
The concepts and architectures of a data warehouse, a data lake, and data streaming are complementary to solving business problems. Storing data at rest for reporting and analytics requires different capabilities and SLAs than continuously processing data in motion for real-time workloads. Many open-source frameworks, commercial products, and SaaS cloud services exist. Unfortunately, the underlying technologies are often misunderstood, overused for monolithic and inflexible architectures, and pitched for wrong use cases by vendors. Let’s explore this dilemma in a blog series. Learn how to build a modern data stack with cloud-native technologies. This is part 4: Case Studies for cloud-native data streaming and data warehouse modernization.

Blog Series: Data Warehouse vs. Data Lake vs. Data Streaming
This blog series explores concepts, features, and trade-offs of a modern data stack using data warehouse, data lake, and data streaming together:
- Data Warehouse vs. Data Lake vs. Data Streaming – Friends, Enemies, Frenemies?
- Data Streaming for Data Ingestion into the Data Warehouse and Data Lake
- Data Warehouse Modernization: From Legacy On-Premise to Cloud-Native Infrastructure
- THIS POST: Case Studies: Cloud-native Data Streaming for Data Warehouse Modernization
- Lessons Learned from Building a Cloud-Native Data Warehouse
Stay tuned for a dedicated blog post for each topic as part of this blog series. I will link the blogs here as soon as they are available (in the next few weeks). Subscribe to my newsletter to get an email after each publication (no spam or ads).
Case studies: Cloud-native data streaming for data warehouse modernization
Every project is different. This is true for data streaming, analytics, and other software development. The following shows three case studies with significantly different architectures and technologies for data warehouse modernization. The examples come from various verticals: Software and cloud business, financial services, logistics and transportation, and the travel and accommodation industry.
Confluent: Data warehouse modernization from batch ETL with Stitch to streaming ETL with Kafka
The article “Streaming ETL SFDC Data for Real-Time Customer Analytics” explores how Confluent eats its dog food to modernize the internal data warehouse pipeline.
The use case is straightforward and standard across most organizations: Extract, transform, and load (ETL) Salesforce data into a Google BigQuery data warehouse, so that the business can use the data. But it is more complex than it sounds:
Organizations often rely on a third-party ETL tool to periodically load data from a CRM and other applications to their data warehouse. These batch tools introduce a lag between when the business events are captured in Salesforce and when they are made available for consumption and processing. The batch workloads commonly result in discrepancies between Salesforce reports and internal dashboards, leading to concerns about the integrity and reliability of the data.
Confluent used Talend’s Stitch batch ETL tool in the beginning. The old architecture looked like this:
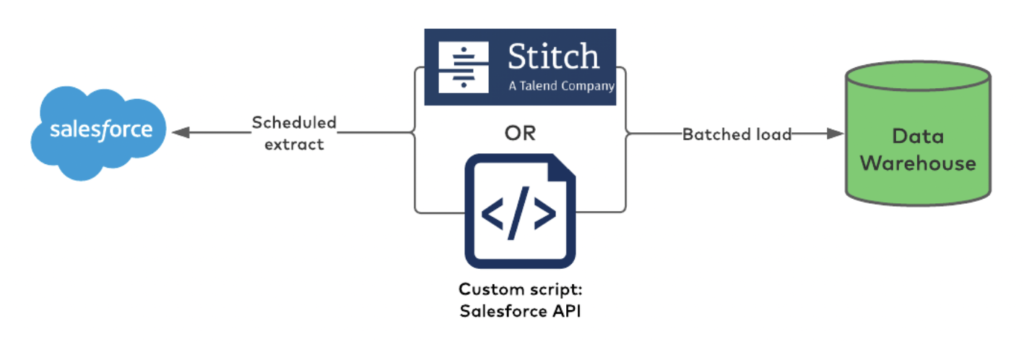
The consequence of batch ETL and a 3rd party tool in the middle lead to insufficient and inconsistent information updates.
