
Apache Flink
Industrial enterprises face increasing pressure to move faster, automate more, and adapt to constant change—without compromising reliability. Siemens Digital Industries addresses this challenge by combining

Industrial enterprises face increasing pressure to move faster, automate more, and adapt to constant change—without compromising reliability. Siemens Digital Industries addresses this challenge by combining
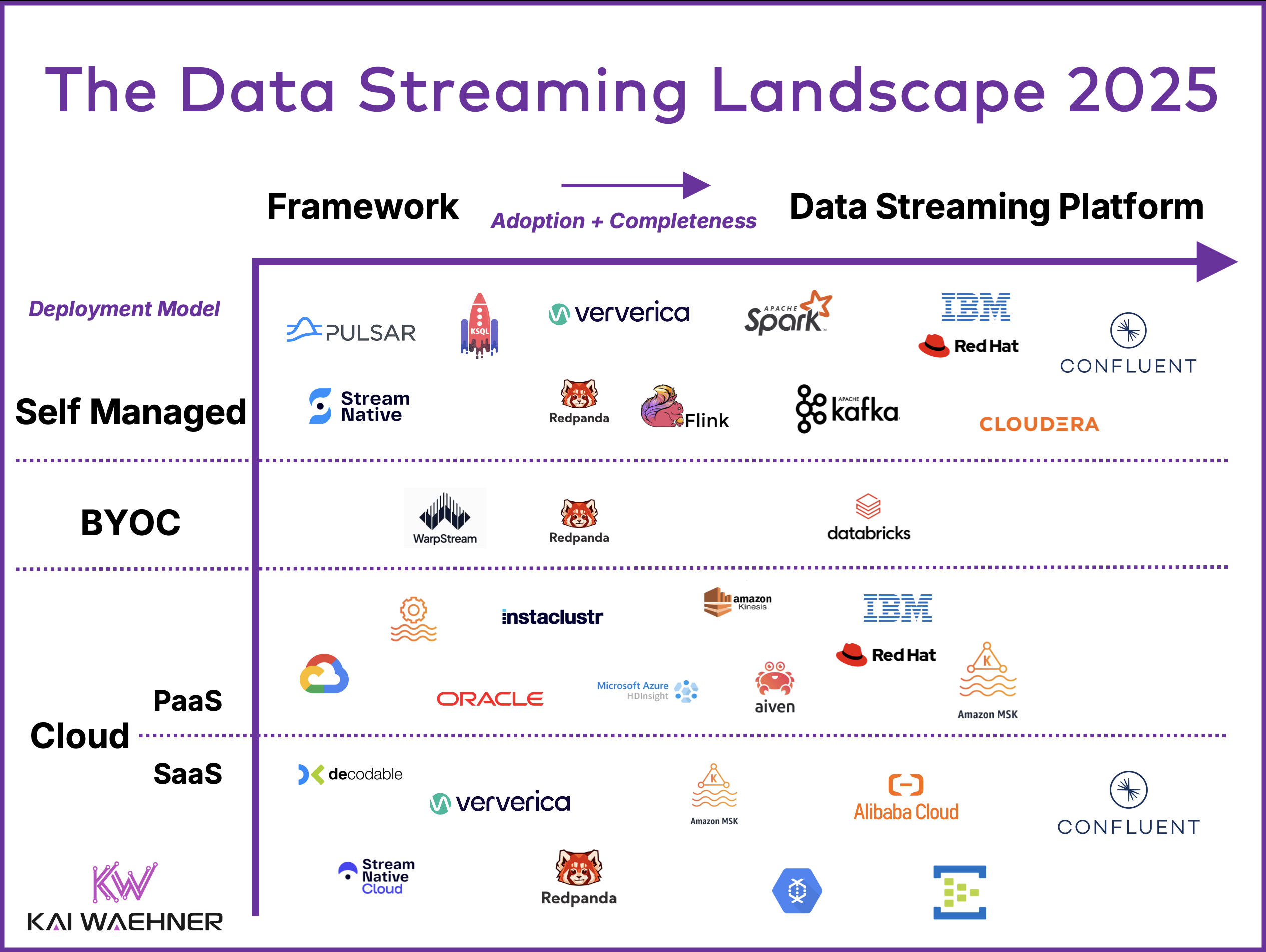
Data streaming is a new software category. It has grown from niche adoption to becoming a fundamental part of modern data architecture, leveraging open source
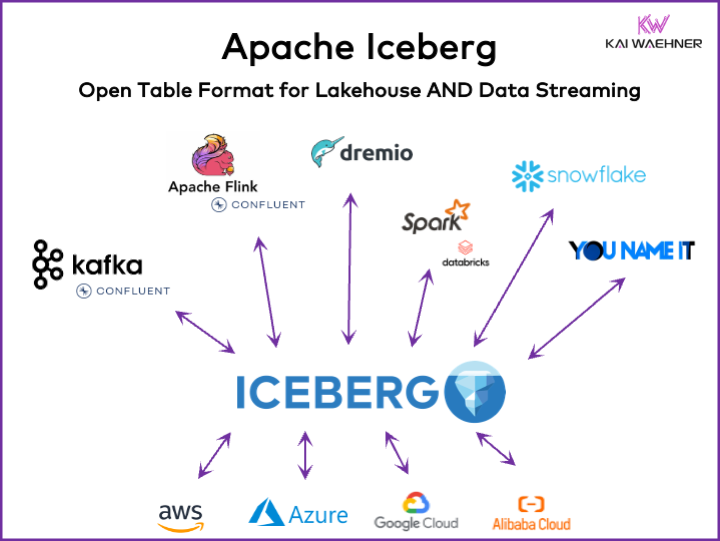
An open table format framework like Apache Iceberg is essential in the enterprise architecture to ensure reliable data management and sharing, seamless schema evolution, efficient

