
Most enterprises store their massive volumes of transactional and analytics data at rest in data warehouses or data lakes. Sales, marketing, and customer success teams require access to these data sets. Reverse ETL is a buzzword that defines the concept of collecting data from existing data stores to provide it easy and quick for business teams.
This blog post explores why software vendors (try to) introduce new solutions for Reverse ETL, when it is needed, and how it fits into the enterprise architecture. The involvement of event streaming with tools like Apache Kafka to process data in motion is a crucial piece of Reverse ETL for real-time use cases.

What are ETL and Reverse ETL?
Let’s begin with the terms. What do ETL and Reverse ETL mean?
ETL (Extract-Transform-Load)
Extract-Transform-Load (ETL) is a common term for data integration. Vendors like Informatica or Talend provide visual coding to implement robust ETL pipelines. The cloud brought new SaaS players and the term Integration Platform as a Service (iPaaS) into the ETL market with vendors such as Boomi, SnapLogic, or Mulesoft Anypoint.
Most ETL tools operate in batch processes for big data workloads or use SOAP/REST web services and APIs for non-scalable real-time communication. ETL pipelines consume data from various data sources, transform or aggregate it, and store the processed data at rest in data sinks such as databases, data warehouses, or data lakes:
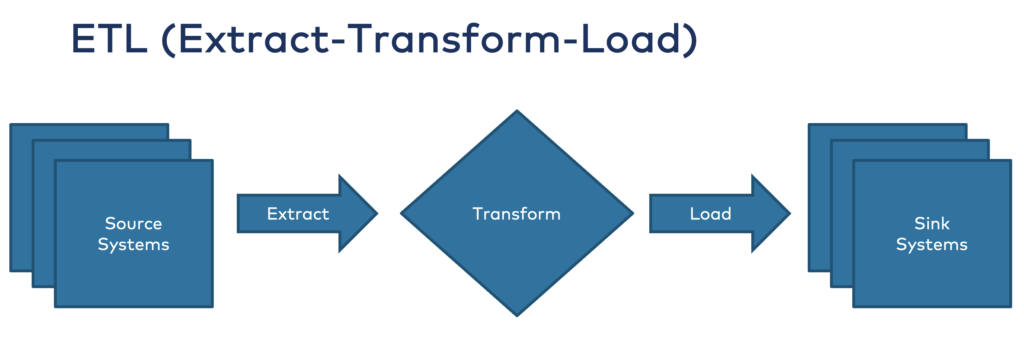
ELT (Extract-Load-Transform)
Extract-Load-Transform (ELT) is a very similar approach. However, the transformations and aggregations happen after the ingestion into the datastore:
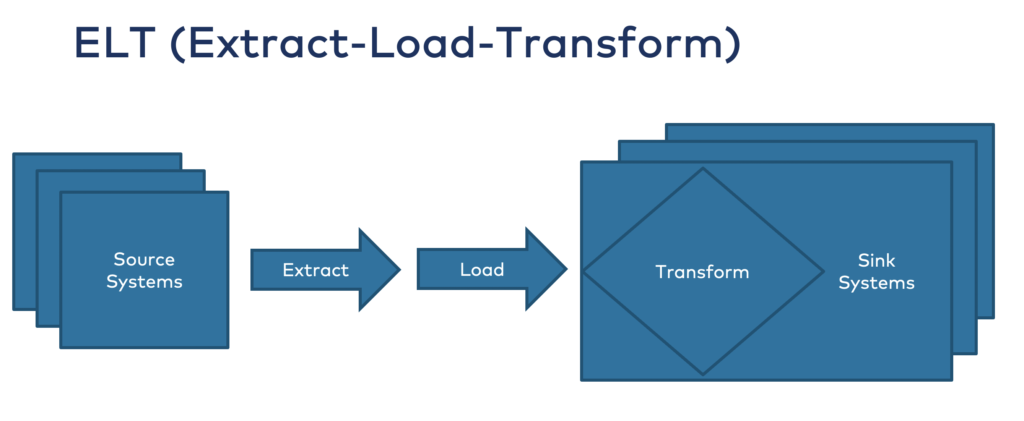
It is no surprise that modern data storage and analytics vendors such as Databricks and Snowflake promote the ELT approach. For instance, Snowflake pitches the “internal dash mesh” where all the domains and data products are built within their cloud service.
