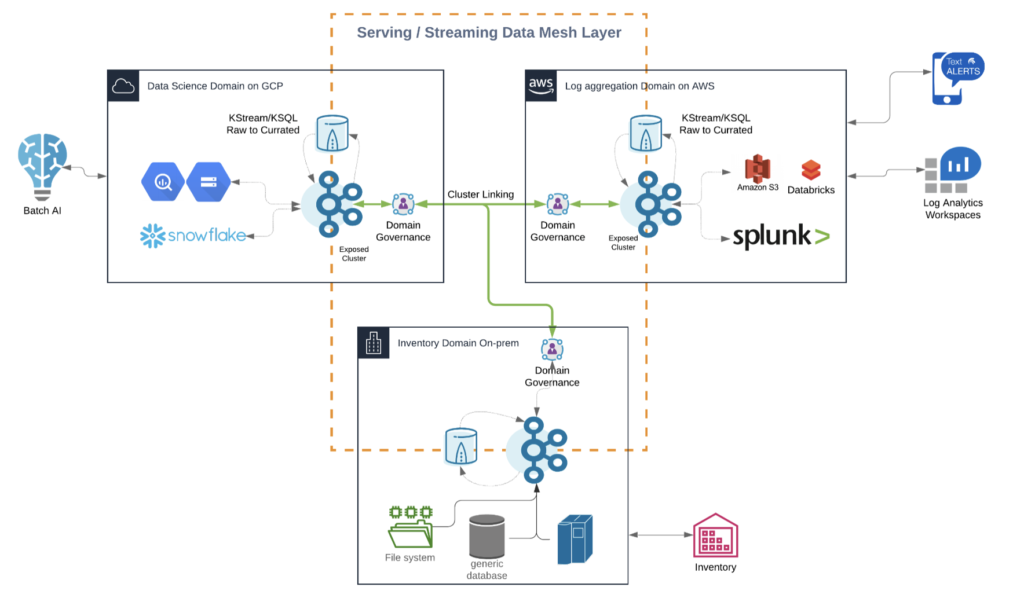
This example shows all the characteristics discussed in the above sections for a Data Mesh:
- Decentralized real-time infrastructure across domains and infrastructures
- True decoupling between domains within and between the clouds
- Several communication paradigms, including data streaming, RPC, and batch
- Data integration with legacy and cloud-native technologies
- Continuous stream processing where it adds value, and batch processing in some analytics sinks
Example: A Streaming Data Exchange across Domains in the Automotive Industry
The following example from the automotive industry shows how independent stakeholders (= domains in different enterprises) use a cross-company streaming data exchange:
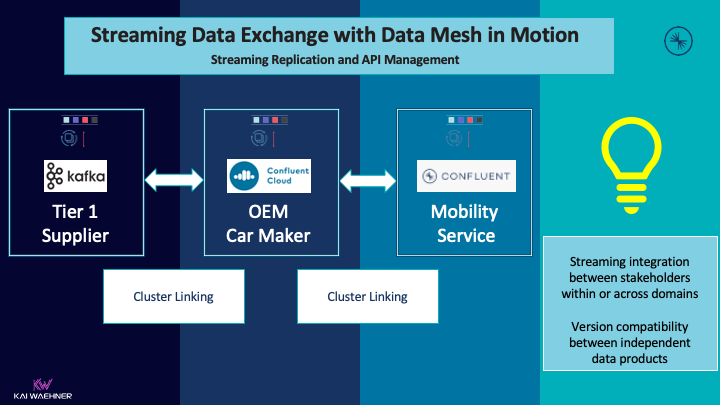
Innovation does not stop at the own border. Streaming replication is relevant for all use cases where real-time is better than slow data (valid for most scenarios). A few examples:
- End-to-end supply chain optimization from suppliers to the OEM to the intermediary to the aftersales
- Track and trace across countries
- Integration of 3rd party add-on services to the own digital product
- Open APIs for embedding and combining external services to build a new product
I could go on and on with the list. Many data products need to be accessible by 3rd party in real-time at scale. Some API gateway or API management tool comes into play in such a situation.
A real-world example of a streaming data exchange powered by Kafka is the mobility service Here Technologies. They expose the Kafka API to directly consume streaming data from their mapping services (as an alternative option to their HTTP API):

However, even if all collaborating partners use Kafka under the hood in their architecture, exposing the Kafka API directly to the outside world does not always make sense. Some technical capabilities (e.g., access control or connectivity to thousands of devices) and missing business functions (e.g., for monetization or reporting) of the Kafka ecosystem bring an API layer on top of the Event Streaming infrastructure into play in many real-world deployments.
Open API for 3rd Party Integration and Streaming API Management
API Gateways and API Management tools exist in many varieties, including open-source frameworks, commercial products, and SaaS cloud offerings. Features include technical routing, access control, monetization, and reporting.
However, most people still implement the Open API concept with RPC in mind. I guess 95+% still use HTTP(S) to make APIs accessible to other stakeholders (e.g., other business units or external parties). RPC makes little sense in a streaming Data Mesh architecture if the data needs to be processed at scale in real-time.
