The concepts and architectures of a data warehouse, a data lake, and data streaming are complementary to solving business problems. Storing data at rest for reporting and analytics requires different capabilities and SLAs than continuously processing data in motion for real-time workloads. Many open-source frameworks, commercial products, and SaaS cloud services exist. Unfortunately, the underlying technologies are often misunderstood, overused for monolithic and inflexible architectures, and pitched for wrong use cases by vendors. Let’s explore this dilemma in a blog series. Learn how to build a modern data stack with cloud-native technologies. This is part 5: Best Practices for Building a Cloud-Native Data Warehouse or Data Lake.

Blog Series: Data Warehouse vs. Data Lake vs. Data Streaming
This blog series explores concepts, features, and trade-offs of a modern data stack using data warehouse, data lake, and data streaming together:
- Data Warehouse vs. Data Lake vs. Data Streaming – Friends, Enemies, Frenemies?
- Data Streaming for Data Ingestion into the Data Warehouse and Data Lake
- Data Warehouse Modernization: From Legacy On-Premise to Cloud-Native Infrastructure
- Case Studies: Cloud-native Data Streaming for Data Warehouse Modernization
- THIS POST: Best Practices for Building a Cloud-Native Data Warehouse or Data Lake
Stay tuned for a dedicated blog post for each topic as part of this blog series. I will link the blogs here as soon as they are available (in the next few weeks). Subscribe to my newsletter to get an email after each publication (no spam or ads).
Best practices for building a cloud-native data warehouse or data lake
Let’s explore the following lessons learned from building cloud-native data analytics infrastructure with data warehouses, data lakes, data streaming, and lakehouses:
- Lesson 1: Process and store data in the right place.
- Lesson 2: Don’t design for data at rest to reverse it.
- Lesson 3: There is no need for a lambda architecture to separate batch and real-time workloads
- Lesson 4: Understand the trade-offs between data sharing at rest and a streaming data exchange.
- Lesson 5: Data mesh is not a single product or technology.
Let’s get started…
Lesson 1: Process and store data in the right place.
Ask yourself: What is the use case for your data?
Here are a few use case examples for data and exemplary tools to implement the business case:
- Recurring reporting for management => Data warehouse and its out-of-the-box reporting tools
- Interactive analysis of structured and unstructured data => Business intelligence tools like Tableau, Power BI, Qlik, or TIBCO Spotfire on top of the data warehouse or another data store
- Transactional business workloads => Custom Java application running in a Kubernetes environment or serverless cloud infrastructure
- Advanced analytics to find insights in historical data => Raw data sets stored in a data lake for applying powerful algorithms with AI / Machine Learning technologies such as TensorFlow
- Real-time actions on new events => Streaming applications to process and correlate data continuously while it is relevant
Real-time or batch compute on the right platform as needed
Batch workloads run best in an infrastructure that was built for this. For instance, Hadoop or Apache Spark. Real-time workloads run best in an infrastructure that was built for this. For example, Apache Kafka.
However, sometimes, both platforms could be used. Understand the underlying infrastructure to leverage it the best way. Apache Kafka can replace a database! Nevertheless, it should only be done in the few scenarios where it makes sense (i.e., simplifies the architecture or adds business value).
For example, replayability as a sequence of events (with guaranteed ordering with time stamps) is built into the immutable Kafka log. Replaying and re-processing historical data from Kafka are straightforward and a perfect use case for many scenarios, including:
- New consumer application
- Error-handling
- Compliance / regulatory processing
- Query and analyze existing events
- Schema changes in the analytics platform
- Model training
On the other side, if you need to do complex analytics like map-reduce or shuffling, SQL queries with tens of JOINs, a robust time-series analysis of sensor events, a search index based on ingested log information, and so on. Then you better choose Spark, Rockset, Apache Druid, or Elasticsearch for that use case.
Tiered storage with cloud-native object storage for cost-efficiency
A single storage infrastructure cannot solve all these problems, even if the “lakehouse vendors” tell you so. Hence, ingesting all data into a single system will fail to succeed with the above use cases. Choose a best-of-breed approach instead with the right tools for the job.
