
Data streaming is a new software category to process data in motion. Apache Kafka is the de facto standard used by over 100,000 organizations. Plenty of vendors offer Kafka platforms and cloud services. Many complementary stream processing engines like Apache Flink and SaaS offerings have emerged. And competitive technologies like Pulsar and Redpanda try to get market share. This blog post explores the data streaming landscape of 2023 to summarize existing solutions and market trends.
Data streaming is a new software category
Data-driven applications are the new black. This approach increases the business value as the overall goal by increasing revenue, reducing cost, reducing risk, or improving the customer experience.
Plenty of software categories and related data platforms exist to process and analyze data:
- Database: Store and execute transactional workloads.
- Data Warehouse: Processing structured historical data to create recurring reports and unique insights.
- Data Lake: Processing structured and semi- or unstructured big data sets with batch processing to create recurring reports and unique insights.
- Lakehouse: A mix of data warehouse and data lake to process all data on one platform.
- Data Streaming: Continuously process data in motion and provide data consistency across communication paradigms instead of storing and analyzing data at rest.
Of course, these data platforms often overlap a bit. I did a complete blog series exploring the use cases and how they complement each other.
- Data Warehouse vs. Data Lake vs. Data Streaming – Friends, Enemies, Frenemies?
- Data Streaming for Data Ingestion into the Data Warehouse and Data Lake
- Data Warehouse Modernization: From Legacy On-Premise to Cloud-Native Infrastructure
- Case Studies: Cloud-native Data Streaming for Data Warehouse Modernization
- Lessons Learned from Building a Cloud-Native Data Warehouse
Data streaming use cases by business value
Use cases for data streaming exist across all industries:
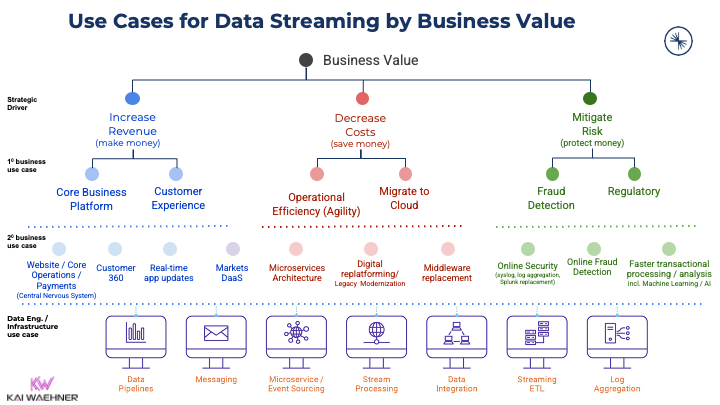
Adding business value is crucial for any enterprise. With so many potential use cases, it is no surprise that more and more software vendors add Kafka support to their products. Search my blog for your favorite industry to find plenty of case studies and architectures. Or read about use cases for Apache Kafka across industries to get started.
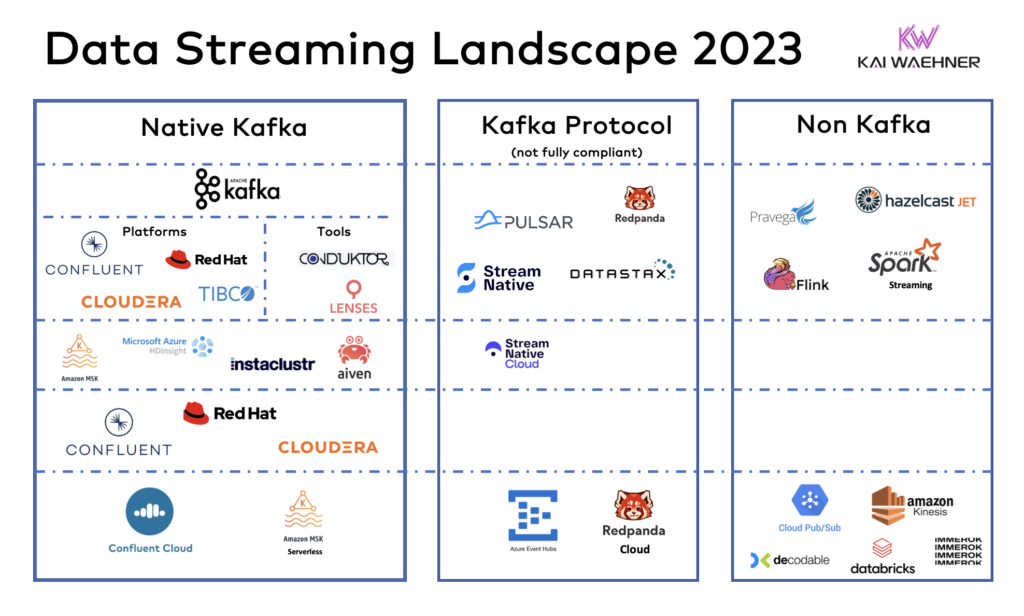
The data streaming landscape of 2023
Data Streaming is a separate software category of data platforms. Many software vendors built their entire businesses around this category.
