
Every data-driven organization has operational and analytical workloads. A best of breed approach emerges with various data platforms, including data streaming, data lake, data warehouse and lakehouse solutions and cloud services. An open table format framework like Apache Iceberg is essential in the enterprise architecture to ensure reliable data management and sharing, seamless schema evolution, efficient handling of large-scale datasets and cost-efficient storage while providing strong support for ACID transactions and time travel queries. This blog post explores market trends, adoption of table format frameworks like Iceberg, Hudi, Paimon, Delta Lake, XTable, and the product strategy of leading vendors of data platforms such as Snowflake, Databricks (Apache Spark), Confluent (Apache Kafka / Flink), Amazon Athena and Google BigQuery.
What is an Open Table Format for a Data Platform?
An open table format helps in maintaining data integrity, optimizing query performance, and ensuring a clear understanding of the data stored within the platform.
The open table format for data platforms typically includes a well-defined structure with specific components that ensure data is organized, accessible, and easily queryable. A typical table format contains a table name, column names, data types, primary and foreign keys, indexes, and constraints.
This is not a new concept. Your favourite decades-old database, like Oracle, IBM DB2 (even on the mainframe) or PostgreSQL, uses the same principles. However, the requirements and challenges changed a bit for cloud data warehouses, data lakes, lake houses regarding scalability, performance and query capabilities.
Benefits of a “Lakehouse Table Format” like Apache Iceberg
Every part of an organization becomes data-driven. The consequence is extensive data sets, data sharing with data products across business units, and new requirements for processing data in near real-time.
Apache Iceberg provides many benefits for the enterprise architecture:
- Single Storage: Data is stored once (coming from various data sources) reduces cost and complexity
- Interoperability: Access without integration efforts from any analytical engine
- All Data: Unify operational and analytical workloads (transactional systems, big data logs/IoT/clickstream, mobile APIs, 3rd party B2B interfaces, etc.)
- Vendor Independence: Work with any favorite analytics engine (no matter if it is near real-time, batch or API-based)
Apache Hudi and Delta Lake provide the same characteristics. Though, Delta Lake is mainly driven by Databricks as a single vendor.
Table Format AND Catalog Interface
It is important to understand that discussions about Apache Iceberg or similar table format frameworks include two concepts: Table Format AND Catalog Interface! As an end user of the technology, you need both!
The Apache Iceberg project implements the format but only provides a specification (but not implementation) for the catalog:
- The table format defines how data is organized, stored, and managed within a table.
- The catalog interface manages the metadata for tables and provides an abstraction layer for accessing tables in a data lake.