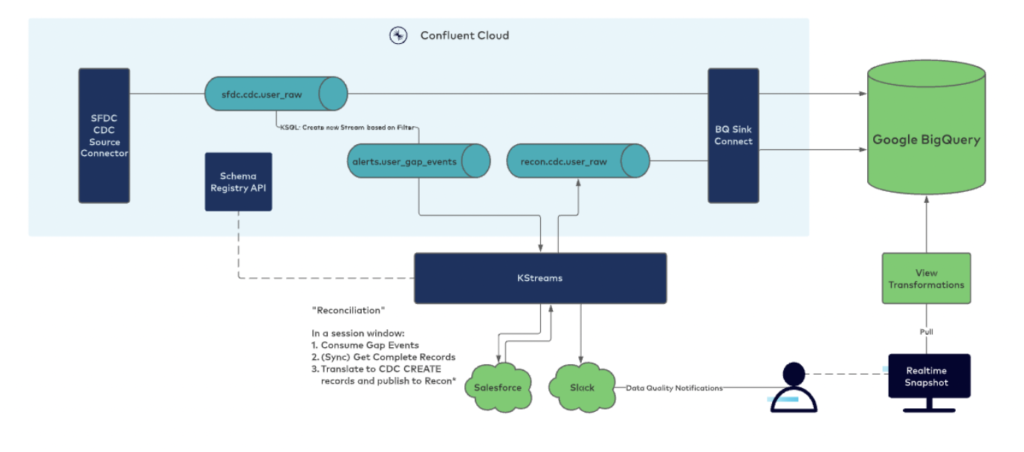
Over the past few years, Confluent has invested in building stream processing capabilities into the internal data warehouse pipeline. Confluent leverages its own fully managed Confluent Cloud connectors (in this case, the Salesforce CDC source and BigQuery sink connectors), Schema Registry for data governance, and ksqlDB + Kafka Streams for reliable streaming ETL to send SFDC data to BigQuery. Here is the modernized architecture:
Paypal: Reducing the time for readouts from 12 hours to a few seconds for 30 billion events per day
Paypal has plenty of Kafka projects for many critical and analytical workloads. In this use case, it scales the Kafka Consumer for 30-35 Billion events per day to migrate its analytical workloads to the Google Cloud Platform (GCP).
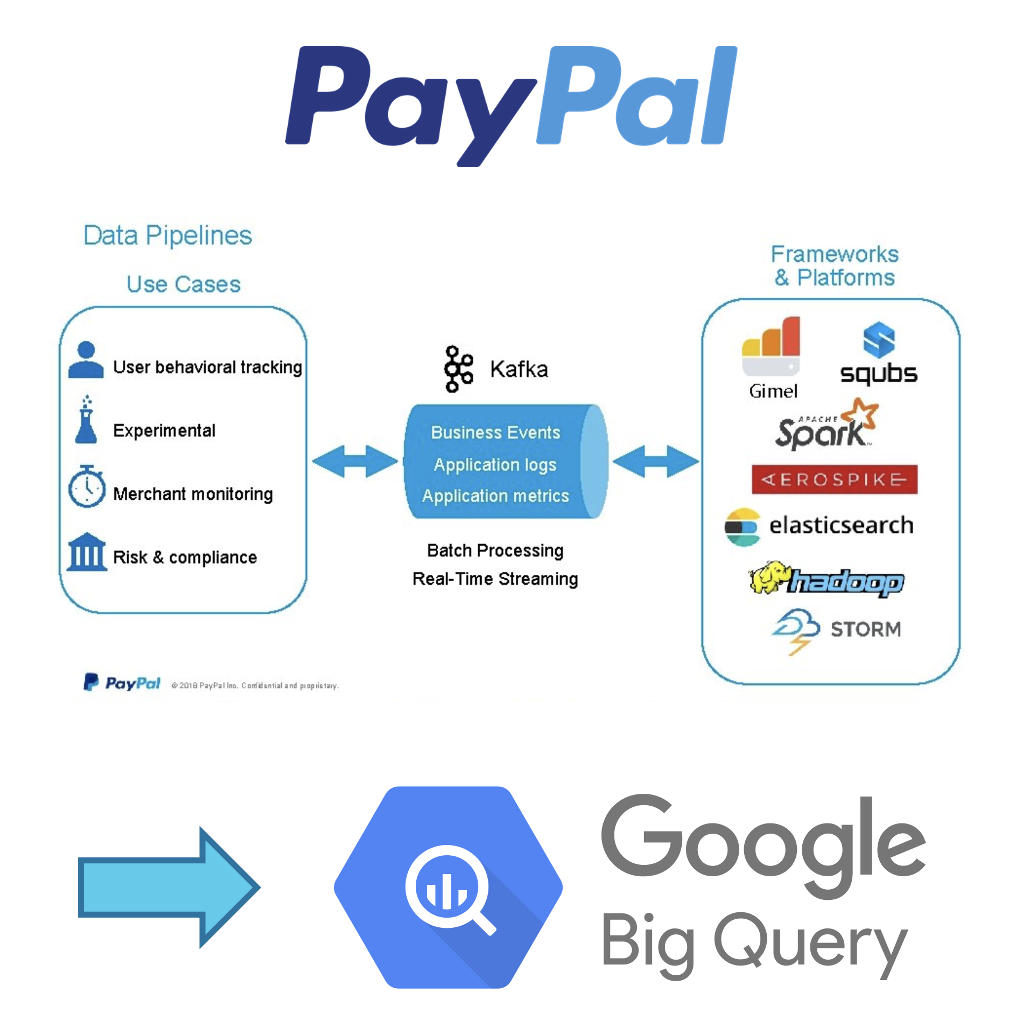
A streaming application ingests the events from Kafka directly to BigQuery. This is a critical project for PayPal as most of the analytical readouts are based on this. The outcome of the data warehouse modernization and building a cloud-native architecture: Reduce the time for readouts from 12 hours to a few seconds.