The data streaming landscape shows that most vendors use Kafka or implement its protocol because it has become the de facto standard.
New software companies have emerged in this category in the last few years. And several mature players in the data market added support for data streaming in their platforms or cloud service ecosystem.
Apache Kafka is the de facto standard for data streaming, like Amazon S3 is the de facto standard for S3 object storage. Most software vendors use Kafka for their data streaming platforms. However, there is more than Kafka. Some vendors only use the Kafka protocol (Azure Event Hubs) or utterly different APIs (like Amazon Kinesis).
The following Data Streaming Landscape 2023 summarizes the current status of relevant products and cloud services:
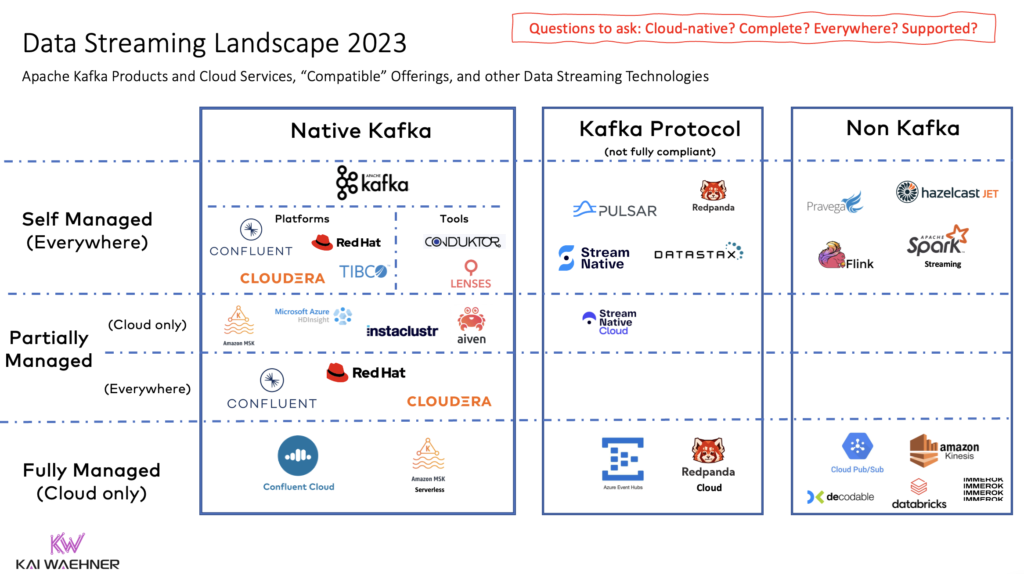
Please note: This is not a complete list of frameworks, cloud services, or vendors. It is not an official research landscape. If your favorite technology is not in this diagram, then I did not see it in my conversations with customers, prospects, partners, analysts, or the broader data streaming community. We will probably see many more logos in this diagram in a year or two, as this is still the beginning of the data streaming era.
Also, note that I focus on general data streaming infrastructure. Brilliant solutions exist for using and analyzing streaming data for specific scenarios, like time series databases, machine learning engines, or observability platforms. These are complementary and often connected out of the box to a streaming cluster.
