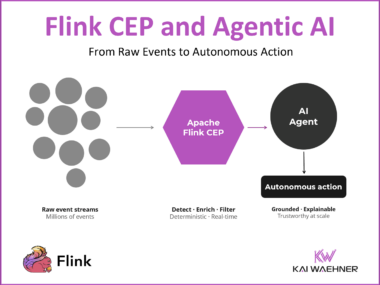
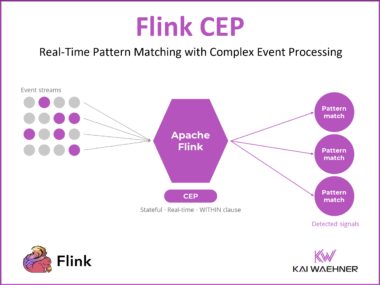
My Confluent Chapter: From Apache Kafka Startup to $11 Billion IBM Acquisition
Nine years at Confluent: from a Silicon Valley startup with 100 people to an $11 billion IBM acquisition. A personal reflection on the Apache Kafka and data streaming journey and what the team accomplished together.