Apache Kafka became the de facto standard for processing data in motion. Kafka is open, flexible, and scalable. Unfortunately, the latter makes operations a challenge for many teams. Ideally, teams can use a serverless Kafka SaaS offering to focus on business logic. However, hybrid scenarios require a cloud-native platform that provides automated and elastic tooling to reduce the operations burden. This blog post explores how to leverage cloud-native and serverless Kafka offerings in a hybrid cloud architecture. We start from the perspective of data at rest with a data lake and explore its relation to data in motion with Kafka.

Data at Rest – Still the Right Approach?
Data at Rest means to store data in a database, data warehouse, or data lake. This means that the data is processed too late in many use cases – even if a real-time streaming component (like Kafka) ingests the data. The data processing is still a web service call, SQL query, or map-reduce batch process away from providing a result to your problem.
Don’t get me wrong. Data at rest is not a bad thing. Several use cases such as reporting (business intelligence), analytics (batch processing), and model training (machine learning) require this approach… If you do it right!
The Wrong Approach of Cloudera’s Data Lake
A data lake was introduced into most enterprises by Cloudera and Hortonworks (plus several partners like IBM) years ago. Most companies had a big data vision (but they had no idea how to gain business value out of it). The data lake consists of 20+ different open source frameworks.
New frameworks are added when they emerge so that the data lake is up-to-date. The only problem: Still no business value. Plus vendors that have no good business model. Just selling support does not work, especially if two very similar vendors compete with each other. The consequence was the Cloudera/Hortonworks merger. And a few years later, the move to private equity.