Evaluation criteria for data streaming platforms
I often recommend using the following four aspects to look at different frameworks, platforms, and cloud services to evaluate a technology for your business project or enterprise architecture strategy:
- Cloud-native: Is the solution elastic to scale up and down? Is it fully managed / serverless, or just a bunch of server instances hosted in the cloud? Can you automate the development, operations, and testing process using DevOps, GitOps, test-driven development, and similar principles?
- Complete: Does the solution offer all required capabilities? Data streaming requires more than just messaging or data ingestion. Hence, does it provide connectors, data processing, governance, security, self-service, and so on?
- Everywhere: Where can you use the solution? Cloud-only? Are all required cloud service providers supported? Is there an option to deploy in a data center or even at the edge (i.e., outside a data center)? How can you share data between regions, clouds or data centers? What use cases are supported (e.g., aggregation, disaster recovery, hybrid integration, etc.)?
- Supported: Is the solution mature and battle-tested? Are public case studies available for your use case or industry? Does the vendor fully support the product? What are the SLAs? Are specific features excluded from commercial enterprise support? It is a shame that this aspect needs to be evaluated. Still, some vendors offer data streaming cloud services and exclude support in the terms and conditions (that many people don’t read in cloud services, unfortunately).
Let’s take a deeper look into the different categories and start with the leading technology: Native Apache Kafka…
Apache Kafka is the de facto standard for data streaming
Starting with the leader and de facto standard Apache Kafka and related vendors and SaaS offerings. Apache Kafka became the de facto standard for data streaming like Amazon S3 is the de facto standard for object storage:

Read the detailed blog post to learn more about the differences between an open-source standard like Kafka and a proprietary protocol like S3.
When you explore the data streaming world, there is no way not to look at the Apache Kafka ecosystem.
Apache Kafka adoption and growth
The growth of the Apache Kafka community in the last few years is impressive. Here are some statistics that Jay Kreps presented at the data streaming conference “Current – The Next Generation of Kafka Summit” in Austin, Texas, in October 2022:
- >100,000 organizations using Apache Kafka
- >41,000 Kafka meetup attendees
- >32,000 Stack Overflow questions
- >12,000 Jiras for Apache Kafka
- >31,000 Open job listings request Kafka skills
And look at the increased number of active monthly unique users downloading the Kafka Java client library with Maven:
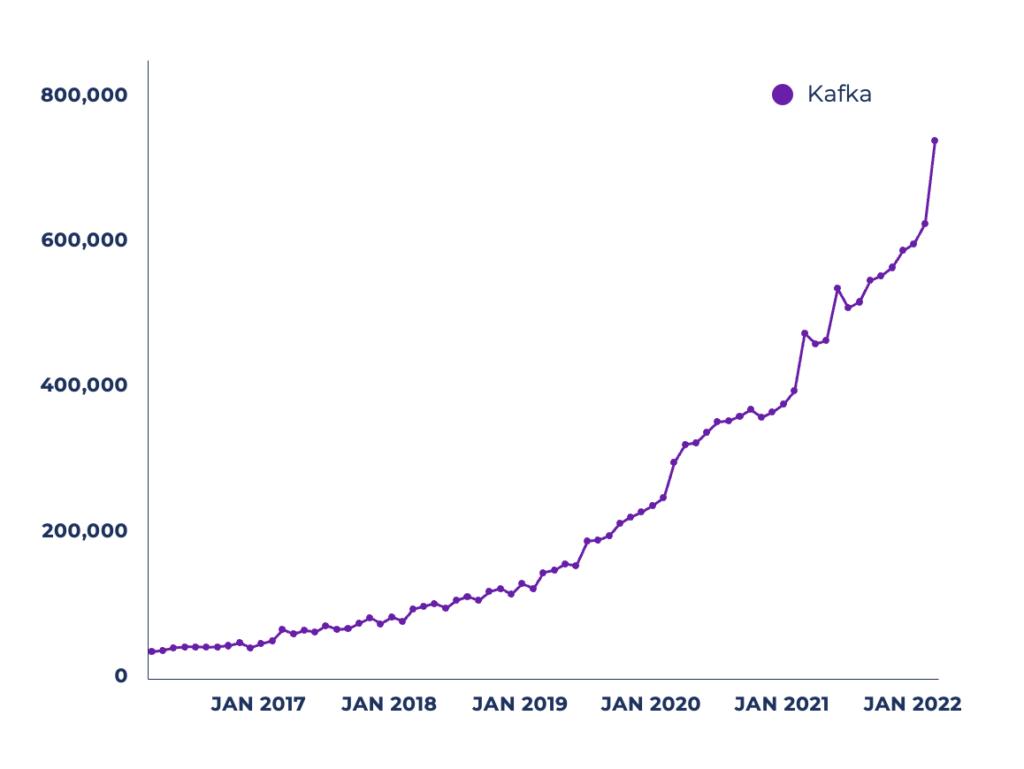
Fun fact: The leading conference for Kafka was rebranded from “Kafka Summit” to “Current 2022 – The Next Generation of Kafka Summit”. Why? Because data streaming is more than Kafka. Many complementary and competitive technologies were present, including vendors, booths, demos, and customer case studies. That’s a remarkable evolution of data streaming for the community and enterprises across the globe!
Apache Kafka Vendors: self-managed vs. cloud offerings
New software companies focus on data streaming. And traditional players like IBM and Amazon jumped on the bandwagon in the past few years. On a top level – to keep it simple – three kinds of offerings exist for Apache Kafka:

I made a detailed comparison of on-premise Kafka vendors and cloud services using this car analogy. Only Amazon MSK Serverless (i.e., the fully managed service, not the partially Managed MSK) was not available when writing this comparison. Hence, read Confluent Cloud versus Amazon MSK Serverless.
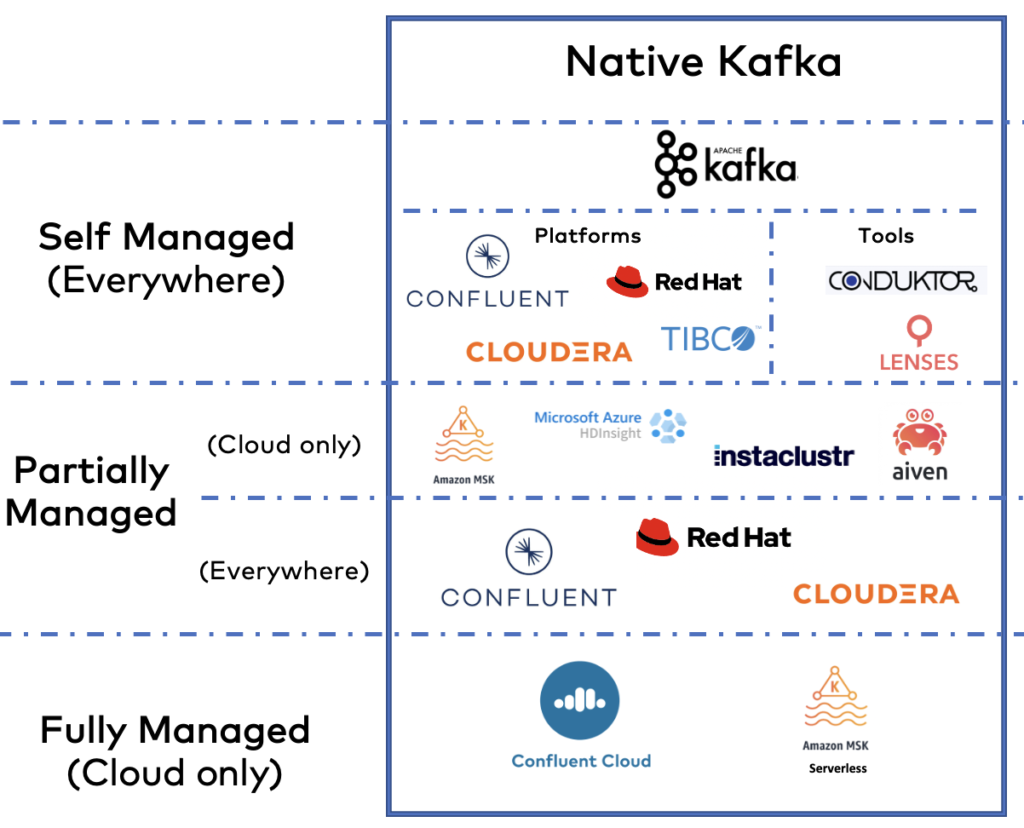
Here are a few notes on each vendor as a summary.