Reverse ETL
As the name says, Reverse ETL turns the story from ETL around. It means the process of moving data from a data store into third-party systems to “make data operational”, as the marketing of these solutions says:
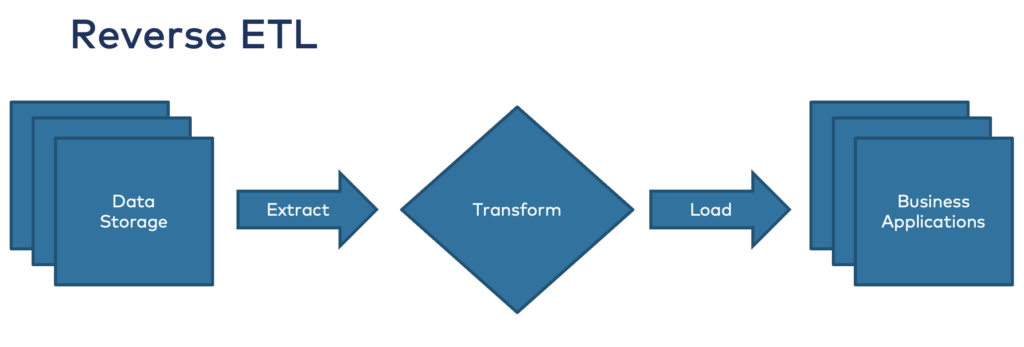
The data is consumed from long-term storage systems (data warehouse, data lake). The data is then pushed into business applications such as Salesforce (CRM), Marketo (marketing), or Service Now (customer success) to leverage it for pipeline generation, marketing campaigns, or customer communication.
Products and SaaS Offerings for Reverse ETL
Just google for “Reverse ETL” to find vendors specifically pitching their solutions. They also pay ads for the “normal data integration terms”. Therefore, the chances are high that you already saw them even if you did not search for them. 🙂
Most of these companies are young companies and startups building a new business around Reverse ETL products. Software vendors I found in my research include Hightouch, Census, Grouparoo (open source), Rudderstack, Omnata, and Seekwell.
Fun fact: If you search for Snowflake’s Reverse ETL, you will not find any google hit as they want to keep the data in their data warehouse.
A key strength and selling point of all ETL tools is visual coding, and therefore time to market for the development and maintenance of ETL pipelines. Some solutions target the citizen integrator (a term coined by Gartner), i.e., businesspeople building their integrations.
Reverse ETL == Real-Time Data for Sales, Marketing, Customer Success
Most Reverse ETL success stories talk about focus on sales, marketing, or customer success. These use cases attract business divisions. These teams do not want to buy a technical ETL tool like Informatica or Talend. Business people expect straightforward and intuitive user interfaces, like a citizen integrator.
The vendors target the businesspeople and promise a simplified technical infrastructure. For instance, one vendor promotes “Cut out legacy middleware and reduce ETL jobs”. My first thought: Welcome, shadow IT!
Nevertheless, let’s take a look at the use cases for Reverse ETL:
- Identify customers at-risk and potential customer churn before it happens
- Drive new sales by correlating data from the CRM and other interfaces
- Hyper-personalized marketing for cross-selling and upselling to existing customers
- Operational analytics to monitor the changes in business applications and data faster
- Data replication to modern cloud applications for better reporting capabilities and finding insights
Additionally, all of the vendors also talk about real-time data for the above use cases. That’s great. BUT: Unfortunately, Reverse ETL is a huge ANTI-PATTERN to build real-time use cases. Let’s explore in more detail why.
Reverse ETL + Data Lake + Real-Time == Myth
Those use cases described above are great with tremendous business value. If you follow my blog or presentations, you have probably seen precisely the same real-time use cases built natively with event streaming processing data in motion.