Snowflake is a leading cloud data warehouse and transitions into a data cloud that enables various use cases. The major drawback of this evolution is

Apache Kafka is the de facto standard for data streaming to process data in motion. With its significant adoption growth across all industries, I get

If there were a buzzword of the hour, it would undoubtedly be “data mesh”! This new architectural paradigm unlocks analytic and transactional data at scale
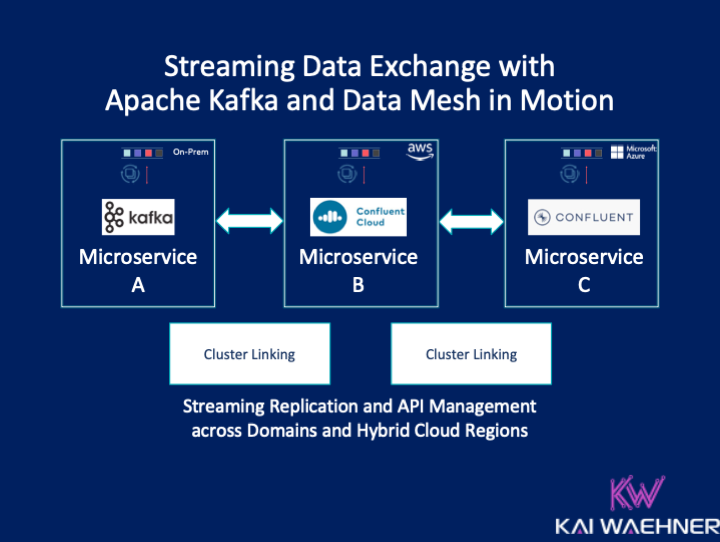
Data Mesh is a new architecture paradigm that gets a lot of buzzes these days. This blog post looks into this principle deeper to explore

This blog post explores why software vendors (try to) introduce new solutions for Reverse ETL, when Reverse ETL is really needed, and how it fits

Real-time data beats slow data. That’s true for almost every use case. Nevertheless, enterprise architects build new infrastructures with the Lambda architecture that includes separate




You need to load content from reCAPTCHA to submit the form. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Turnstile. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Vimeo. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from YouTube. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou need to load content from reCAPTCHA to submit the form. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Elfsight. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Facebook. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More Information