The Apache Iceberg documentation explores the concepts in much more detail, based on this diagram:
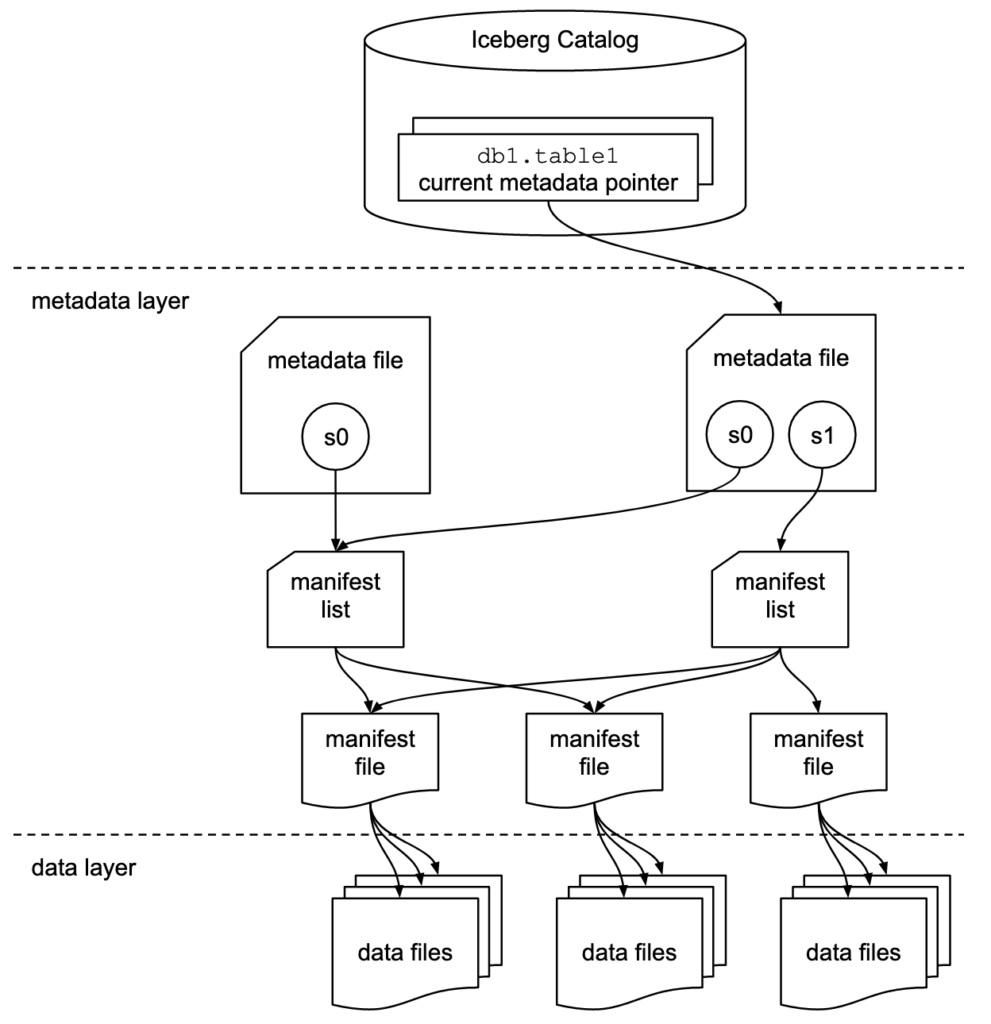
Organizations use various implementations for Iceberg’s catalog interface. Each integrates with different metadata stores and services. Key implementations include:
- Hadoop Catalog: Uses the Hadoop Distributed File System (HDFS) or other compatible file systems to store metadata. Suitable for environments already using Hadoop.
- Hive Catalog: Integrates with Apache Hive Metastore to manage table metadata. Ideal for users leveraging Hive for their metadata management.
- AWS Glue Catalog: Uses AWS Glue Data Catalog for metadata storage. Designed for users operating within the AWS ecosystem.
- REST Catalog: Provides a RESTful interface for catalog operations via HTTP. Enables integration with custom or third-party metadata services.
- Nessie Catalog: Uses Project Nessie, which provides a Git-like experience for managing data.
The momentum and growing adoption of Apache Iceberg motivates many data platform vendors to implement its own Iceberg catalog. I discuss a few strategies in the below section about data platform and cloud vendor strategies, including Snowflake’s Polaris, Databricks’ Unity, and Confluent’s Tableflow.
First-Class Iceberg Support vs. Iceberg Connector
Please note that supporting Apache Iceberg (or Hudi/Delta Lake) means much more than just providing a connector and integration with the table format via API. Vendors and cloud services differentiate by advanced features like automatic mapping between data formats, critical SLAs, travel back in time, intuitive user interfaces, and so on.
Let’s look at an example: Integration between Apache Kafka and Iceberg. Various Kafka Connect connectors were already implemented. However, here are the benefits of using a first-class integration with Iceberg (e.g., Confluent’s Tableflow) compared to just using a Kafka Connect connector:
- No connector config
- No consumption through connector
- Built-in maintenance (compaction, garbage collection, snapshot management)
- Automatic schema evolution
- External catalog service synchronization
- Simpler operations (in a fully-managed SaaS solution, it is serverless, with no need for any scale or operations by the end-user)
Similar benefits apply to other data platforms and potential first-class integration compared to providing simple connectors.
Open Table Format for a Data Lake / Lakehouse using Apache Iceberg, Apache Hudi, Delta Lake
The general goal of table format frameworks such as Apache Iceberg, Apache Hudi, and Delta Lake is to enhance the functionality and reliability of data lakes by addressing common challenges associated with managing large-scale data. These frameworks help to:
- Improve Data Management
- Facilitate easier handling of data ingestion, storage, and retrieval in data lakes.
- Enable efficient data organization and storage, supporting better performance and scalability.
- Ensure Data Consistency
- Provide mechanisms for ACID transactions, ensuring that data remains consistent and reliable even during concurrent read and write operations.
- Support snapshot isolation, allowing users to view a consistent state of data at any point in time.