If you store data in a data warehouse or data lake, you cannot process it in real-time anymore as it is already stored at rest. These data stores are built for indexing, search, batch processing, reporting, model training, and other use cases that make sense in the storage system. But you cannot consume the data in real-time in motion from storage at rest:
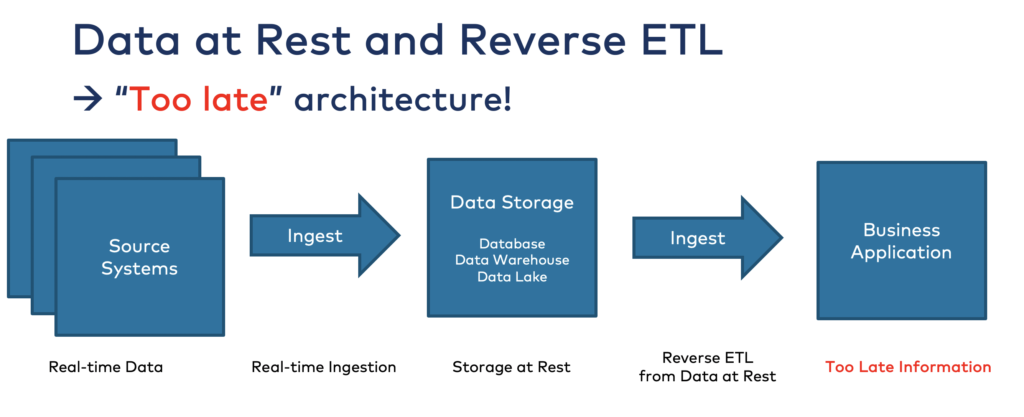
That’s where event streaming comes into play. Platforms like Apache Kafka enable processing data in motion in real-time for transactional and analytical workloads.
So, let’s take a look at a modern enterprise architecture that leverages event streaming for data processing in motion AND a data warehouse or data lake for data processing at rest.
Reverse ETL in the Enterprise Architecture
Let’s explore how Reverse ETL fits into the enterprise architecture and when you need a separate tool for this. For this, let’s go one step back first. What does Reverse ETL do? It takes data out of the storage, transforms or aggregates the data, and then ingests it into business applications.
Two options exist for Reverse ETL: SQL queries and Change Data Capture (CDC).
Reverse ETL == SQL Queries vs Change Data Capture
If a Reverse ETL tool uses SQL, then it is usually a query to data at rest. This use case enables businesspeople to create queries in intuitive user interfaces. Use cases include the creation of new marketing campaigns or analyze the customer success journey. SQL-based Reverse ETL requires intuitive tools that are simple to use.
If a Reverse ETL tool provides real-time data correlation and push notifications, it uses change data capture (CDC). CDC is automated and enables acting on changes in the data storage in real-time. The pipeline includes data correlation from different data sources and sending real-time push messages into business applications. CDC-based Reverse ETL requires a scalable, reliable event streaming infrastructure.
As you can see, both SQL and CDC approaches have their use cases and sometimes overlap in tooling and infrastructure. Change-log-based CDC is often the preferred technical approach instead of synchronizing data on a recurring schedule with SQL or when triggering by calling an API, no matter if you use “just” an event streaming platform or a particular Revere ETL product.
However, the more important question is how to design an enterprise architecture to AVOID the need for Reverse ETL.