In 2021, Cloudera still supports so many different frameworks, including many data lake technologies but also event streaming platforms such as Storm, Kafka, Spark Streaming, Flink. I am surprised how one relatively small company can do this. Well, honestly, I am not amazed. TL;DR: They can’t! They know each framework a little bit (and only the dying Hadoop ecosystem very well). This business model does not work. Also, in 2021, Cloudera still does not have a real SaaS product. This is no surprise either. It is not easy to build a true SaaS offering around 20+ frameworks.
Hence, my opinion is confirmed: Better do one thing right if you are a relatively small company instead of trying to do all the things.
The Lake House Strategy from AWS
That’s why data lakes are built today with other vendors: The major cloud providers (AWS, GCP, Azure, Alibaba), MongoDB, Databricks, Snowflake. All of them have their specific use cases and trade-offs. However, all of them have in common that they have a cloud-first strategy and a serverless SaaS offering for their data lake.
Let’s take a deeper look at AWS to understanding how a modern, cloud-native strategy with a good business model looks like in 2021.
AWS is the market leader for public cloud infrastructure. Additionally, AWS invents new infrastructure categories regularly. For example, EC2 instances started the cloud era and enabled agile and elastic compute power. S3 became the de facto standard for object storage. Today, AWS has hundreds of innovative SaaS services.
AWS’ data lake strategy is based on the new buzzword Lake House:
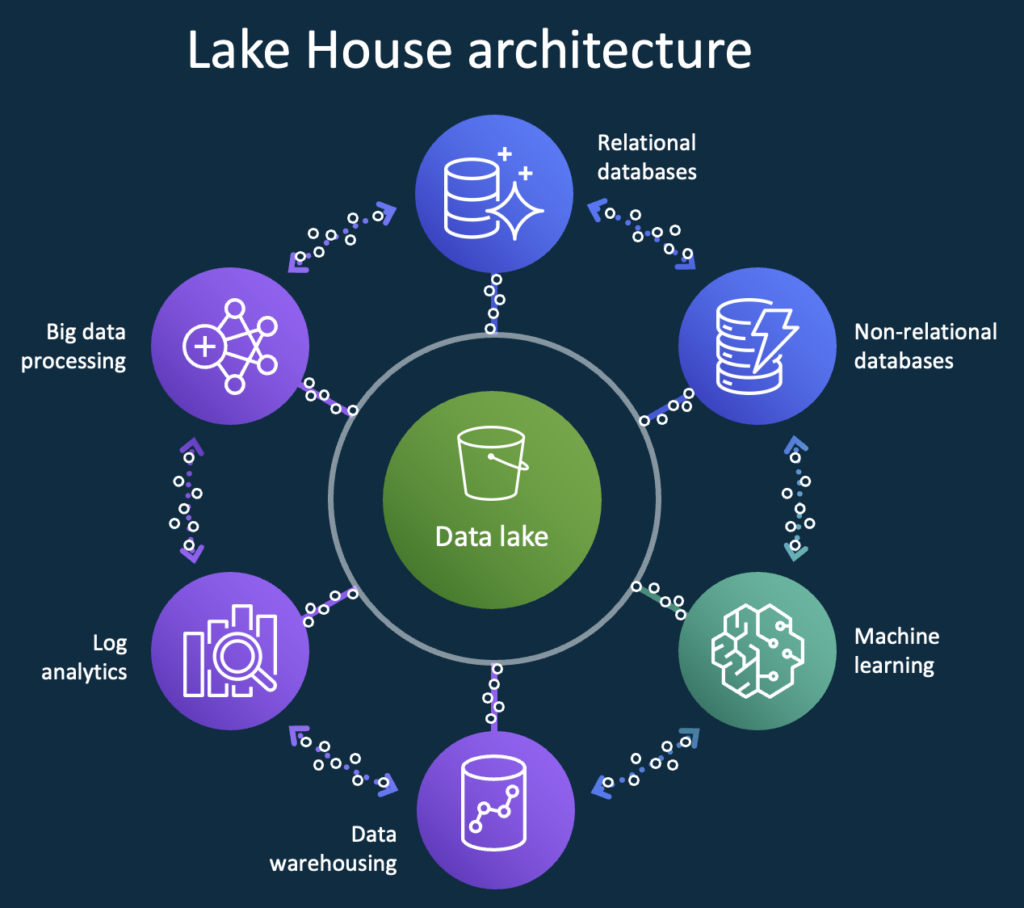
As you can see, the key message is that one solution cannot solve all problems. However, even more important, all of these problems are solved with cloud-native, serverless AWS solutions:
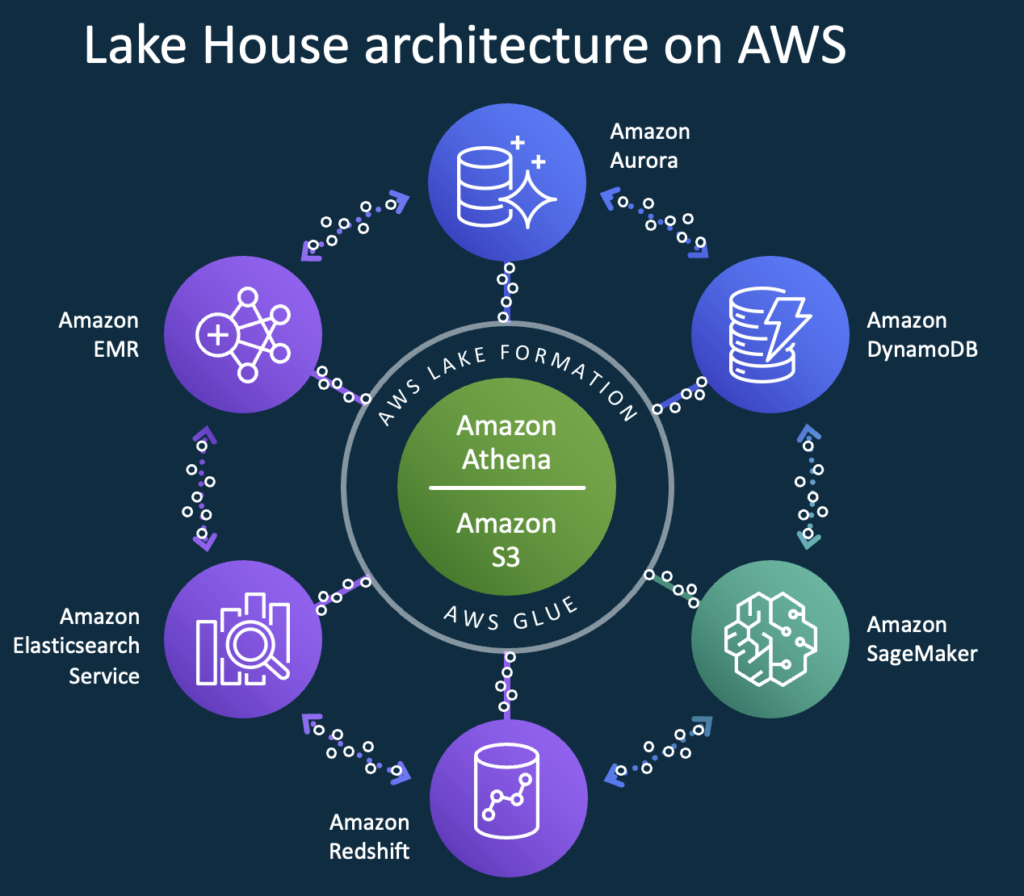
This is how a cloud-native data lake offering in the public cloud has to look like—obviously, other hyperscalers like GCP and Azure head in the same direction with their serverless offerings.