- Support Schema Evolution
- Allow for changes in data schema (such as adding, renaming, or removing columns) without disrupting existing data or requiring complex migrations.
- Optimize Query Performance
- Implement advanced indexing and partitioning strategies to improve the speed and efficiency of data queries.
- Enable efficient metadata management to handle large datasets and complex queries effectively.
- Enhance Data Governance
- Provide tools for better tracking and managing data lineage, versioning, and auditing, which are crucial for maintaining data quality and compliance.
By addressing these goals, table format frameworks like Apache Iceberg, Apache Hudi, and Delta Lake help organizations build more robust, scalable, and reliable data lakes and lakehouses. Data engineers, data scientists and business analysts leverage analytics, AI/ML or reporting/visualization tools on top of the table format to manage and analyze large volumes of data.
Comparison of Apache Iceberg, Hudi, Paimon, Delta Lake?
I won’t do a comparison of the different table format frameworks Apache Iceberg, Apache Hudi, Apache Paimon and Delta Lake here. Many experts wrote about this already. Each table format framework has unique strengths and benefits. But updates are required every month because of the fast evolution and innovation, adding new improvements and capabilities within these frameworks.
Here is a summary of what I see in various blog posts about the three alternatives:
- Apache Iceberg: Excels in schema and partition evolution, efficient metadata management, and broad compatibility with various data processing engines.
- Apache Hudi: Best suited for real-time data ingestion and upserts, with strong change data capture capabilities and data versioning.
- Apache Paimon: A lake format that enables building a real-time lakehouse architecture with Flink and Spark for both streaming and batch operations.
- Delta Lake: Provides robust ACID transactions, schema enforcement, and time travel features, making it ideal for maintaining data quality and integrity.
A key decision point might be that Delta Lake is not driven by a broad community like Iceberg and Hudi, but mainly by Databricks as a single vendor behind it.
Apache XTable as Interoperable Cross-Table Framework supporting Iceberg, Hudi and Delta Lake
Users have lots of choices. XTable is yet another incubating table framework under Apache open source license to seamlessly interoperate cross-table between Apache Hudi, Delta Lake, and Apache Iceberg.
Apache XTable:
- provides cross-table omnidirectional interoperability between lakehouse table formats.
- is NOT a new or separate format, Apache XTable provides abstractions and tools for the translation of lakehouse table format metadata.
- is formerly known as OneTable.
Maybe Apache XTable is the answer to provide options for specific data platforms and cloud vendors but still provide simple integration and interoperability.
But be careful: A wrapper on top of different technologies is not a silver bullet. We saw this years ago when Apache Beam emerged. Apache Beam is an open source, unified model and set of language-specific SDKs for defining and executing data ingestion and data processing workflows. It supports a variety of stream processing engines, such as Flink, Spark, Samza. The primary driver behind Apache Beam is Google to allow the migration workflows into Google Cloud Dataflow. However, the limitations are huge, as such a wrapper needs to find the least common denominator supporting features. And most frameworks’ key benefit is the twenty percent that do not fit into such a wrapper. For these reasons, for instance, Kafka Streams does intentionally not support Apache Beam because it would have required too many design limitations.
Market Adoption of Table Format Frameworks
FIrst of all, we are still in the early stages. We are still at the innovation trigger in terms of the Gartner Hype Cycle, coming to the peak of inflated expectations. Most organizations are still evaluating, but not adopting these table formats in production across the organization yet.
Flashback: Container Wars – Kubernetes vs. Mesosphere vs. Cloud Foundry
The debate round Apache Iceberg reminds me of the container wars a few years ago. The term “Container Wars” refers to the competition and rivalry among different containerization technologies and platforms in the realm of software development and IT infrastructure.