Event-driven Architecture + Streaming ETL == Reverse ETL built-in
Real-time data beats slow data. That’s true for most use cases. Hence, the rise of event-driven architectures is unstoppable:
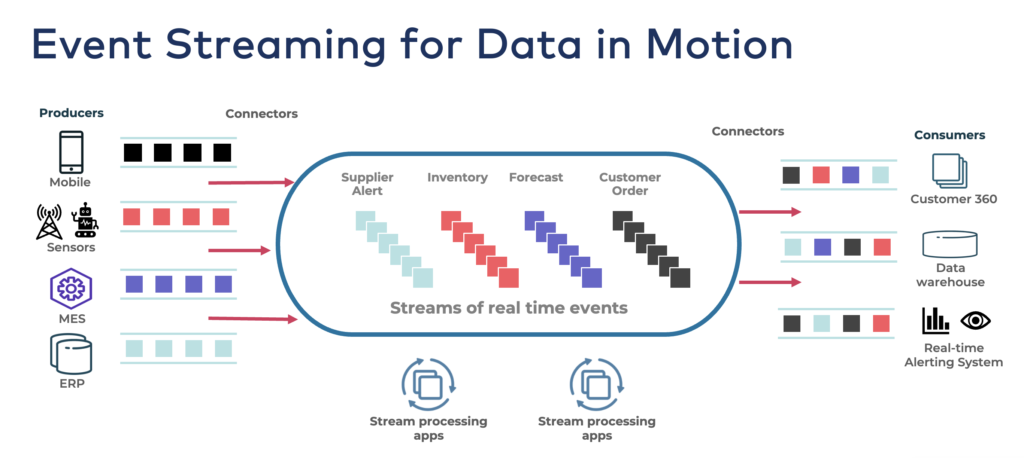
Reverse ETL is not needed in modern event-driven architecture! It is “built-in” into the architecture out-of-the-box. Each consumer directly consumes the data in real-time if it is appropriate and technically feasible. And data warehouses or data lakes still consume it in their own pace in near-real-time or batch:
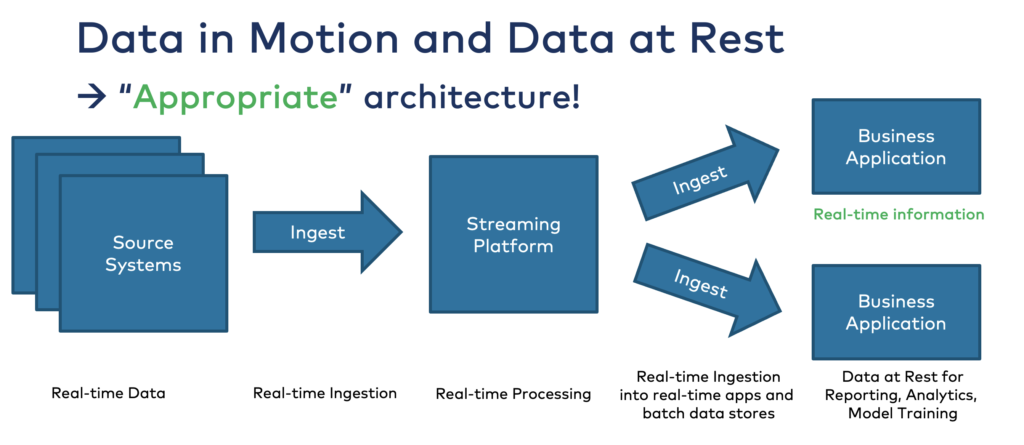
The Kafka-native streaming SQL engine ksqlDB provides CDC capabilities and continuous stream processing. Therefore, you could even call ksqlDB a Reverse ETL tool if your marketing asks for it.
If you want to learn more about building real-time data platforms, check out the article “Kappa architecture is mainstream replacing Lambda“. It explores how companies like Uber, Shopify, and Disney built an event-driven Kappa architecture for any use case, including real-time, near-real-time, batch, and request-response.
When do you need Reverse ETL?
A greenfield architecture built from the ground up with an event streaming platform at its heart does not need Reverse ETL to consume data from a data warehouse or data lake as every consumer can already consume the data in real-time.
However, providing an interface for business users is NOT solved out-of-the-box with an event streaming platform like Apache Kafka. You need to add additional tools like Kafka CDC connectors, or 3rd party tools with intuitive user interfaces.
Hence, Reverse ETL can be helpful in two scenarios: Brownfield integration and simple tools for business users.