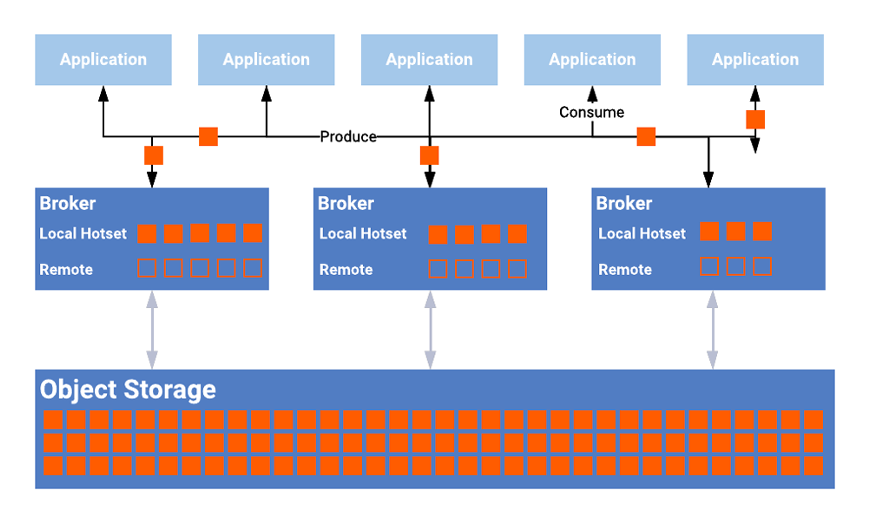
Modern, cloud-native systems decouple storage and compute. This is true for data streaming platforms like Apache Kafka and analytics platforms like Apache Spark, Snowflake, or Google BigQuery. SaaS solutions implement innovative tiered storage solutions (under the hood so you don’t see them) for cost-efficient separation between storage and compute.
Even modern data streaming services leverage tiered storage:
Lesson 2: Don’t design for data at rest to reverse it.
Ask yourself: Is there any added business value if you process data now instead of later (whatever later means)?
If yes, then don’t store the data in a database or data lake, or data warehouse as the first step. The data is stored at rest then and not available for real-time processing anymore. A data streaming platform like Apache Kafka is the right choice if real-time data beats slow data in your use case!
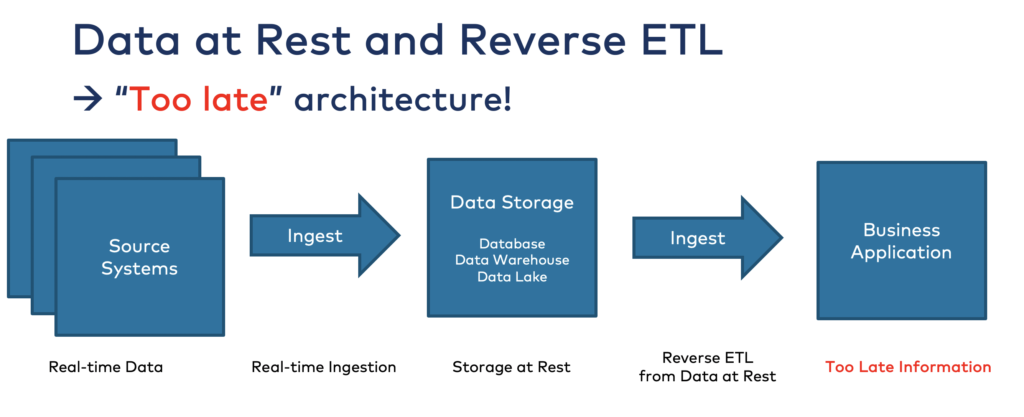
I find it amazing how many people put all their raw data into data storage just to find out that they could leverage the data in real-time later. Reverse ETL tools are spun up then to access the data in the lakehouse again via change data capture (CDC) or similar approaches. Or if you use Spark Structured Streaming (= “real-time”), but the first thing to get the data for “real-time stream processing” is reading it from an S3 object storage (= “at rest and too late”) is unfitting.
Reverse ETL is NOT the right approach for real-time use cases…
If you store data in a data warehouse or data lake, you cannot process it in real-time anymore as it is already stored at rest. These data stores are built for indexing, search, batch processing, reporting, model training, and other use cases that make sense in the storage system. But you cannot consume the data in real-time in motion from storage at rest:
… data streaming is built for continuously processing data in real-time
That’s where event streaming comes into play. Platforms like Apache Kafka enable processing data in motion in real-time for transactional and analytical workloads.