The three competing technologies were Kubernetes, Mesosphere and Cloud Foundry. Here is where it went:
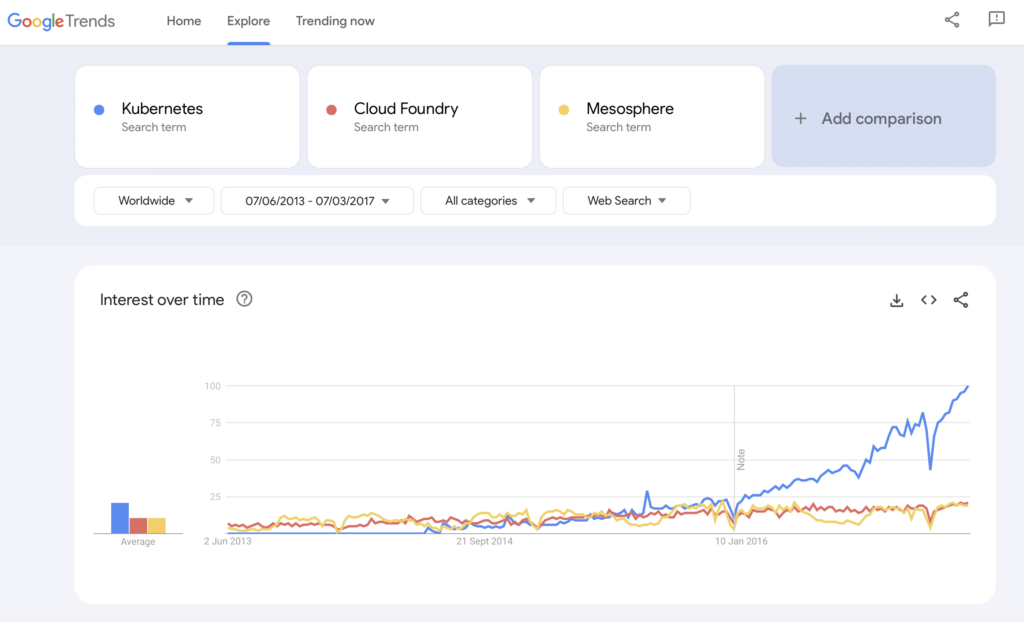
Cloud Foundry and Mesosphere were early. Kubernetes still won the battle. Why? I never understood all the technical details and differences. In the end, if the three frameworks are pretty similar, it is all about community adoption, the right timing of feature releases, good marketing, luck, and a few other factors. But it is good for the software industry to have one leading open source framework to build solutions and business models on, instead of three competing ones.
Present: Table Format Wars – Apache Iceberg vs. Hudi vs. Delta Lake
Obviously, Google Trends is no statistical evidence or sophisticated research. But I used it a lot in the past as an intuitive, simple, free tool to analyze market trends. Therefore, I also use this tool to see if Google searches overlap with my personal experience of the market adoption of Apache Iceberg, Hudi and Delta Lake (Apache XTable is too small yet to be added):
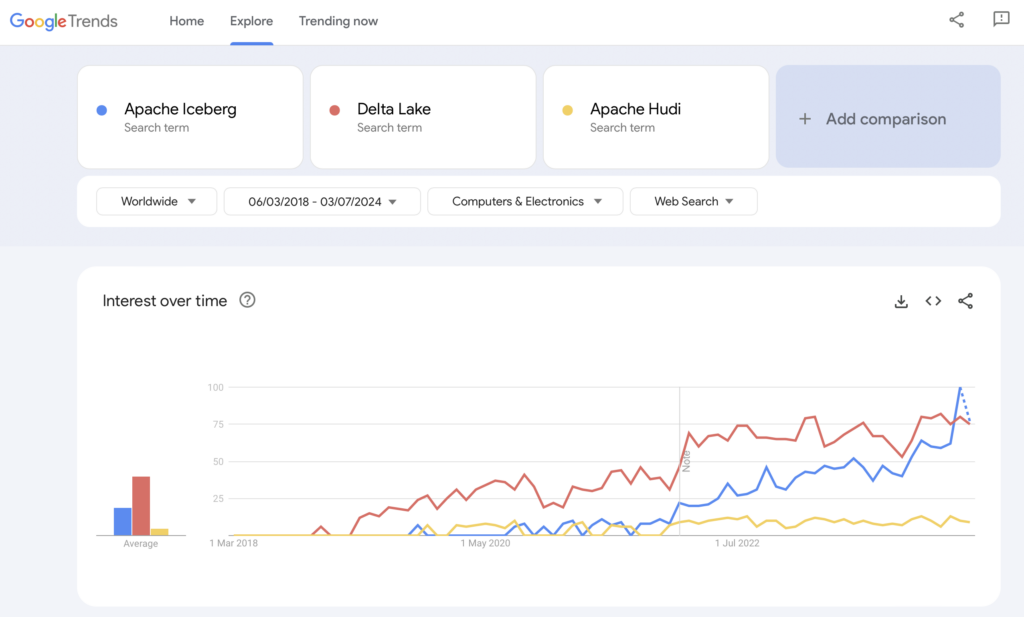
We obviously see a similar pattern as the container wars showed a few years ago. I have no idea where this is going. And if one technology wins, or if the frameworks differentiate enough to prove that there is no silver bullet. The future will show us.