- Apache Kafka: The de facto standard for data streaming. Open source with a vast community. All the vendors in this list rely on (parts of) this project.
- Confluent: Provides data streaming everywhere with Confluent Platform (self-managed) and Confluent Cloud (fully managed and available across cloud providers).
- Cloudera: Provides Kafka as a self-managed offering. Focuses on combining many data technologies like Kafka, Hadoop, Spark, Flink, NiFi, and many more.
- Red Hat: Provides Kafka as a partially managed cloud offering and self-managed Kafka on Kubernetes via OpenShift. Kafka is part of the integration portfolio that includes other open-source frameworks like Apache Camel.
- TIBCO: Offers Kafka for Linux and Windows. Strange product (as Kafka experts know Kafka does not work well on Windows) and minimal documentation.
- AWS: Provides two separate products with Amazon MSK (partially managed) and Amazon MSK Serverless (fully managed). Kafka support is excluded in the MSK offerings. AWS has hundreds of cloud services, and Kafka is part of that broad spectrum. Only available on AWS clouds.
- Instaclustr and Aiven: Partially managed Kafka cloud offerings across cloud providers. The product portfolios offer various hosted services of open-source technologies. Instaclustr also offers a (semi-)managed offering for on-premise infrastructure.
- Microsoft Azure HDInsight. A piece of Azure’s Hadoop infrastructure. Not intended for other use cases. Only available on Azure clouds.
- Lenses and Conduktor: Tools for managing and monitoring Kafka clusters. Complementary to the other vendors.
This is no comparison. Just a list with a few notes. Make your own evaluation of your favorite vendors. Check what you need: Cloud-native? Complete? Everywhere? Supported?
Kafka-compatible open-source frameworks and SaaS
A few vendors don’t rely on open-source Apache Kafka but built their own implementations for different reasons. The Kafka protocol compatibility is limited (though marketing will not tell you). This can create risk in operating existing Kafka workloads against the cluster and differs in operations and execution (which can be good or bad).
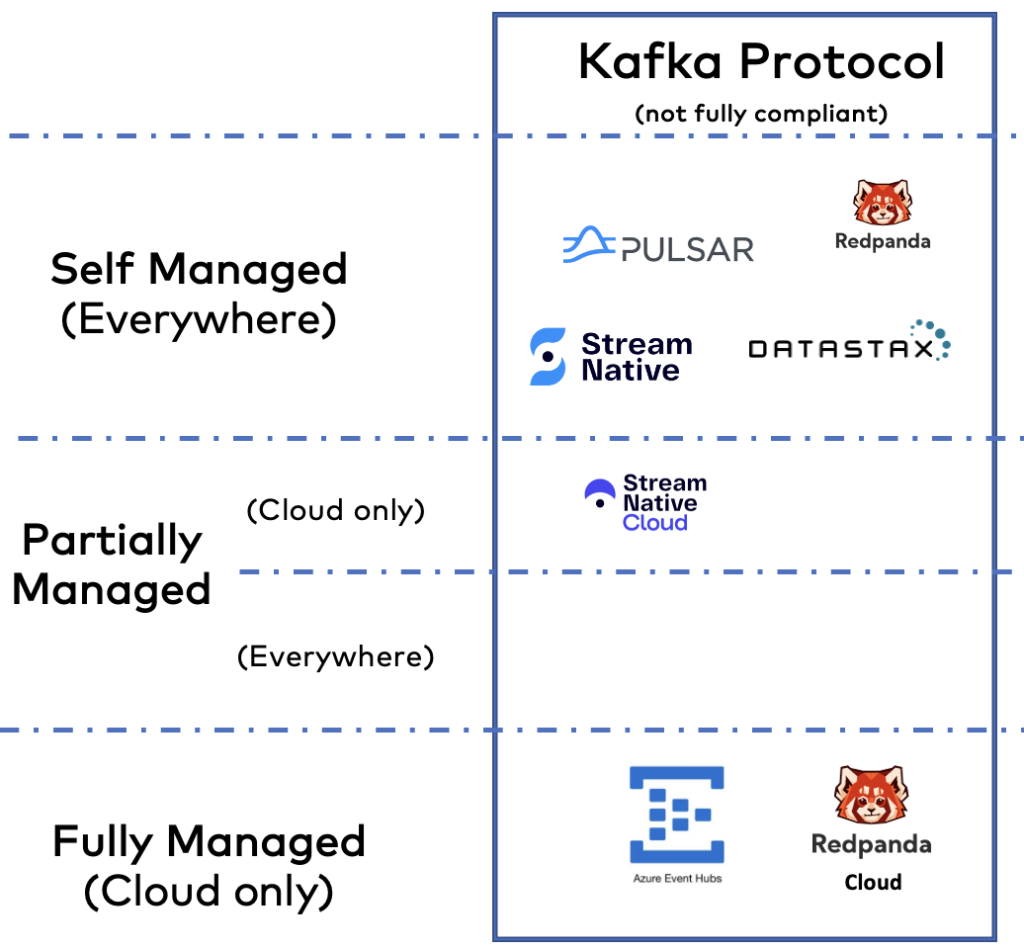