There is still an impedance mismatch between Event Streaming and API Management. But it gets better these days. Specifications like AsyncAPI, calling itself the “industry standard for defining asynchronous APIs”, and similar approaches bring Open API to the data streaming world. My post “Kafka versus API Management with tools like MuleSoft, Kong, or Apigee” is still pretty much accurate if you want to dive deeper into this discussion. IBM API Connect was one of the first vendors that integrated Kafka via Async API.
A great example of the evolution from RPC to streaming APIs is the machine learning space. “Streaming Machine Learning with Kafka-native Model Deployment” explores how model servers such as Seldon enhance their product with a native Kafka API besides HTTP and gRPC request-response communication:
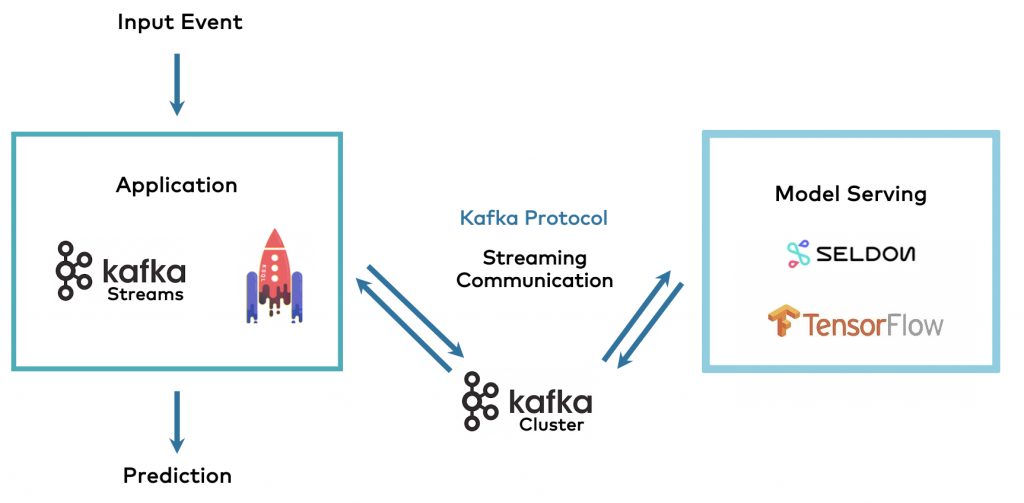
Journey to the Streaming Data Mesh with Kafka
The paradigm shift is enormous. Data Mesh is not a free lunch. The same was and still is true for microservice architectures, domain-driven design, Event Streaming, and other modern design principles.
In analogy to Confluent’s maturity model for Event Streaming, our team has described the journey for deploying a streaming Data Mesh:
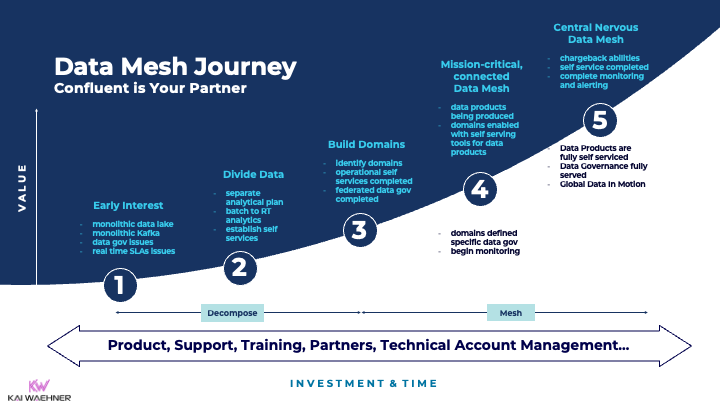
The efforts likely take a few years in most scenarios. The shift is not just about technologies, but, as necessary are adjustments to organizations and business processes. I guess most companies are still in a very early stage. Let me know where you are on this journey!
Streaming Data Exchange as Foundation for a Data Mesh
A Data Mesh is an implementation pattern, not a specific technology. However, most modern enterprise architectures require a decentralized streaming data infrastructure to build valuable and innovative data products in independent, truly decoupled domains. Hence, Kafka, being the de facto standard for Event Streaming, comes into play in many Data Mesh architectures.
Many Data Mesh architectures span across many domains in various regions or even continents. The deployments run at the edge, on-prem, and multi-cloud. The integration connects to many solutions, technologies with different communication paradigms.
A cloud-native Event Streaming infrastructure with the capability to link clusters with each other out-of-the-box enables building a modern Data Mesh. No Data Mesh will use just one technology or vendor. Learn from the inspiring posts from your favorite data products vendors like AWS, Snowflake, Databricks, Confluent, and many more to define and build your custom Data Mesh successfully. Data Mesh is a journey, not a big bang.
Did you already start building your Data Mesh? How does the enterprise architecture look like? What frameworks, products, and cloud services do you use? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.