Reverse ETL is not needed in modern event-driven architecture! It is “built-in” into the architecture out-of-the-box. Each consumer directly consumes the data in real-time, if appropriate and technically feasible. And data warehouses or data lakes still consume it at their own pace in near-real-time or batch:
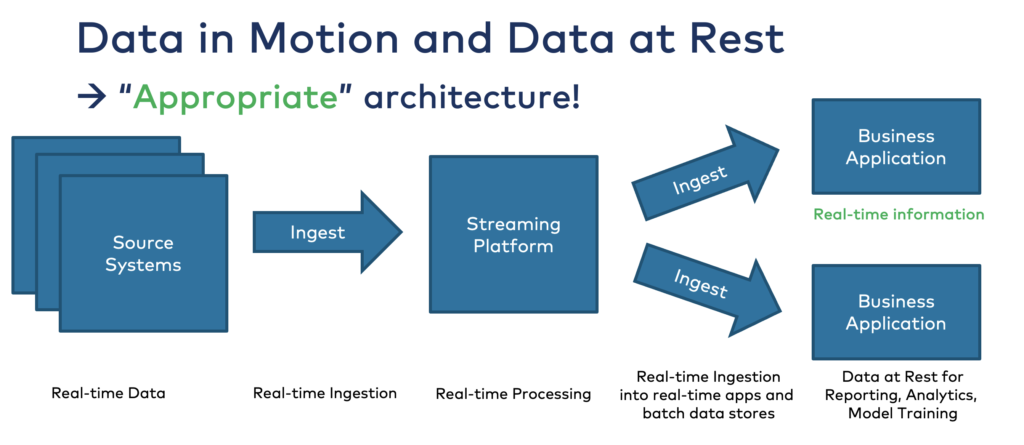
Again, this does not mean you should not put data at rest in your data warehouse or data lake. But only do that if you need to analyze the data later. The data storage at rest is NOT appropriate for real-time workloads.
Learn more about this topic in my blog post “When to Use Reverse ETL and when it is an Anti-Pattern“.
Lesson 3: There is no need for a lambda architecture to separate batch and real-time workloads
Ask yourself: What is the easiest way to consume and process incoming data with my favorite data analytics technology?
Real-time data beats slow data, but NOT always!
Think about your industry, business units, problems you solve, and innovative new applications you build. Real-time data beats slow data. This statement is almost always true. Either to increase revenue, reduce cost, reduce risk, or improve the customer experience.
Data at rest means to store data in a database, data warehouse, or data lake. This way, data is processed too late in many use cases – even if a real-time streaming component (like Kafka) ingests the data. The data processing is still a web service call, SQL query, or map-reduce batch process away from providing a result to your problem.
Don’t get me wrong. Data at rest is not a bad thing. Several use cases, such as reporting (business intelligence), analytics (batch processing), and model training (machine learning) work very well with this approach. But real-time beats batch in almost all other use cases.
The Kappa architecture simplifies the infrastructure for batch AND real-time workloads
The Kappa architecture is an event-based software architecture that can handle all data at any scale in real-time for transactional AND analytical workloads.
The central premise behind the Kappa architecture is that you can perform both real-time and batch processing with a single technology stack. That’s a very different approach than the well-known Lambda architecture. The latter separates batch and real-time workloads in separate infrastructures and technology stacks.
The heart of a Kappa infrastructure is streaming architecture. First, the event streaming platform log stores incoming data. From there, a stream processing engine processes the data continuously in real-time or ingests the data into any other analytics database or business application via any communication paradigm and speed, including real-time, near real-time, batch, and request-response.