Read more about this success story in the PayPal Technology Blog.
Shippeo: From on-premise databases to multiple cloud-native data lakes
Shippeo provides real-time and multimodal transportation visibility for logistics providers, shippers, and carriers. Its software uses automation and artificial intelligence to share real-time insights, enable better collaboration, and unlock your supply chain’s full potential. The platform can give instant access to predictive, real-time information for every delivery.
Shippeo described how they integrated traditional databases (MySQL and PostgreSQL) and cloud-native data warehouses (Snowflake and BigQuery) with Apache Kafka and Debezium:
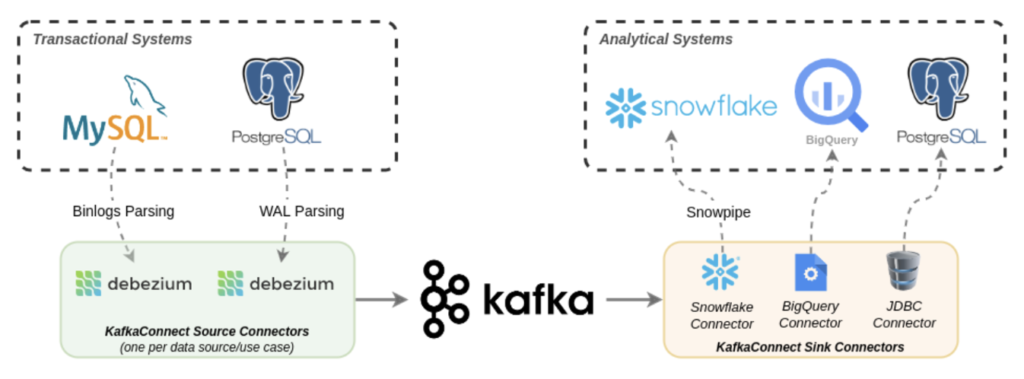
This is an excellent example of cloud-native enterprise architecture leveraging a “best of breed” approach for data warehousing and analytics. Kafka decouples the analytical workloads from the transactional systems and handles the backpressure for slow consumers.
Sykes Cottages: Fully-managed end-to-end pipeline with Confluent Cloud, Kafka Connect, Snowflake
Sykes Holiday Cottages are one of the UK’s leading and fastest-growing independent holiday cottage rental agencies representing over 19,000 cottages across the UK, Ireland, and New Zealand.
The experience of its customers on the web is a top priority and is one way to stay competitive. The goal is to match customers to their perfect holiday cottage experience and delight at each stage along the way. Getting the data pipeline to fuel this innovation is critical. Data warehouse modernization and data streaming enabled new ways to further innovate the web experience through a data-driven approach.
