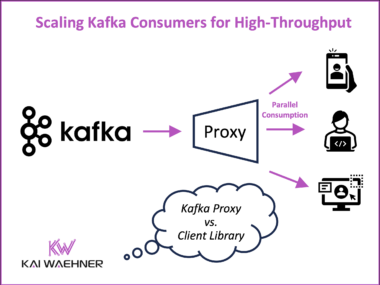
Scaling Kafka Consumers: Proxy vs. Client Library for High-Throughput Architectures
Apache Kafka’s pull-based model and decoupled architecture offer unmatched flexibility for event-driven systems. But as data volumes and consumer applications grow, new challenges emerge; from head-of-line blocking and rising operational overhead to complex failure handling. This post explores real-world lessons from companies like Wix and Uber, highlighting common consumer scalability issues and two main solutions: push-based consumer proxies and enhanced client libraries like Confluent’s Parallel Consumer. It concludes with a vision for a serverless Kafka consumption model that reduces total cost of ownership while preserving Kafka’s core strengths.