Here are a few notes on each vendor as a summary:
- Apache Pulsar: A competitor to Apache Kafka. Similar story and use cases, but different architecture (Kafka is one distributed cluster – after removing the ZooKeeper dependency in 2022), Pulsar is three distributed clusters (Pulsar brokers, ZooKeeper, BookKeeper). I wrote about Pulsar vs. Kafka two years ago, and I think the status is still the same (and it is too late now to get more market traction).
- StreamNative: The primary vendor behind Apache Pulsar. Offers self-managed and fully managed solutions. StreamNative Cloud for Kafka is in beta and not production ready.
- DataStax: A Pulsar offering integrated into the database-focused product portfolio. Not sure if the streaming product is just marketing or not. If you want to try out the Astra Streaming cloud service powered by Pulsar, it refers you to the multi-cloud DBaaS built on Apache Cassandra.
- Redpanda: A new entrant into the data streaming market offering self-managed and fully managed products. Interesting approach to implementing the Kafka protocol with C++. It might take some market share if they can find the proper use cases and differentiators. Today, I don’t see Redpanda as an alternative to a Kafka-native offering because of its early stage in the maturity curve and no added value for solving business problems versus the added risk compared to Apache Kafka.
- Azure Event Hubs: A mature, fully managed cloud service. The service does one thing, and that is done very well: Data ingestion via the Kafka protocol (with limited compatibility). Hence, it is not a complete streaming platform, but is more comparable to Amazon Kinesis or Google Cloud PubSub. Only available on Azure cloud.
Be careful about statements of vendors that reimplement the Kafka protocol. Most of these vendors oversell the Kafka protocol compatibility. Additionally, “benchmarketing” (i.e., picking a sweet spot or niche scenario where you perform better than your competitor) is the favorite marketing technique to “prove” differentiators to the real Apache Kafka.
Data streaming is more than Apache Kafka…
While Apache Kafka is the de facto standard for data streaming, many complementary and competitive technologies exist.
