I started at Confluent in May 2017 to work as Technology Evangelist focusing on topics around the open source framework Apache Kafka. I think Machine Learning is one of the hottest buzzwords these days as it can add huge business value in any industry. Therefore, you will see various other posts from me around Apache Kafka (messaging), Kafka Connect (integration), Kafka Streams (stream processing), Confluent’s additional open source add-ons on top of Kafka (Schema Registry, Replicator, Auto Balancer, etc.). I will explain how to leverage all this for machine learning and other big data technologies in real world production scenarios.
Read this, if you wonder why am so excited about moving (back) to open source for messaging, integration and stream processing in the big data world.
In the following blog post, I want to share my first slide deck from a conference talk representing Confluent: A software architecture user group in Leipzig, Germany organized a 2-day event to discuss big data in practice.
This is the abstract of the slide deck:
Big Data and Machine Learning are key for innovation in many industries today. Large amounts of historical data are stored and analyzed in Hadoop, Spark or other clusters to find patterns and insights, e.g. for predictive maintenance, fraud detection or cross-selling.
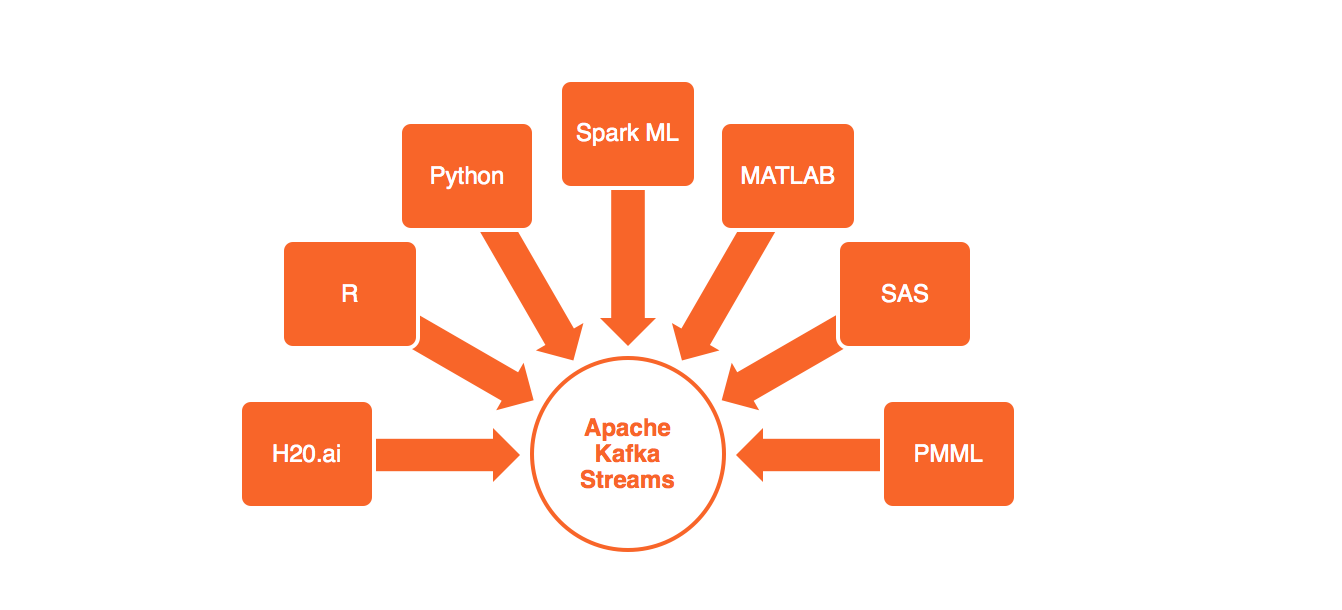
This first part of the session explains how to build analytic models with R, Python and Scala leveraging open source machine learning / deep learning frameworks like Apache Spark, TensorFlow or H2O.ai.
The second part discusses how to leverage these built analytic models in your own real time streaming applications or microservices. It explains how to leverage the Apache Kafka cluster and Kafka Streams instead of building an own stream processing cluster. The session focuses on live demos and teaches lessons learned for executing analytic models in a highly scalable and performant way.
The last part explains how Apache Kafka can help to move from a manual build and deployment of analytic models to continuous online model improvement in real time.
Slide Deck: How to Build Analytic Models and Deployment to Real Time Processing
Here is the slide deck:
You are currently viewing a placeholder content from Default. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More blog posts with more details and specific code examples will follow in the next weeks. I will also do a web recording for this slide deck and post it on Youtube.