Unfortunately, the public cloud is not the right choice for every problem due to latency, security, and cost reasons.
Hybrid and Multi-Cloud become the Norm
In the last years, many new innovative solutions tackle another market: Edge and on-premise infrastructure. Some examples: AWS Local Zones, AWS Outposts, AWS Wavelength. I really like the innovative approach from AWS of setting new infrastructure and software categories. Most cloud providers have very similar offerings, but AWS rolls it out in many cases, and others often more or less copy it. Hence, I focus on AWS in this post.
Having said this, each cloud provider has specific strengths. GCP is well known for its leadership in open source-powered services around Kubernetes, TensorFlow, and others. IBM and Oracle are best in providing services and infrastructure for their own products.
I see demand for multiple cloud providers everywhere. Most customers I talk to have a multi-cloud strategy using AWS and other vendors like Azure, GCP, IBM, Oracle, Alibaba, etc. Good reasons exist to use different cloud providers, including cost, data locality, disaster recovery across vendors, vendor independence, historical reasons, dedicated cloud-specific services, etc.
Fortunately, the serverless Kafka SaaS Confluent Cloud is available on all major clouds. Hence, similar examples are available for the usage of the fully-managed Kafka ecosystem with Azure and GCP. Hence, let’s finally go to the Kafka part of this post… 🙂
From “Data at Rest” to “Data in Motion”
This was a long introduction before we actually come back to serverless Kafka. But only with background knowledge is it possible to understand the rise of data in motion and the need for cloud-native and serverless services.
Let’s start with the key messages to point out:
- Real-time beats slow data in most use cases across industries.
- For event streaming, the same cloud-native approach is required as for the modern data lake.
- Event streaming and data lake / lake house technologies are complementary, not competitive.
The rise of event-driven architectures and data in motion powered by Apache Kafka enables enterprises to build real-time infrastructure and applications.
Apache Kafka – The De Facto Standard for Data in Motion
I will not explore the reasons and use cases for the success of Kafka in this post. Instead, check out my overview about Kafka use cases across industries for more details. Or read some of my vertical-specific blog posts.
In short, most added value comes from processing data in motion while it is relevant instead of storing data at rest and process it later (or too late). The following diagram from Forrester’s Mike Gualtieri shows this very well:
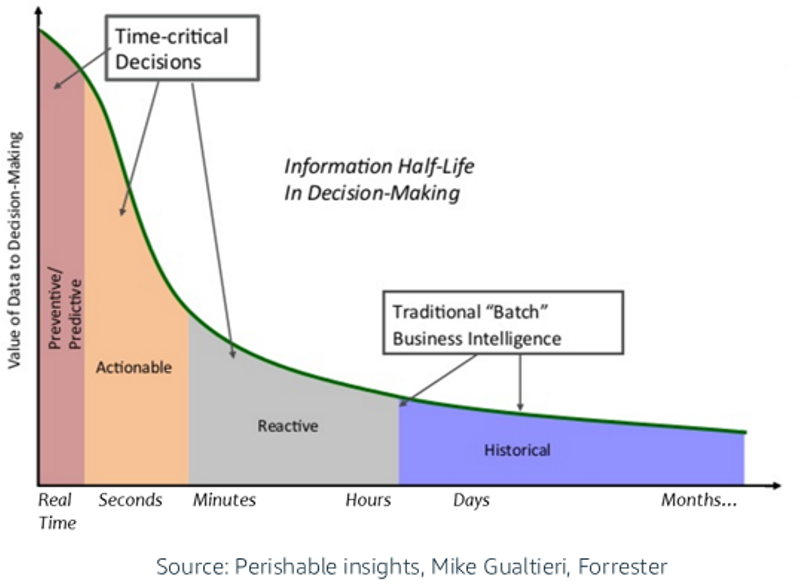
The Kafka API is the De Facto Standard API for Data in Motion like Amazon S3 for Object Storage:

While I understand that vendors such as Snowflake and MongoDB would like to get into the data in motion business, I doubt this makes much sense. As discussed earlier in the Cloudera section, it is best to focus on one thing and do that very well. That’s obviously why Confluent has strong partnerships not just with the cloud providers but also with Snowflake and MongoDB.
