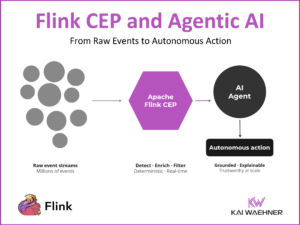
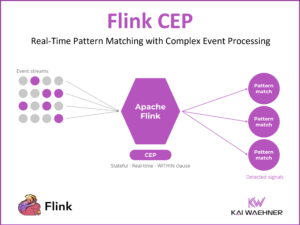
Kappa Architecture is Mainstream Replacing Lambda
Real-time data beats slow data. That’s true for almost every use case. Nevertheless, enterprise architects build new infrastructures with the Lambda architecture that includes separate batch and real-time layers. This blog post explores why a single real-time pipeline, called Kappa architecture, is the better fit. Real-world examples from companies such as Disney, Shopify, Uber, and Twitter explore the benefits of Kappa but also show how batch processing fits into this discussion positively without the need for Lambda.