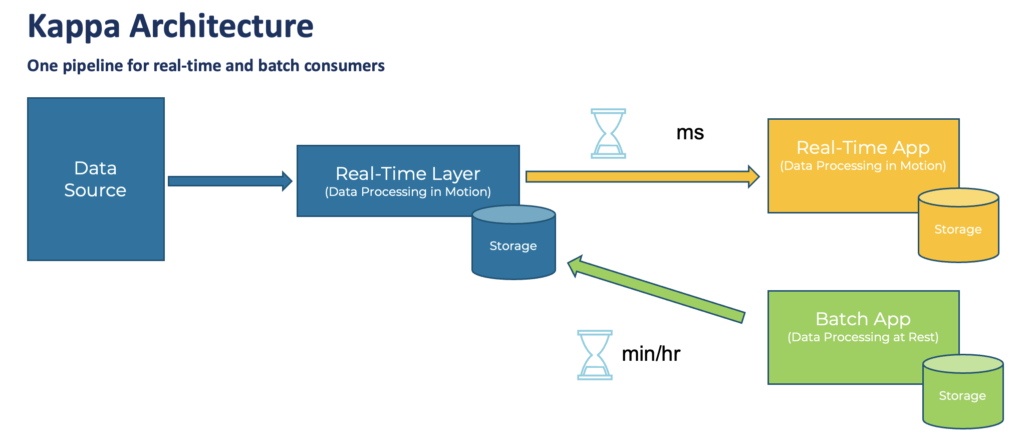
Learn more about the benefits and trade-offs of the Kappa architecture in my article “Kappa Architecture is Mainstream Replacing Lambda“.
Lesson 4: Understand the trade-offs between data sharing at rest and a streaming data exchange.
Ask yourself: How do I need to share data with other internal business units or external organizations?
Use cases for hybrid and multi-cloud replication with data streaming, data lakes, data warehouses, and lakehouses
Many good reasons exist to replicate data across data centers, regions, or cloud providers:
- Disaster recovery and high availability: Create a disaster recovery cluster and failover during an outage.
- Global and multi-cloud replication: Move and aggregate data across regions and clouds.
- Data sharing: Share data with other teams, lines of business, or organizations.
- Data migration: Migrate data and workloads from one cluster to another (like from a legacy on-premise data warehouse to a cloud-native data lakehouse).
Real-time data replication beats slow data sharing
The story around internal or external data sharing is not different from other applications. Real-time replication beats slow data exchanges. Hence, storing data at rest and then replicating it to another data center, region, or cloud provider is an anti-pattern if real-time information adds business value.
The following example shows how independent stakeholders (= domains in different enterprises) use a cross-company streaming data exchange:
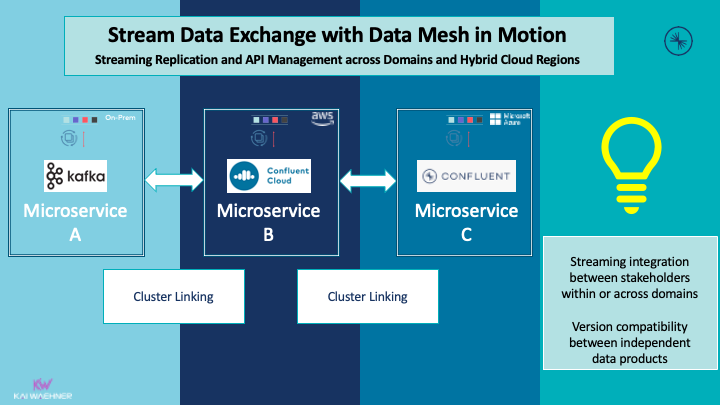
Innovation does not stop at the own border. Streaming replication is relevant for all use cases where real-time is better than slow data (valid for most scenarios). A few examples:
- End-to-end supply chain optimization from suppliers to the manufacturer to the intermediary to the aftersales
- Track and trace across countries
- Integration of 3rd party add-on services to the own digital product
- Open APIs for embedding and combining external services to build a new product
Read the details about a “Streaming Data Exchange with Kafka and a Data Mesh in Motion vs. Data Sharing at Rest in the Data Warehouse or Data Lake” for more details.
Also, understand why APIs (= REST / HTTP) and data streaming (= Apache Kafka) are complementary, not competitive!
Lesson 5: Data mesh is not a single product or technology.
Ask yourself: How do I create a flexible and agile enterprise architecture to innovate more efficiently and solve my business problems faster?
Data Mesh is a Logical View, not Physical!
Data mesh shifts to a paradigm that draws from modern distributed architecture: considering domains as the first-class concern, applying platform thinking to create a self-serve data infrastructure, treating data as a product, and implementing open standardization to enable an ecosystem of interoperable distributed data products.