Apache Kafka is the battle-tested and scalable open-source framework for processing data in motion. However, it is more like a car engine.
A Complete, Serverless Kafka Platform
As I talk about cloud, serverless, AWS, etc., you might ask yourself: “Why even think about Kafka on AWS at all if you can simply use Amazon MSK?” – that’s the obligatory, reasonable question!
The short answer: Amazon MSK is PaaS and NOT a fully managed and NOT a serverless Kafka SaaS offering.
Here is a simple counterquestion: Do you prefer to buy
- a battle-tested car engine (without wheels, brakes, lights, etc.)
- a complete car (including mature and automated security, safety, and maintenance)
- a self-driving car (including safe automated driving without the need to steer the car, refueling, changing brakes, product recalls, etc.)

In the Kafka world, you only get a self-driving car from Confluent. That’s not a sales or marketing pitch, but the truth. All other cloud offerings provide you a self-managed product where you need to choose the brokers, fix bugs, do performance tuning, etc., by yourself. This is also true for Amazon MSK. Hence, I recommend evaluating the different offerings to understand if “fully managed” or “serverless” is just a marketing term or reality.
Check out “Comparison of Open Source Apache Kafka vs. Vendors including Confluent, Cloudera, Red Hat, Amazon MSK” for more details.
No matter if you want to build a data lake / lake house architecture, integrate with other 3rd party applications, or build new custom business applications: Serverless is the way to go in the cloud!
Serverless, fully-managed Kafka
A fully managed serverless offering is the best choice if you are in the public cloud. No need to worry about operations efforts. Instead, focus on business problems using a pay-as-you-go model with consumption-based pricing and mission-critical SLAs and support.

A truly fully managed and serverless offering does not give you access to the server infrastructure. Or did you get access to your AWS S3 object storage or Snowflake server configs? No, because then you would have to worry about operations and potentially impact or even destroy the cluster.
Self-managed Cloud-native Kafka
Not every Kafka cluster runs in the public cloud. Therefore, some Kafka clusters require partial management by their own operations team. I have seen plenty of enterprises struggling with Kafka operations themselves, especially if the use case is not just data ingestion into a data lake but mission-critical transactional or analytical workloads.
A cloud-native Kafka supports the operations team with automation. This reduces risks and efforts. For example, self-balancing clusters take over the rebalancing of partitions. Automated rolling upgrades allow that you upgrade to every new release instead of running an expensive and risky migration project (often with the consequence of not migrating to new versions). Separation of computing and storage (with Tiered Storage) enables large but also cost-efficient Kafka clusters with Terrabytes or even Petabytes of data. And so on.
Oh, by the way: A cloud-native Kafka cluster does not have to run on Kubernetes. Ansible or plain container/bare-metal deployments are other common options to deploy Kafka in your own data center or at the edge. But Kubernetes definitely provides the best cloud-native experience regarding automation with elastic scale. Hence, various Kafka operators (based on CRDs) were developed in the past years, for instance, Confluent for Kubernetes or Red Hat’s Strimzi.