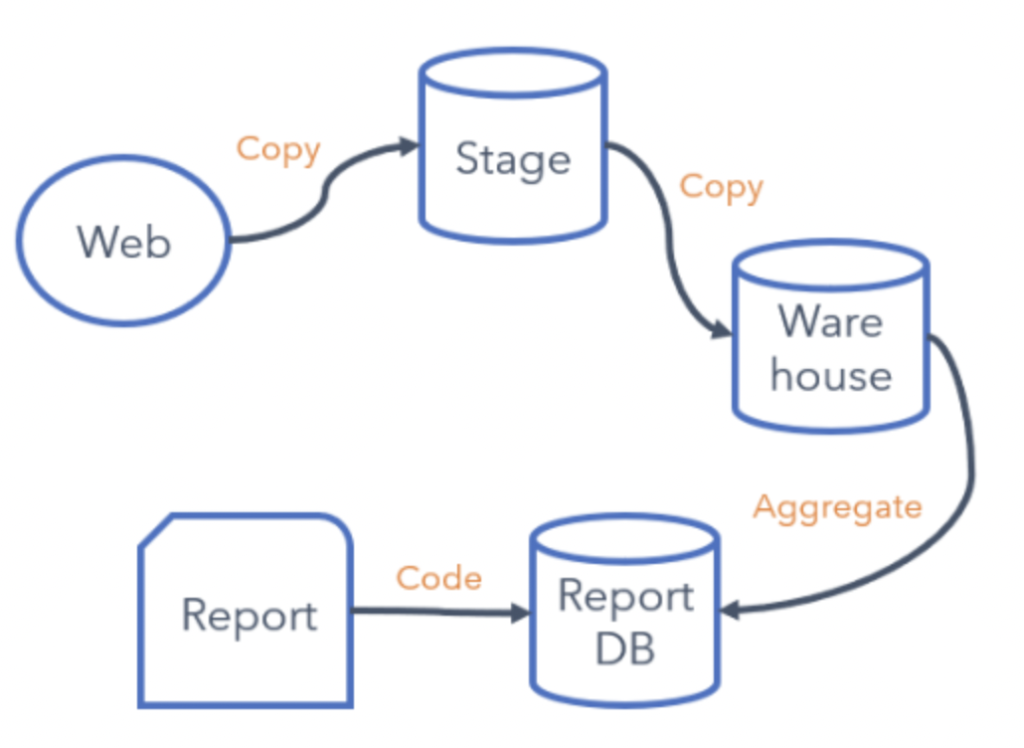
From inconsistent and slow batch workloads…
While serving its purpose for several years, the existing pipeline had problems impairing this cycle. Very early in this pipeline, the ETL process turned the data into rows and columns (structured data). Various copies were made, and the results were presented via a static report. Data engineers were needed for changes, such as new events or contextual information. The scale was also challenging as this has to be done manually in the main.
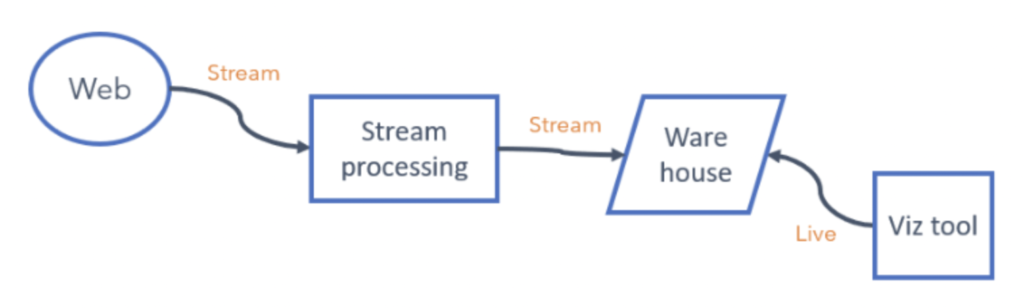
Critically keeping the data in a semi-structured format until it is ingested into the warehouse and then using ELT to do a single transformation of the data, Sykes Holiday Cottages can simplify the pipeline and make it much more agile.
… to event-based real-time updates and continuous stream processing
New web events (and any context that goes with it) can be wrapped up within a message and can flow all the way to the warehouse without a single code change. The new events are then available to the web teams either through a query or the visualization tool.
The current throughput is around 50k (peaking at over 300k) messages per minute. As new events are captured, this will grow considerably. Additionally, each of the above components must scale accordingly.
The new architecture enables the web teams to capture new events. And analyze the data using self-service tools with no dependency on data engineering.
In conclusion, the business case for doing this is compelling. Based on our testing and projections, we expect at least 10x ROI over three years for this investment.
