Apache Kafka
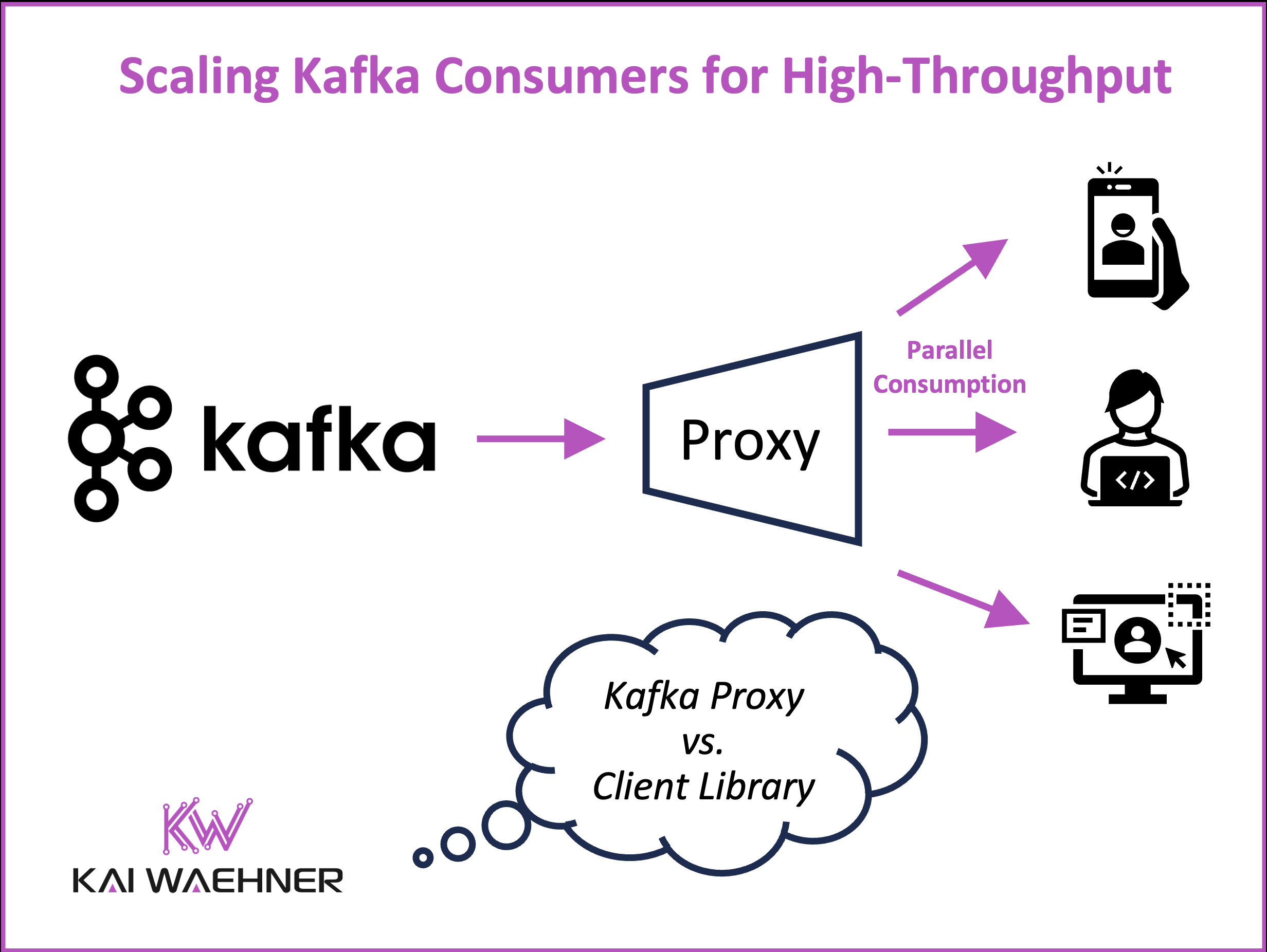
Apache Kafka’s pull-based model and decoupled architecture offer unmatched flexibility for event-driven systems. But as data volumes and consumer applications grow, new challenges emerge; from

Apache Kafka’s pull-based model and decoupled architecture offer unmatched flexibility for event-driven systems. But as data volumes and consumer applications grow, new challenges emerge; from

Apache Kafka is the de facto standard for event streaming to process data in motion. This blog post explores when NOT to use Apache Kafka.

This blog post takes a look at cutting edge technologies like Apache Kafka, Kubernetes, Envoy, Linkerd and Istio to implement a cloud-native service mesh for
I just want to share my lightboard video recording. I talk about IoT integration and processing with Apache Kafka using Kafka Connect, Kafka Streams, KSQL,
Processing IoT Data from End to End with MQTT and Apache Kafka => Video recording of my talk at Kafka Summit SF 2018 is online.




You need to load content from reCAPTCHA to submit the form. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Turnstile. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Vimeo. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from YouTube. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou need to load content from reCAPTCHA to submit the form. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Elfsight. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Facebook. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More Information