Kafka is more than just Messaging and Data Ingestion
Last but not least, let’s be clear: Kafka is more than just messaging and data ingestion. I see most Kafka projects today also leverage Kafka Connect for data integration and/or Kafka Streams/ksqlDB for continuous data processing. Thus, with Kafka, one single (distributed and scalable) infrastructure enables messaging, storage, integration, and processing of data:
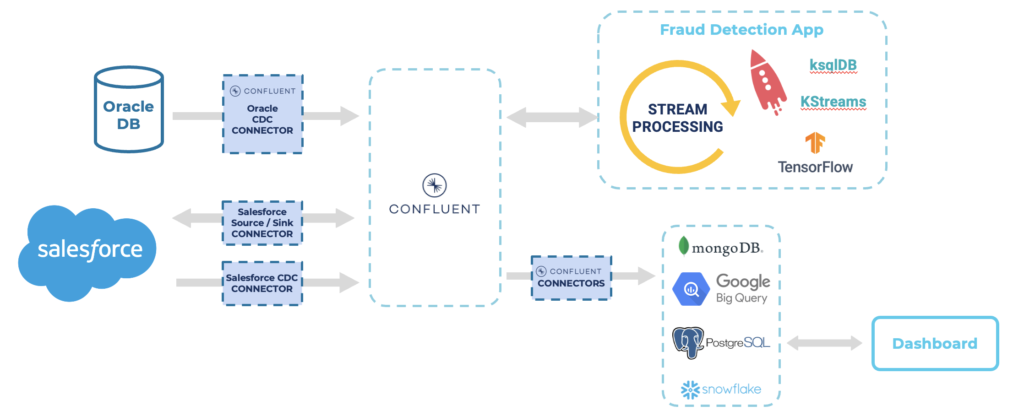
A fully-managed Kafka platform does not just operate Kafka but the whole ecosystem. For instance, fully-managed connectors enable serverless data integration with native AWS services such as S3, Redshift or Lambda, and non-AWS systems such as MongoDB Atlas, Salesforce or Snowflake. In addition, fully managed streaming analytics with ksqlDB enables continuous data processing at scale.
A complete Kafka platform provides the whole ecosystem, including security (role-based access control, encryption, audit logs), data governance (schema registry, data quality, data catalog, data lineage), and many other features like global resilience, flexible DevOps automation, metrics, monitoring, etc.
Example 1: Event Streaming + Data Lake / Lake House
The following example shows how to use a complete platform to do real-time analytics with various Confluent components plus integration with AWS lake house services:
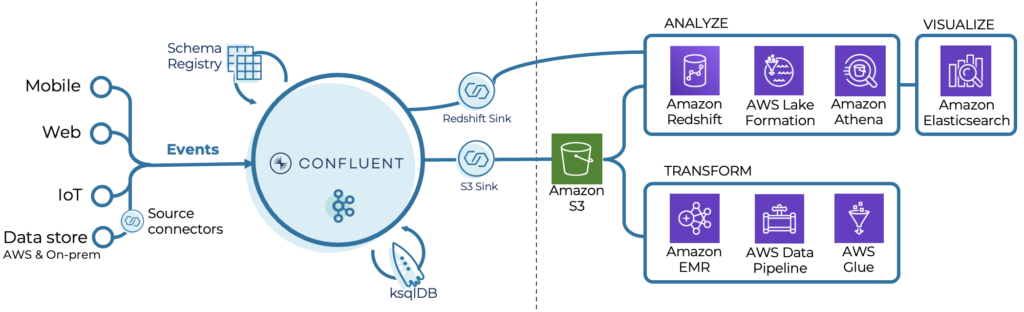
Ingest & Process
Capture event streams with a consistent data structure using Schema Registry, develop real-time ETL pipelines with a lightweight SQL syntax using ksqlDB & unify real-time streams with batch processing using Kafka Connect Connectors.
Store & Analyze
Stream data with pre-built Confluent connectors into your AWS data lake or data warehouse to execute queries on vast amounts of streaming data for real-time and batch analytics.
This example shows very well how data lake or lake house services and event streaming complement each other. All services are SaaS. Even the integration (powered by Kafka Connect) is serverless.
