
If there were a buzzword of the hour, it would undoubtedly be “data mesh“! This new architectural paradigm unlocks analytic and transactional data at scale and enables rapid access to an ever-growing number of distributed domain datasets for various usage scenarios. The data mesh addresses the most common weaknesses of the traditional centralized data lake or data platform architecture. And the heart of a decentralized data mesh infrastructure must be real-time, reliable, and scalable. Learn how the de facto standard for data streaming, Apache Kafka, plays a crucial role in building a data mesh.

There is no single technology or product for a data mesh!
This post explores how Apache Kafka, as an open and scalable decentralized real-time platform, can be the basis of a data mesh infrastructure and – complemented by many other data platforms like a data warehouse, data lake, and lakehouse – solve real business problems.
There is no silver bullet or single technology/product/cloud service for implementing a data mesh. The key outcome of a data mesh architecture is the ability to build data products; with the right tool for the job. A good data mesh combines data streaming technology like Apache Kafka or Confluent Cloud with cloud-native data warehouse and data lake architectures from Snowflake, Databricks, Google BigQuery, et al.
What is a data mesh?
I won’t write yet another article describing the concepts of a data mesh. Zhamak Dehghani coined the term in 2019. The following data mesh architecture from 30,000-foot view explains the basic idea well:
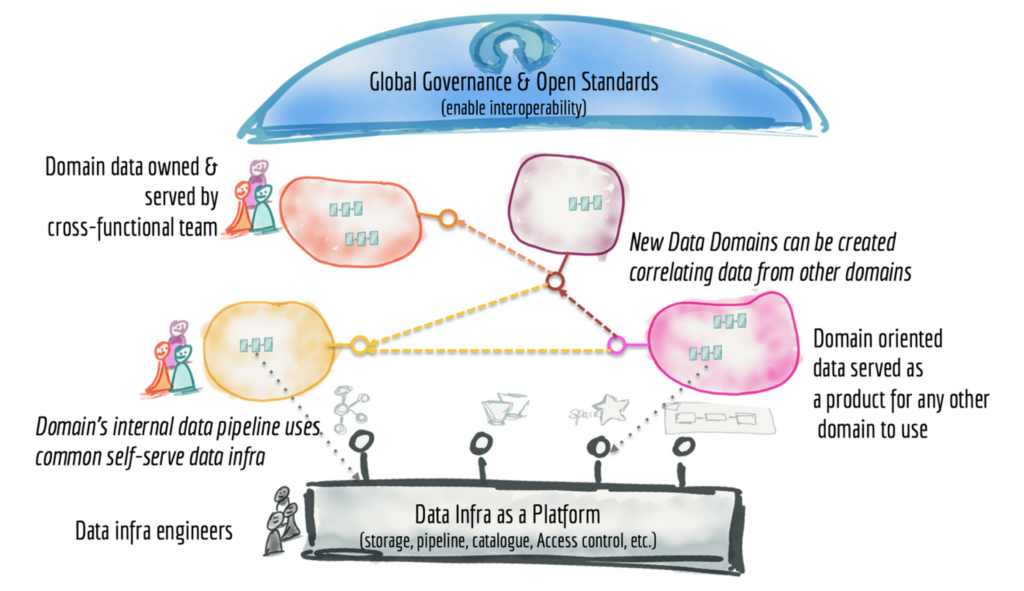
I summarize data mesh as the following three bullet points:
- An architecture paradigm with several historical influences (domain-driven design, microservices, data marts, data streaming)
- Not specific to a single technology or product; no single vendor can implement a data mesh alone
- Handling data as a product is a fundamental change, enabling a more flexible architecture and independent solving of separate business problems
- Decentralized services, not just analytics but also transactional workloads
Why handle data as a product?
Talking about innovative technology is insufficient to introduce a new architectural paradigm. Consequently, measuring the business value of the enterprise architecture is critical, too.