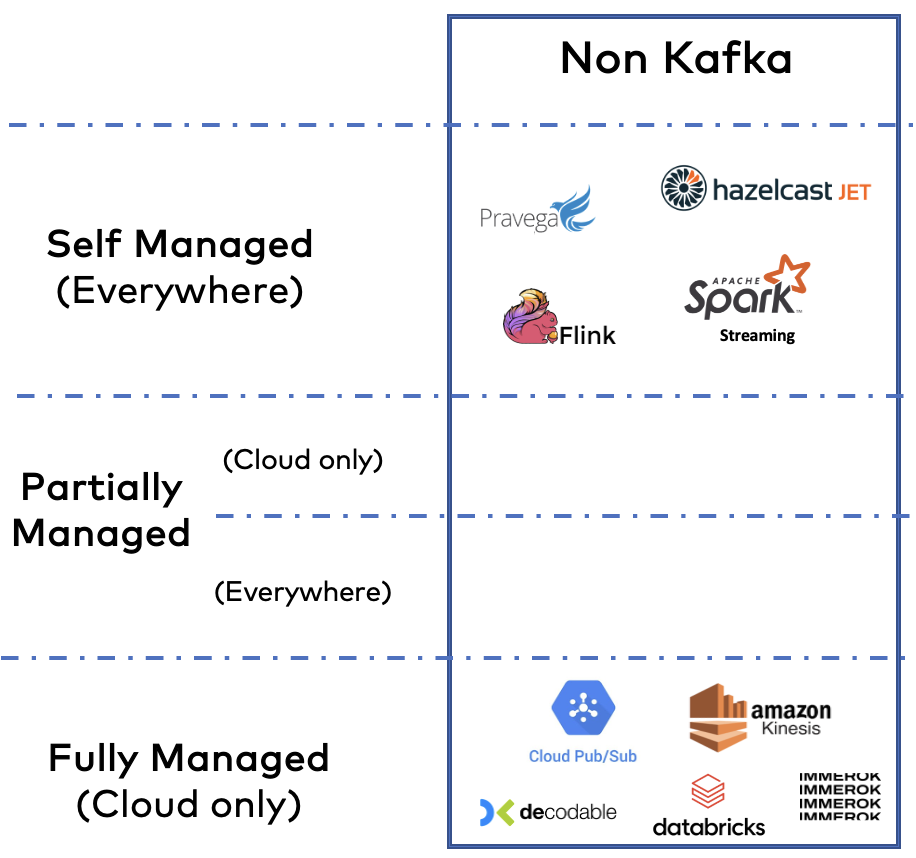
Even more technologies emerge these days because of the growth of this software category across the globe and all industries. That’s excellent news. Data streaming is here to stay and grow.
The situation is challenging to explore as part of the data streaming landscape, as some products are complementary and competitive to the Apache Kafka ecosystem.
Some data streaming technologies are competitive to Kafka
In some situations, you must evaluate whether Apache Kafka or another technology is the right choice. Here are a few open-source and cloud competitors:
- Amazon Kinesis: Data ingestion into AWS data stores. Mature product for a specific problem. Only available on AWS.
- Google Cloud PubSub: Data ingestion into GCP data stores. Mature product for a specific problem. Only available on GCP.
- Pravega and Hazelcast Jet: Open-source frameworks for stream processing. I added these to show that there are more than Kafka and Flink in the open-source world. Though, I see little market traction.
Amazon Kinesis and Google Cloud PubSub are excellent cloud services if you “just” want to ingest data into a specific cloud storage. If there are no other use cases, these tools might be the right choice (if pricing at scale and other limitations work for you).
Apache Kafka is a much more flexible and strategic data streaming platform. Many projects still start with data ingestion and build the first pipeline. But providing access to the same stream of events to any other data sink or for powerful stream processing with tools like Kafka Streams or Apache Flink is a significant advantage.
Some data streaming technologies are complementary to Kafka
Each stream processing framework or cloud service has trade-offs. There is no single size that fits all use cases. Here are a few mature and emerging technologies that complement Apache Kafka:
- Apache Flink: Together with Kafka Streams (part of Apache Kafka), the leading open-source stream processing framework. Advanced features include ANSI SQL support and APIs for stream and batch workloads.
- Decodable and Immerok: Two brand new cloud services. Very early stage. I still added them, as I think it is an excellent strategic move to build a data streaming cloud service on top of Apache Flink. Huge potential if it is combined with existing Kafka infrastructures in enterprises.