Example 2: Serverless Application and Microservice Integration
The following example shows how to use a complete platform to integrate existing and build new applications and serverless microservices with various Confluent and AWS services:
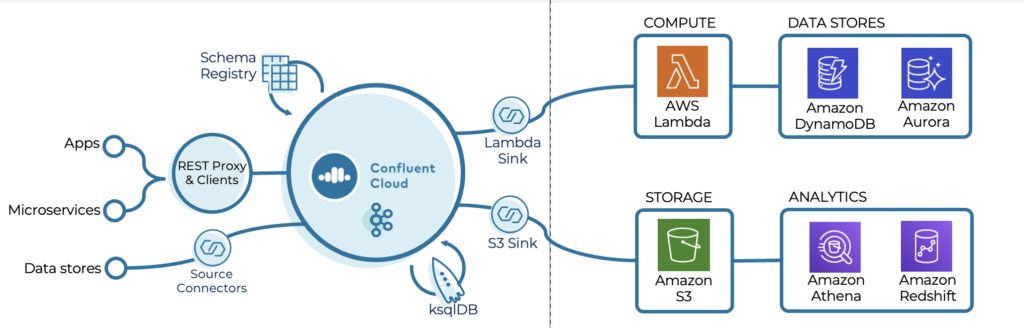
Serverless integration
Connect existing and applications and data stores in a repeatable way without having to manage and operate anything. Apache Kafka and Schema Registry ensure to maintain app compatibility. ksqlDB allows to development of real-time apps with SQL syntax. Kafka Connect provides effortless integrations with Lambda & data stores.
AWS serverless platform
Stop provisioning, maintaining, or administering servers for backend components such as compute, databases and storage so that you can focus on increasing agility and innovation for your developer teams.
Kafka Everywhere – Cloud, On-Premise, Edge
The public cloud is the future of the data center. However, two main reasons exist NOT to run everything in a public cloud infrastructure:
- Brownfield architectures: Many enterprises have plenty of applications and infrastructure in data centers. Hybrid cloud architectures are the only option. Think about mainframes as one example.
- Edge use cases: Some scenarios do not make sense in the public cloud due to cost, latency, security or legal reasons. Think about smart factories as one example.
Multi-cluster and cross-data center deployments of Apache Kafka have become the norm rather than an exception. Several scenarios require multi-cluster solutions, including disaster recovery, aggregation for analytics, cloud migration, mission-critical stretched deployments and global Kafka. Learn more about this in the blog post “Architecture patterns for distributed, hybrid, edge, and global Apache Kafka deployments“.
Various AWS infrastructures enable the deployment of Kafka outside the public cloud. Confluent Platform is certified on AWS Outposts and therefore runs on various AWS hardware offerings.
Example 3: Hybrid Integration with Kafka-native Cluster Linking
Here is an example for brownfield modernization:
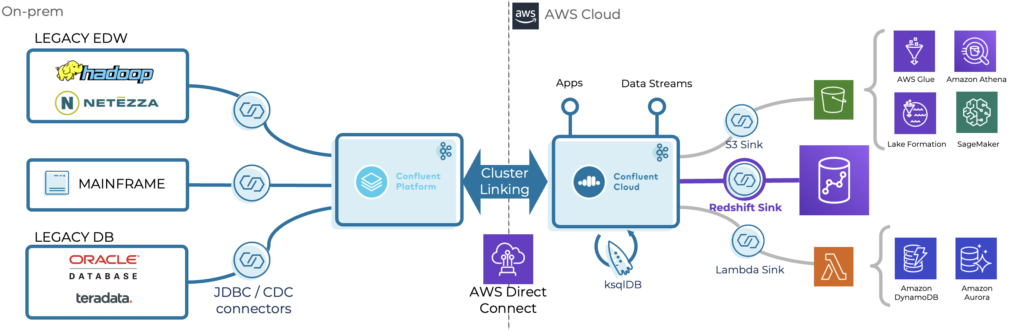
Connect
Pre-built connectors continuously bring valuable data from existing services on-prem, including enterprise data warehouse, databases, and mainframes. In addition, bi-directional communication is also possible where needed.
Bridge
Hybrid cloud streaming enables consistent, reliable replication in real-time to build a modern event-driven architecture for new applications and the integration with 1st and 3rd party SaaS interfaces.
Modernize
Public cloud infrastructure increases agility in getting applications to market and reduces TCO when freeing up resources to focus on value-generating activities and not managing servers.
Example 4: Low-Latency Kafka with Cloud-native 5G Infrastructure on AWS Wavelength
Low Latency data streaming requires infrastructure that runs close to the edge machines, devices, sensors, smartphones, and other interfaces. AWS Wavelength was built for these scenarios. The enterprise does not have to install its own IT infrastructure at the edge.