Brownfield architectures where data is stored at rest and businesspeople need to consume it in business applications. Data needs to be pushed out of the data storage for sales, marketing, or customer success use cases:
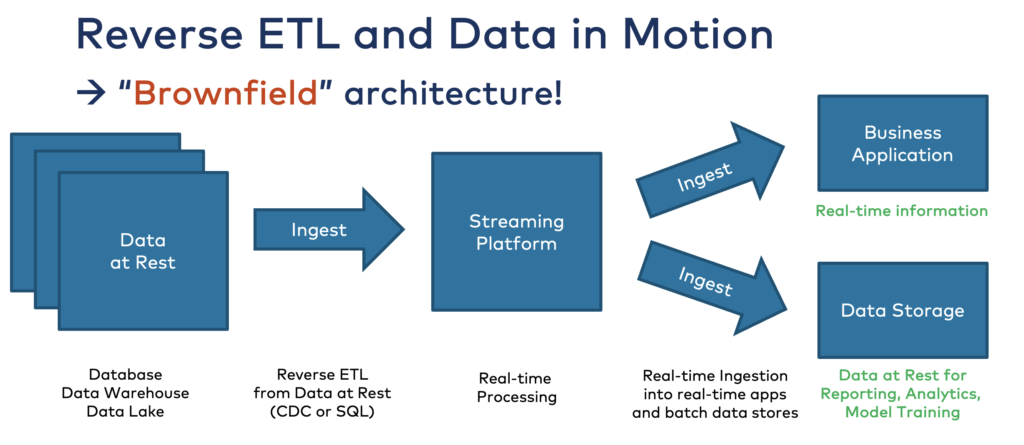
Simple integration tools for business people are much more intuitive and easy to use than traditional ETL and iPaaS solutions. Even in a greenfield approach, Reverse ETL tools might still be the easiest solution and provide the best time to market.
Also, keep in mind that modern tools such as Salesforce or SAP provide event-based interfaces already. Data storage vendors such as Elastic, Splunk, or Snowflake also heavily invest in streaming layers to natively integrate with tools such as Apache Kafka. The integration with business applications is possible via event streaming in real-time instead of integration via Reverse ETL from the data store.
For these reasons, evaluate your business problem and if you need an event streaming platform, a Reverse ETL tool, or a combination of both.
Kafka Examples for Reverse ETL
Let’s take a look at two concrete examples.
Apache Kafka + Salesforce + Oracle CDC + Snowflake
The following architecture combines real-time data streaming, change data capture, data lake, and a Reverse ETL cloud service:
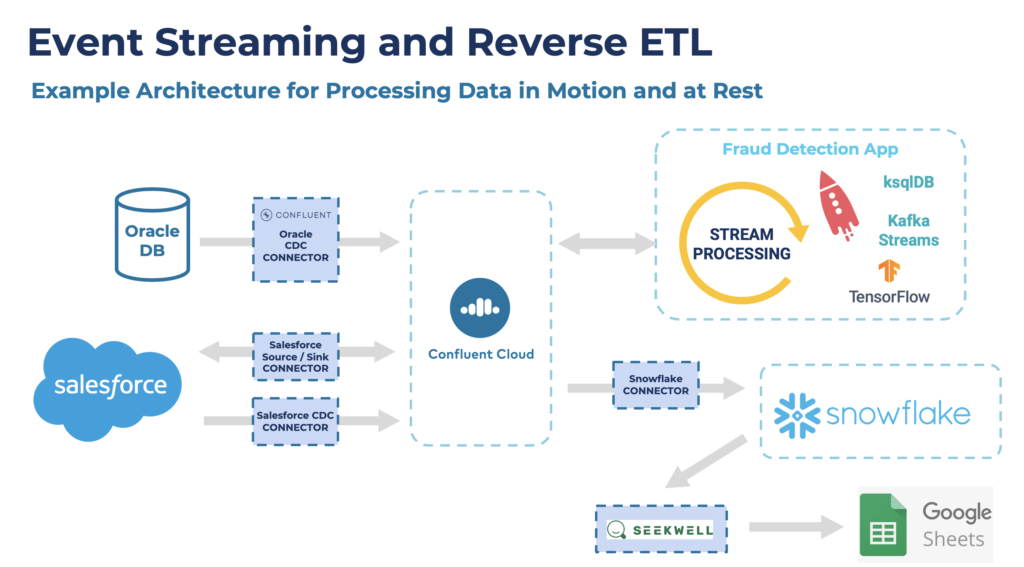
A few notes on this architecture:
- The central nervous system is an event streaming platform (Confluent Cloud) that provides scalable real-time data streaming and true decoupling between any data source and sink.