My personal opinion? I think Apache Iceberg will win the race. Why? I cannot argue with any technical reasons. I just see many customers across all industries talk about it more and more. And more and more vendors start supporting it. But we will see. I actually do NOT care who wins. However, similarly to the container wars, I think it is good to have a single standard and vendors differentiating with features around it, like it is with Kubernetes.
But with this in mind, let’s explore the current strategy of the leading data platforms and cloud providers regarding table format support in their platforms and cloud services.
Data Platform and Cloud Vendor Strategies for Apache Iceberg
I won’t do any speculation in this section. The evolution of the table format frameworks moves quickly. And vendor strategies change quickly. Please refer to the vendor’s websites for the latest information. But here is a status quo about the data platform and cloud vendor strategies regarding the support and integration of Apache Iceberg.
- Snowflake:
- Supports Apache Iceberg for quite some time already
- Adding better integrations and new features regularly
- Internal and external storage options (with trade-offs) like Snowflake’s storage or Amazon S3
- Announced Polaris, an open source catalog implementation for Iceberg, with commitment to support community-driven, vendor-agnostic bi-directional integration
- Databricks:
- Focuses on Delta Lake as the table format and (now open sourced) Unity as catalog
- Acquired Tabular, the leading company behind Apache Iceberg
- Unclear future strategy of supporting open Iceberg interface (in both directions) or only to feed data into its lakehouse platform and technologies like Delta Lake and Unity Catalog
- Confluent:
- Embeds Apache Iceberg as a first-class citizen into its data streaming platform (the product is called Tableflow)
- Converts a Kafka Topic and related schema metadata (i.e., data contract) into an Iceberg table
- Bi-directional integration between operational and analytical workloads
- Analytics with embedded serverless Flink and its unified batch and streaming API or data sharing with 3rd party analytics engines like Snowflake, Databricks or Amazon Athena
- More Data Platforms and Open Source Analytics Engines:
- The list of technologies and cloud services supporting Iceberg grows every month
- A few examples: Apache Spark, Apache Flink, ClickHouse, Dremio, Starburst using Trino (formerly PrestoSQL), Cloudera using Impala, Imply using Apache Druid, Fivetran
- Cloud Service Providers (AWS, Azure, GCP, Alibaba):
- Different strategies and integrations, but all cloud providers increase Iceberg support across their services these days, for instance:
- Object Storage: Amazon S3, Azure Data Lake Storage (ALDS), Google Cloud Storage (GCS)
- Catalogs: Cloud-specific like AWS Glue Catalog or vendor agnostic like Project Nessie or Hive Catalog
- Analytics: Amazon Athena, Azure Synapse Analytics, Microsoft Fabric, Google BigQuery
The Shift Left Architecture with Kafka, Flink and Iceberg to Unify Operational and Analytical Workloads
The Shift Left Architecture moves data processing closer to the data source, leveraging real-time data streaming technologies like Apache Kafka and Flink to process data in motion directly after it is ingested. This approach reduces latency and improves data consistency and data quality.
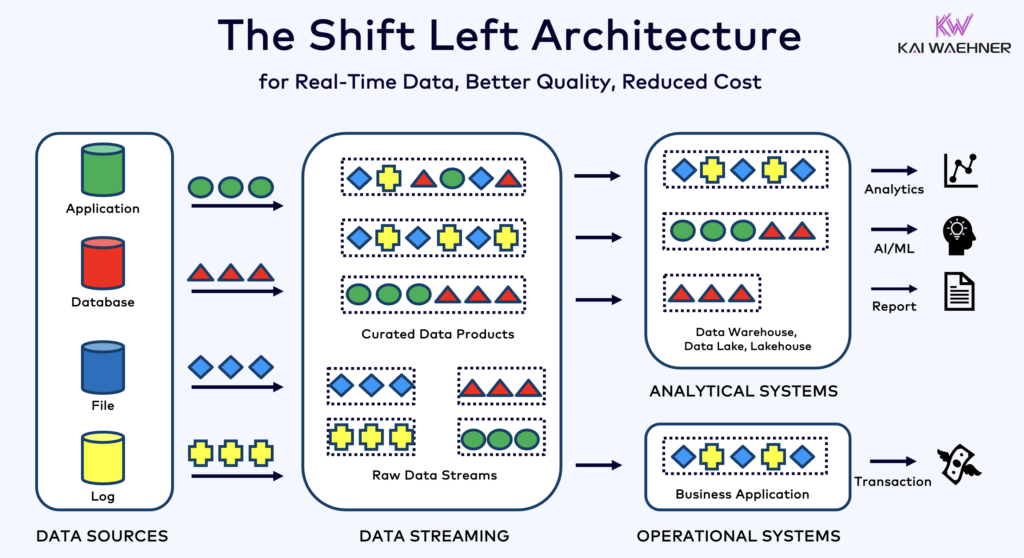
Unlike ETL and ELT, which involve batch processing with the data stored at rest, the Shift Left Architecture enables real-time data capture and transformation. It aligns with the Zero ETL concept by making data immediately usable. But in contrast to Zero ETL, shifting data processing to the left side of the enterprise architecture avoids a complex, hard-to-maintain spaghetti architecture with many point-to-point connections.