In Sykes Holiday Cottages’ blog post, learn more details: Why Sykes Cottages partnered with Snowflake and Confluent to drive enhanced customer experience.
Doordash: From multiple pipelines to data streaming for Snowflake integration
Even digital natives – that started their business in the cloud without legacy applications in their own data centers – need to modernize the enterprise architecture to improve business processes, reduce costs, and provide real-time information to its downstream applications.
It is cost inefficient to build multiple pipelines that are trying to achieve similar purposes. Doordash used cloud-native AWS messaging and streaming systems like Amazon SQS and Amazon Kinesis for data ingestion into the Snowflake data warehouse:
 Mixing different kinds of data transport and going through multiple messaging/queueing systems without carefully designed observability around it leads to difficulties in operations.
Mixing different kinds of data transport and going through multiple messaging/queueing systems without carefully designed observability around it leads to difficulties in operations.
These issues resulted in high data latency, significant cost, and operational overhead at Doordash. Therefore, Doordash moved to a cloud-native streaming platform powered by Apache Kafka and Apache Flink for continuous stream processing before ingesting data into Snowflake:
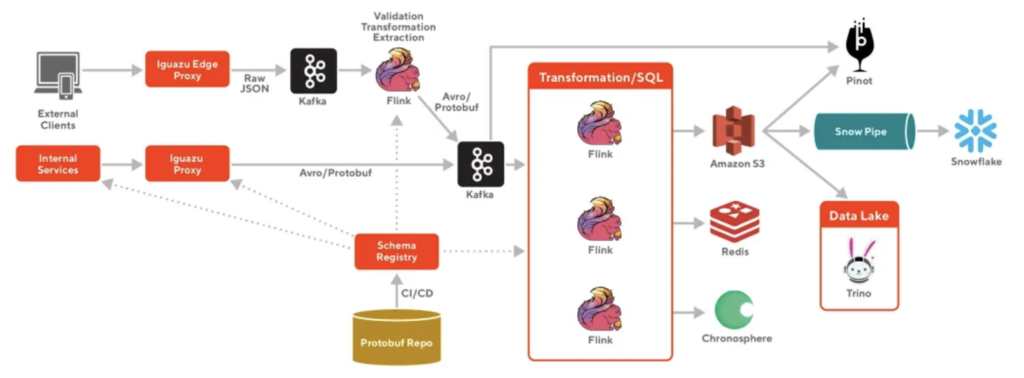
The move to a data streaming platform provides many benefits to Doordash:
- Heterogeneous data sources and destinations, including REST APIs using the Confluent rest proxy
- Easily accessible
- End-to-end data governance with schema enforcement and schema evolution with Confluent Schema Registry
- Scalable, fault-tolerant, and easy to operate for a small team
All the details about this cloud-native infrastructure optimization are in Doordash’s engineering blog post: “Building Scalable Real Time Event Processing with Kafka and Flink“.
Real-world case studies for cloud-native projects prove the business value
Data warehouse and data lake modernization only make sense if there is a business value. Elastic scale, reduced operations complexity, and faster time to market are significant advantages of cloud services like Snowflake, Databricks, or Google BigQuery.
Data streaming plays a vital role in these initiatives to integrate with legacy and cloud-native data sources, continuous streaming ETL, true decoupling between the data sources, and multiple data sinks (lakes, warehouses, business applications).
The case studies of Confluent, Paypal, Shippeo, and Sykes Cottages showed their different success stories of moving into cloud-native infrastructure to rain real-time visibility and analytics capabilities. Elastic scale and fully-managed end-to-end pipelines are crucial success factors in gaining business value with consistently up-to-date information.
For more details, browse other posts of this blog series:
- Data Warehouse vs. Data Lake vs. Data Streaming – Friends, Enemies, Frenemies?
- Data Streaming for Data Ingestion into the Data Warehouse and Data Lake
- Data Warehouse Modernization: From Legacy On-Premise to Cloud-Native Infrastructure
- THIS POST: Case Studies: Cloud-native Data Streaming for Data Warehouse Modernization
- Lessons Learned from Building a Cloud-Native Data Warehouse
Do you have another success story to share? Or are your projects for data lake and data warehouse modernization still ongoing? Do you use separate infrastructure for specific use cases or build a monolithic lakehouse instead? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.