- A SaaS cloud service (Salesforce) natively provides an asynchronous API for event-based real-time integration.
- A traditional relational database (Oracle) is integrated with Reverse ETL via change data capture using Confluent’s Oracle CDC connector for Kafka Connect.
- Data from all the data sources are processed continuously with stream processing tools such as Kafka Streams and ksqlDB.
- Data ingestion into a data warehouse (Snowflake) configured as part of Confluent Cloud’s fully managed Kafka Connect connector.
- A business user leverages a dedicated Reverse ETL solution (Seekwell) for getting data out of the data warehouse (Snowflake) into a business application (Google Sheets).
The whole infrastructure provides an event-based, scalable, reliable real-time nervous system. Each application can consume and process data in motion in real-time (if needed). Data storage at rest is complementary for batch use cases and integrated with the event-based platform.
TL;DR: This architecture truly decouples applications, avoids point-to-point spaghetti communication, and supports all technologies, cloud services, and communication paradigms.
Tapping into the Splunk Ingestion Layer in Motion with Kafka
Another option of avoiding the need for Reverse ETL from a storage system is tapping into the existing storage ingestion layer.
Confluent’s Splunk S2S connector is a great example. Suppose organizations already have hundreds or thousands of universal forwarders (UF) and heavy forwarders (HF). In that case, this approach allows users to cost-effectively and reliably read data from Splunk Forwarders to Kafka. It enables users to forward data from universal forwarders into a Kafka topic to unlock the analytical capabilities of the data:
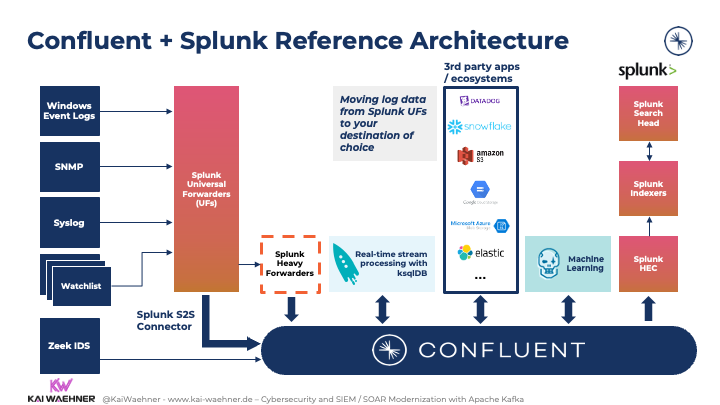
For more details about this use case, check out my blog “Apache Kafka in Cybersecurity for SIEM / SOAR Modernization“.
Don’t Design for Data at Rest to Reverse it!
Good enterprise architecture should never have the goal to plan for reverse ETL from the beginning! It is only needed in brownfield architecture where the data is stored at rest instead of building an event-based architecture for real-time and batch data sinks. Reverse ETL enables Shadow IT and spaghetti architectures. Event streaming enables data integration in real-time by nature.
Nevertheless, Reverse ETL tooling is appropriate for brownfield approaches (ideally via continuous change data capture, not recurring SQL) or if business users need a simple, intuitive user interface. Hence, event streaming and Reverse ETL are complementary. In the same way, event streaming and data warehouses/data lakes are complementary. Read this if you want to learn more: “Serverless Kafka in a Cloud-native Data Lake Architecture“.
What is your point of view on this new ETL buzzword? How do you integrate it into an enterprise architecture? What are your experiences and opinions? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.