The following architecture shows an example built by Confluent, AWS, and Verizon:
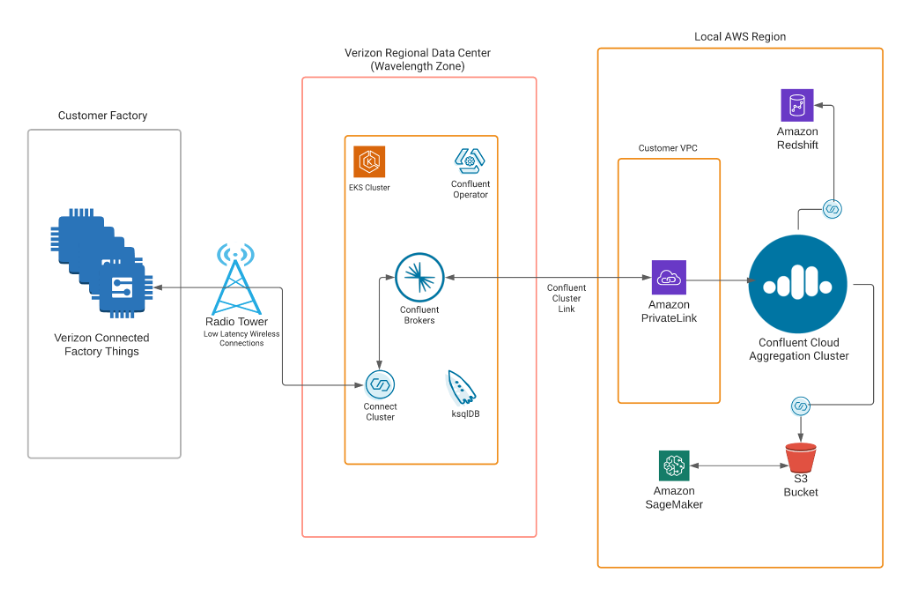
Learn more about low latency use cases for data in motion in the blog post “Low Latency Data Streaming with Apache Kafka and Cloud-Native 5G Infrastructure“.
Live Demo – Hybrid Cloud Replication
Here is a live demo I recorded to show the streaming replication between an on-premise Kafka cluster and Confluent Cloud, including stream processing with ksqlDB and data integration with Kafka Connect (using the fully-managed AWS S3 connector):
You are currently viewing a placeholder content from Default. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
Slides from Joint AWS + Confluent Webinar on Serverless Kafka
I recently did a webinar together with AWS to present the added value of combining Confluent and AWS services. This became a standard pattern in the last years for many transactional and analytical workloads.
Here are the slides:
You are currently viewing a placeholder content from Default. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
Reverse ETL and its Relation to Data Lakes and Kafka
To conclude this post, I want to explore one more term you might have heard about. The buzzword is still in the early stage, but more and more vendors pitch a new trend: Reverse ETL. In short, this means storing data in your favorite long-term storage (database / data warehouse / data lake / lake house) and then get the data out of there again to connect to other business systems.
In the Kafka world, this is the same as Change Data Capture (CDC). Hence, Reverse ETL is not a new thing. Confluent provides CDC connectors for the many relevant systems, including Oracle, MongoDB, and Salesforce.
As I mentioned earlier, data storage vendors try to get into the data in motion business. I am not sure where this will go. Personally, I am convinced that the event streaming platform is the right place in the enterprise architecture for processing data in motion. This way every application can consume the data in real-time – decoupled from another database or data lake. But the future will show. I thought it was a good ending to this blog post to clarify this new buzzword and its relation to Kafka. I wrote more about this topic in its own article: “Apache Kafka and Reverse ETL“.
Serverless and Cloud-native Kafka with AWS and Confluent
Cloud-first strategies are the norm today. Whether the use case is a new greenfield project, a brownfield legacy integration architecture, or a modern edge scenario with hybrid replication. Kafka became the de facto standard for processing data in motion. However, Kafka is just a piece of the puzzle. Most enterprises prefer a complete, cloud-native service.
AWS and Confluent are a proven combination for various use cases across industries to deploy and operate Kafka environments everywhere, including truly serverless Kafka in the public cloud and cloud-native Kafka outside the public cloud. Of course, while this post focuses on the relation between Confluent and AWS, Confluent has similar strong partnerships with GCP and Azure to provide data in motion on these hyperscalers, too.
How do you run Kafka in the cloud today? Do you operate it by yourself? Do you use a partially managed service? Or do you use a truly serverless offering? Are your projects greenfield, or do you use hybrid architectures? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.