Here is an example of a Data Mesh:
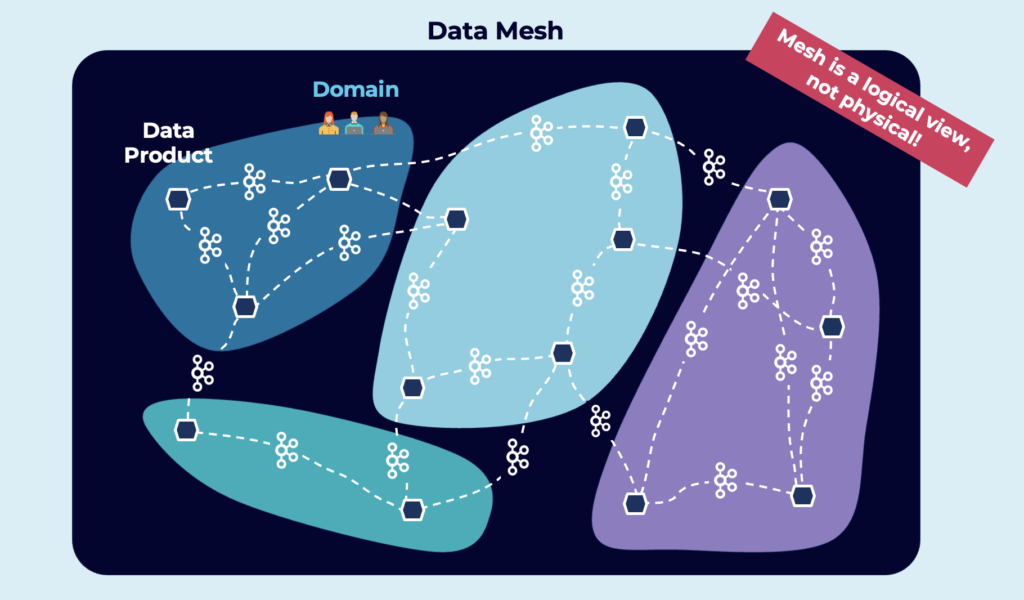
TL;DR: Data Mesh combines existing paradigms, including Domain-driven Design, Data Marts, Microservices, and Event Streaming.
A data warehouse or data lake is NOT and CAN NOT BECOME the entire data mesh!
The heart of a Data Mesh infrastructure should be real-time, decoupled, reliable, and scalable. Kafka is a modern cloud-native enterprise integration platform (also often called iPaaS today). Therefore, Kafka provides all the capabilities for the foundation of a Data Mesh.
However, not all components can or should be Kafka-based. The beauty of microservice architectures is that every application can choose the right technologies. An application might or might not include databases, analytics tools, or other complementary components. The input and output data ports of the data product should be independent of the chosen solutions:

Kafka can be a strategic component of a cloud-native data mesh, not more and not less. But even if you do not use data streaming and build a data mesh only with data at rest, there is still no silver bullet. Don’t try to build a data mesh with a single product, technology, or vendor. No matter if that tool focuses on real-time data streaming, batch processing and analytics, or API-based interfaces. Tools like Starburst – a SQL-based MPP query engine powered by open source Trino (formerly Presto) – enable analytics on top of different data stores.
Best practices for a cloud-native data warehouse go beyond a SaaS product
Building a cloud-native data warehouse or data lake is an enormous project. It requires data ingestion, data integration, connectivity to analytics platforms, data privacy and security patterns, and much more. All of that is needed before the actual tasks like reporting or analytics can even begin.
The complete enterprise architecture beyond the scope of the data warehouse or data lake is even more complex. Best practices must be applied to build a resilient, scalable, elastic, and cost-efficient data analytics infrastructure. SLAs, latencies, and uptime have very different requirements across business domains. Best of breed approaches choose the right tool for the job. True decoupling between business units and applications allows focusing on solving specific business problems.
Separation of storage and compute, unified real-time pipelines instead of separating batch and real-time, avoiding anti-patterns like Reverse ETL, and appropriate data sharing concepts enable a successful journey to cloud-native data analytics.
For more details, browse other posts of this blog series:
- Data Warehouse vs. Data Lake vs. Data Streaming – Friends, Enemies, Frenemies?
- Data Streaming for Data Ingestion into the Data Warehouse and Data Lake
- Data Warehouse Modernization: From Legacy On-Premise to Cloud-Native Infrastructure
- Case Studies: Cloud-native Data Streaming for Data Warehouse Modernization
- THIS POST: Lessons Learned from Building a Cloud-Native Data Warehouse
How did you modernize your data warehouse or data lake? Do you agree with the lessons I learned? What other experiences did you have? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.