The Shift Left Architecture also reduces the need for Reverse ETL by ensuring data is actionable in real-time for both operational and analytical systems. Overall, this architecture enhances data freshness, reduces costs, and speeds up the time-to-market for data-driven applications. Learn more about this concept in my blog post about “The Shift Left Architecture“.
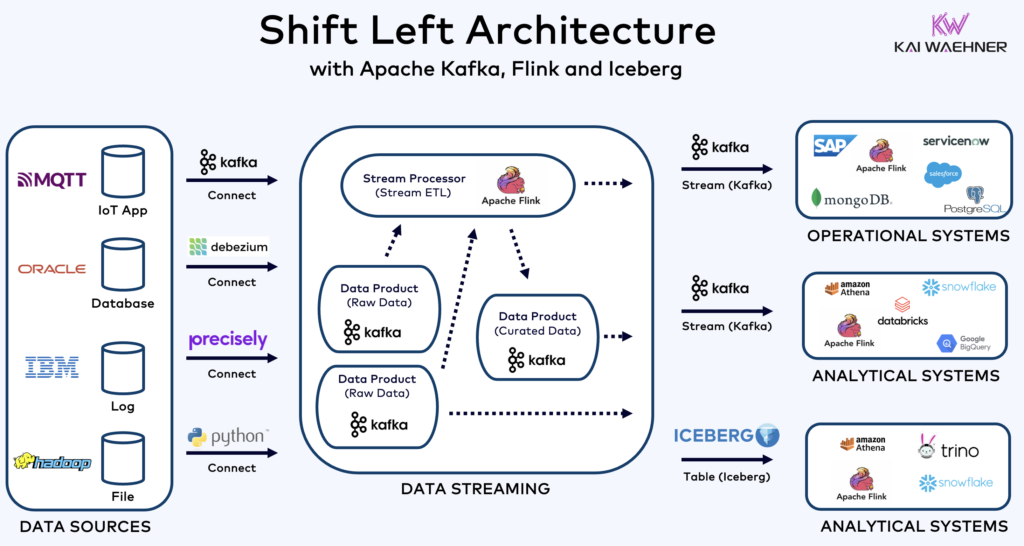
Apache Iceberg as Open Table Format and Catalog for Seamless Data Sharing across Analytics Engines
An open table format and catalog introduces enormous benefits into the enterprise architecture: interoperability, freedom of choice of the analytics engines, faster time-to-market and reduced cost.
Apache Iceberg seems to become the de facto standard across vendors and cloud providers. However, it is still at an early stage and competing and wrapper technologies like Apache Hudi, Apache Paimon, Delta Lake and Apache XTable are trying to get momentum, too.
Iceberg and other open table formats are not just a huge win for the single storage and integration with multiple analytics / data / AI/ML platforms such as Snowflake, Databricks, Google BigQuery, et al., but also for the unification of operational and analytical workloads using data streaming with technologies such as Apache Kafka and Flink. The Shift Left Architecture is a significant benefit to reduce efforts, improve data quality and consistency, and enable real-time instead of batch applications and insights.
Finally, if you still wonder what the differences are between data streaming and lakehouses (and how they complement each other), check out this ten minute video:
You are currently viewing a placeholder content from YouTube. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
What is your table format strategy? Which technologies and cloud services do you connect? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.