- Spark Streaming: The streaming part of Apache Spark. I am still not 100 percent convinced. Kafka Streams and Apache Flink are the better choices for stream processing. However, the enormous installed base of Spark clusters in enterprises broadens adoption.
- Databricks: The leading vendor behind Apache Spark. Getting or at least trying to get much more into the business of real-time data. I like the platform, but I am not convinced by the lakehouse story around “doing everything within one big data lake”. Check out my blog series “Data Warehouse vs. Data Lake vs. Data Streaming – Friends, Enemies, Frenemies?“.
Apache Flink and Spark Streaming WITHOUT Kafka?
Most of these technologies complement Apache Kafka. But stream processing frameworks like Flink or cloud services like Databricks do NOT need Kafka as an ingestion layer. There are other options…
Flink, Spark, et al. can consume data from other streaming platforms or directly from data stores. However, be careful with the latter: If you use Flink or Spark Streaming for stream processing, that’s fine. But if the first thing to do is read the data from an S3 object store, well, that is data at rest. Don’t do stream processing with data at rest.
Or in other words, don’t store data in a database or data lake just to reverse it later. Almost all Spark Streaming examples and case studies I saw last year at conferences and customer meetings looked like this. That is an anti-pattern for stream processing!
To be clear: It is okay to ingest data from S3 or another data store to a stream processing application built with Kafka Streams, Flink, et al. This data can be used in the stateful backend for your tasks like enrichment purposes. A stream processing application is not just about real-time data feeds. It also correlates these real-time feeds with (already ingested) historical data. This is a common approach for metadata or business data that is updated less frequently (like from an SAP ERP system).
Why are Kafka Streams and KSQL missing in the data streaming landscape?
I intentionally did not put Kafka Streams and KSQL into the data streaming landscape. Both are Kafka-native stream processing technologies.
Kafka Streams, like Kafka Connect, are part of open-source Apache Kafka. Hence, the Java library is included if you download Kafka from the Apache website. It is already included in the data streaming landscape with the Kafka logo. You should always ask yourself if you need another framework besides Kafka Streams for stream processing. The significant benefit: One technology, one vendor, one infrastructure.
Many vendors exclude or do not focus on Kafka Streams and Kafka Connect and only offer incomplete Kafka; they want to sell their own integration and processing products instead.
KSQL is an abstraction layer on top of Kafka Streams to provide stream processing with streaming SQL. A great tool, also Kafka-native. It comes with a Confluent Community License and is free to use. Hence, like Kafka Streams, I see it as part of Kafka and did not explicitly put it into the data streaming landscape as a separate product. But you need to evaluate it against Flink, Decodable, and others, for your use case, of course.
The data streaming era is just beginning…
The data streaming landscape 2023 shows how a new software category is emerging. We are still in a very early stage. In most conversations with customers, partners, and the community, I hear statements like:
“We see the value, but we are not there yet – we now start with building first data streaming pipelines and have a roadmap for the next years to add more advanced stream processing”.
Data streaming is a long journey, as it is a paradigm shift. We hopefully see a Gartner Magic Quadrant for Event Streaming and a Forrester Wave for Data Streaming in the foreseeable, too. A new category takes time to create. But did you already notice how much more the analysts of Gartner, Forrester, and others already write about data streaming and the various vendors? I also wrote a dedicated blog explaining why data streaming is its own software category.
Looking at the competitive data streaming market, one of my favorite real-world examples for choosing the right stream processing technologies comes from DoorDash: Why companies migrate from Amazon SQS and Kinesis to Apache Kafka and Flink. The article explores the trade-offs between cloud-specific solutions like Kinesis or PubSub and an open ecosystem around open-source technologies like Kafka and Flink.
Last but not least, check out my Top 5 Data Streaming Trends for 2023 to understand how the data streaming landscape fits into emerging trends like data mesh, data sharing, and data governance.
What are your most relevant and exciting trends for data streaming and Apache Kafka in 2023 to set data in motion? What does your enterprise landscape for data streaming look like? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.