McKinsey finds that “when companies instead manage data like a consumer product—be it digital or physical—they can realize near-term value from their data investments and pave the way for quickly getting more value tomorrow. Creating reusable data products and patterns for piecing together data technologies enables companies to derive value from data today and tomorrow”:
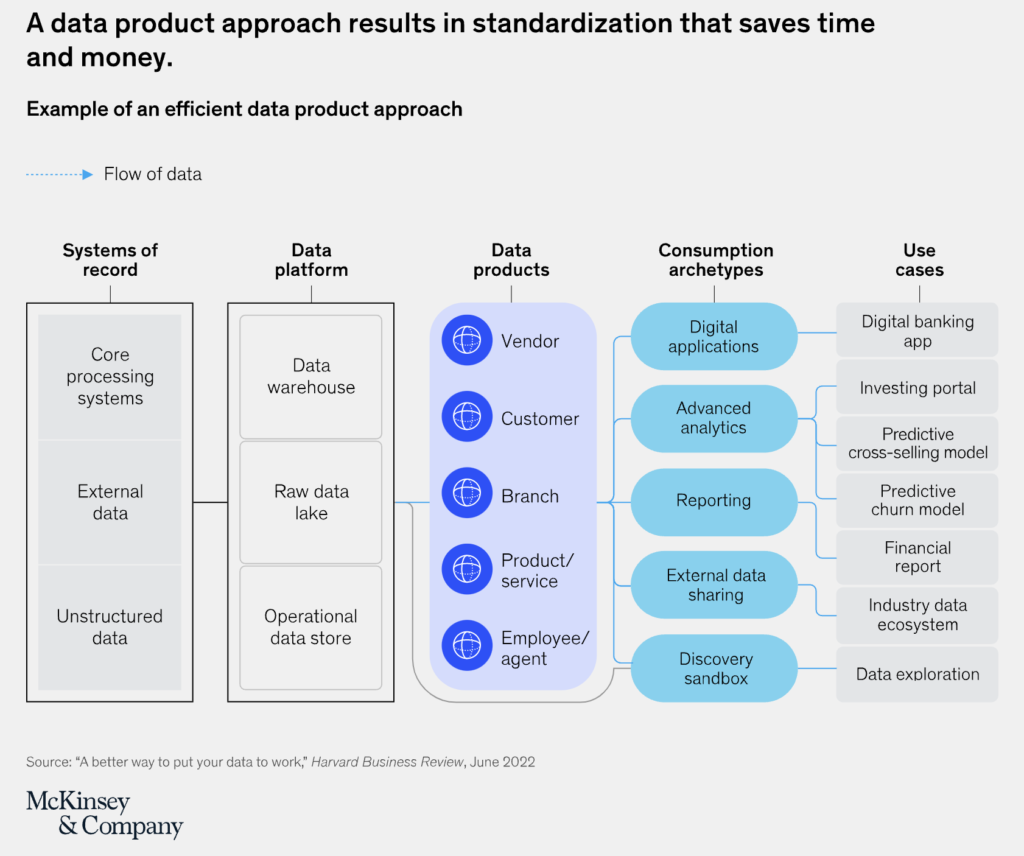
For McKinsey, the benefits of this approach can be significant:
- New business use cases can be delivered as much as 90 percent faster.
- The total cost of ownership, including technology, development, and maintenance, can decline by 30 percent.
- The risk and data-governance burden can be reduced.
What is data streaming with Apache Kafka and its relation to data mesh?
A data mesh enables flexibility through decentralization and best-of-breed data products. The heart of data sharing requires reliable real-time data at any scale between data producers and data consumers. Additionally, true decoupling between the decentralized data products is key to the success of the data mesh paradigm. Each domain must have access to shared data but also the ability to choose the right tool (i.e., technology, API, product, or SaaS) to solve its business problems.
That’s where data streaming fits into the data mesh story:
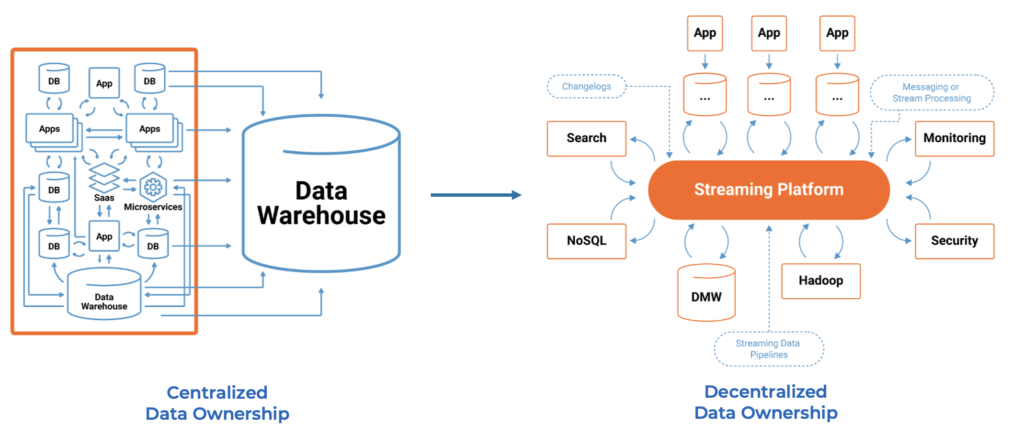
The de facto standard for data streaming is Apache Kafka. A cloud-native data streaming infrastructure that can link clusters with each other out-of-the-box enables building a modern data mesh. No Data Mesh will use just one technology or vendor. Learn from inspiring posts from your favorite data products vendors like AWS, Snowflake, Databricks, Confluent, and many more to successfully define and build your custom Data Mesh. Data Mesh is a journey, not a big bang. A data warehouse or data lake (or in modern days, a lakehouse) cannot be the only infrastructure for data mesh and data products.
