
Microservice architectures are not free lunch! Microservices need to be decoupled, flexible, operationally transparent, data aware and elastic. Most material from last years only discusses point-to-point architectures with tightly coupled and non-scalable technologies like REST / HTTP. This blog post takes a look at cutting edge technologies like Apache Kafka, Kubernetes, Envoy, Linkerd and Istio to implement a cloud-native service mesh to solve these challenges and bring microservices to the next level of scale, speed and efficiency.
Here are the key requirements for building a scalable, reliable, robust and observable microservice architecture:

Before we go into more detail, let’s take a look at the key takeaways first:
- Apache Kafka decouples services, including event streams and request-response
- Kubernetes provides a cloud-native infrastructure for the Kafka ecosystem
- Service Mesh helps with security and observability at ecosystem / organization scale
- Envoy and Istio sit in the layer above Kafka and are orthogonal to the goals Kafka addresses
The following sections cover some more thoughts about this. The end of the blog post contains a slide deck and video recording to get some more detailed explanations.
Microservices, Service Mesh and Apache Kafka
Apache Kafka became the de facto standard for microservice architectures. It goes far beyond reliable and scalable high-volume messaging. The distributed storage allows high availability and real decoupling between the independent microservices. In addition, you can leverage Kafka Connect for integration and the Kafka Streams API for building lightweight stream processing microservices in autonomous teams.
A Service Mesh complements the architecture. It describes the network of microservices that make up such applications and the interactions between them. Its requirements can include discovery, load balancing, failure recovery, metrics, and monitoring. A service mesh also often has more complex operational requirements, like A/B testing, canary rollouts, rate limiting, access control, and end-to-end authentication.
I explore the problem of distributed Microservices communication and how both Apache Kafka and Service Mesh solutions address it. This blog post takes a look at some approaches for combining both to build a reliable and scalable microservice architecture with decoupled and secure microservices.
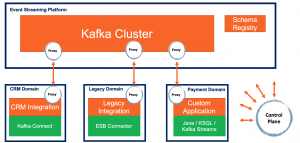
Discussions and architectures include various open source technologies like Apache Kafka, Kafka Connect, Kubernetes, HAProxy, Envoy, LinkerD and Istio.
Learn more about decoupling microservices with Kafka in this related blog post about “Microservices, Apache Kafka, and Domain-Driven Design (DDD)“.
Cloud-Native Kafka with Kubernetes
Cloud-native infrastructures are scalable, flexible, agile, elastic and automated. Kubernetes got the de factor standard. Deployment of stateless services is pretty easy and straightforward. Though, deploying stateful and distributed applications like Apache Kafka is much harder. A lot of human operations is required. Kubernetes does NOT automatically solve Kafka-specific challenges like rolling upgrades, security configuration or data balancing between brokers. The Kafka Operator – implemented in K8s Custom Resource Definitions (CRD) – can help here!
The Operator pattern for Kubernetes aims to capture the key aim of a human operator who is managing a service or set of services. Human operators who look after specific applications and services have deep knowledge of how the system ought to behave, how to deploy it, and how to react if there are problems.
People who run workloads on Kubernetes often like to use automation to take care of repeatable tasks. The Operator pattern captures how you can write code to automate a task beyond what Kubernetes itself provides.
Different implementations for a Kafka Operator for Kubernetes exist: Confluent Operator, IBM’s / Red Hat’s Strimzi, Banzai Cloud. I won’t go into more detail about the characteristics and advantages of a K8s Kafka Operator here. I already explained it in detail in another blog post (and the video below will also discuss this topic):
Service Mesh with Kubernetes-based Technologies like Envoy, Linkerd or Istio
Service Mesh is a microservice pattern to move visibility, reliability, and security primitives for service-to-service communication into the infrastructure layer, out of the application layer.
A great, detailed explanation of the design pattern “service mesh” can be found here, including the following diagram which shows the relation between a control plane and the microservices with proxy sidecars:
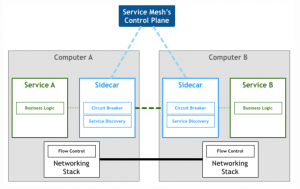
You can find much more great content about service mesh concepts and its implementations from the creators of frameworks like Envoy or Linkerd. Check out these two links or just use Google for more information about the competing alternatives and their trade-offs.
(Potential) Features for Apache Kafka and Service Mesh
An event streaming platform like Apache Kafka and a service mesh on top of Kubernetes are cloud-native, orthogonal and complementary. Together they solve the key requirements for building a scalable, reliable, robust and observable microservice architecture:

Companies use Kafka together with service mesh implementations like Envoy, Linkerd or Istio already today. You can easily combine them to add security, enforce rate limiting, or implement other related use cases. Banzai Cloud published one of the most interesting architectures: They use Istio for adding security to Kafka Brokers and ZooKeeper via proxies using Envoy.
However, in the meantime, the support gets even better: The pull request for Kafka support in Envoy was merged in May 2019. This means you now have native Kafka protocol support in Envoy. The very interesting discussions about its challenges and potential features of implementing a Kafka protocol filter are also worth reading.
With native Kafka protocol support, you can do many more interesting things beyond L4 TCP filtering. Here are just some ideas (partly from above Github discussion) of what you could do with L7 Kafka protocol support in a Service Mesh:
Protocol conversion from HTTP / gRPC to Kafka
- Tap feature to dump to a Kafka stream
- Protocol parsing for observability (stats, logging, and trace linking with HTTP RPCs)
- Shadow requests to a Kafka stream instead of HTTP / gRPC shadow
- Integrate with Kafka Connect and its whole ecosystem of connectors
Proxy features
- Dynamic Routing
- Rate limiting at both the L4 connection and L7 message level
- Filter, add compression, …
- Automatic topic name conversion (e.g. for canary release or blue/green deployment)
Monitoring and Tracing
- Request logs and stats
- Data lineage / audit log
- Audit log by taking request logs and enriching them with the user info.
- Client specific metrics (Byte rate per client id / per consumer groups, versions of the client libraries, consumer lag monitoring for the entire data center)
Security
- SSL Termination
- Mutual TLS (mTLS)
- Authorization
Validation of Events
- Serialization format (JSON, Avro, Protobuf, etc.)
- Message schema
- Headers, attributes, etc.
That’s awesome, isn’t it?
Microservices, Kafka and Service Mesh – Slide Deck and Video Recording
Let’s take a look at my slide deck and video recording to understand the requirements, challenges and opportunities of building a Service Mesh with Apache Kafka, its ecosystem, Kubernetes and Service Mesh technologies in more detail…
Here is the slide deck:
You are currently viewing a placeholder content from Default. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
The video recording walks you through the slide deck:
You are currently viewing a placeholder content from Default. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
Any thoughts or feedback? Please let me know via a comment or Tweet or let’s connect on LinkedIn.