I covered how to leverage the capabilities of Apache Kafka and its ecosystem like Kafka Connect, ksqlDB, Cluster Linking, etc. to build the heart of a data mesh in a separate blog post: Streaming Data Exchange with Kafka and a Data Mesh in Motion.
Example: Real-time data fabric in hybrid cloud
Here is one example spanning a streaming Data Mesh across multiple cloud providers like AWS, Azure, GCP, or Alibaba, and on-premise / edge sites:
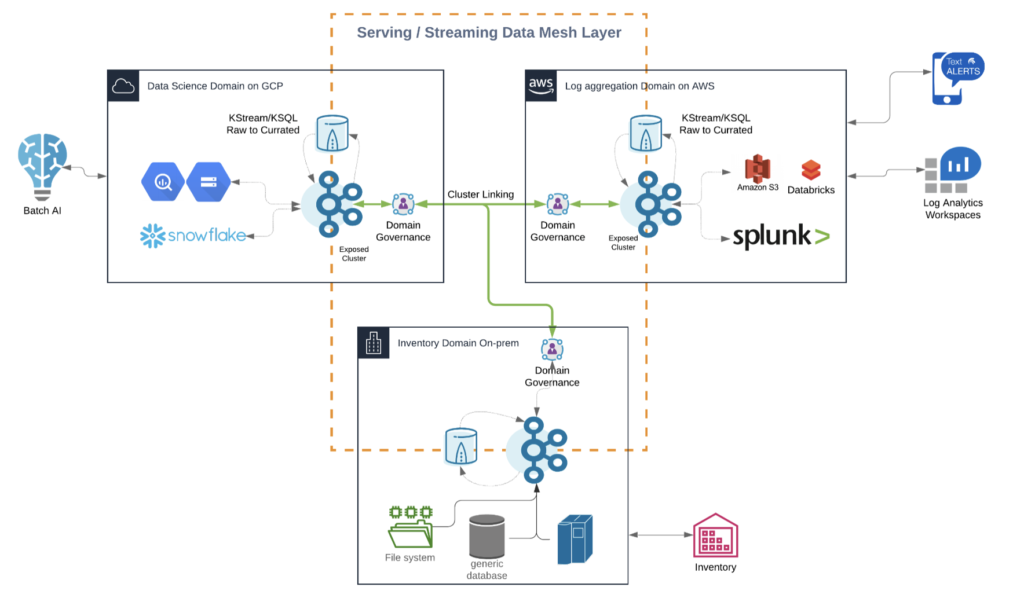
This example shows all the characteristics discussed in the above sections for a Data Mesh:
- Decentralized real-time infrastructure across domains and infrastructures
- True decoupling between domains within and between the clouds
- Several communication paradigms, including data streaming, RPC, and batch
- Data integration with legacy and cloud-native technologies
- Continuous stream processing where it adds value, and batch processing in some analytics sinks
Presentation: Building a decentralized data mesh with data streaming at its heart
The following slide deck walks you through the motivation, principles, and architectures of building a real-time data mesh powered by Apache Kafka using the Kappa architecture, hybrid cloud, and stream data sharing:
https://www.slideshare.net/KaiWaehner/the-heart-of-the-data-mesh-beats-in-realtime-with-apache-kafka
The data mesh provides flexibility and freedom of technology choice for each data product
The heart of a decentralized data mesh infrastructure must be real-time, reliable, and scalable. As the de facto standard for data streaming, Apache Kafka plays a crucial role in a cloud-native data mesh architecture. Nevertheless, data mesh is not bound to a specific technology. The beauty of the decentralized architecture is the freedom of technology choice for each business unit when building its data products.
Data sharing between domains within and across organizations is another aspect where data streaming helps in a data mesh. Real-time data beats slow data. That is not just true for most business problems across industries but also for replicating data between data centers, clouds, regions, or organizations. A streaming data exchange enables data sharing in real-time to build a data mash in motion.
Did you already start building your Data Mesh? What does the enterprise architecture look like? What frameworks, products, and cloud services do you use? Is the heart of your data mesh real-time in motion or some lakehouse at rest? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.
