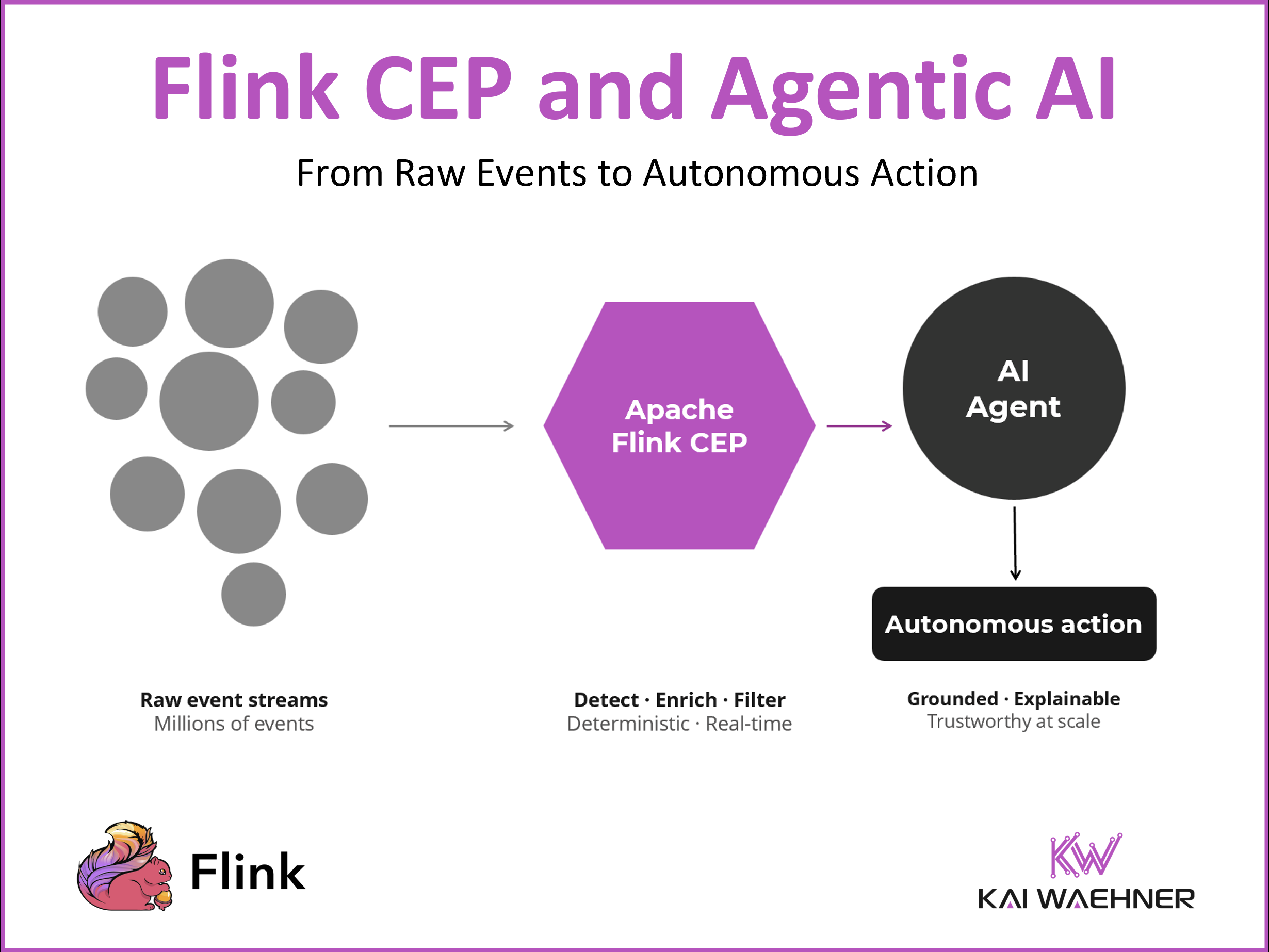
Agentic AI
AI agents fail in production when they are connected directly to raw event streams. Flink CEP is the missing layer between your data streams and

AI agents fail in production when they are connected directly to raw event streams. Flink CEP is the missing layer between your data streams and
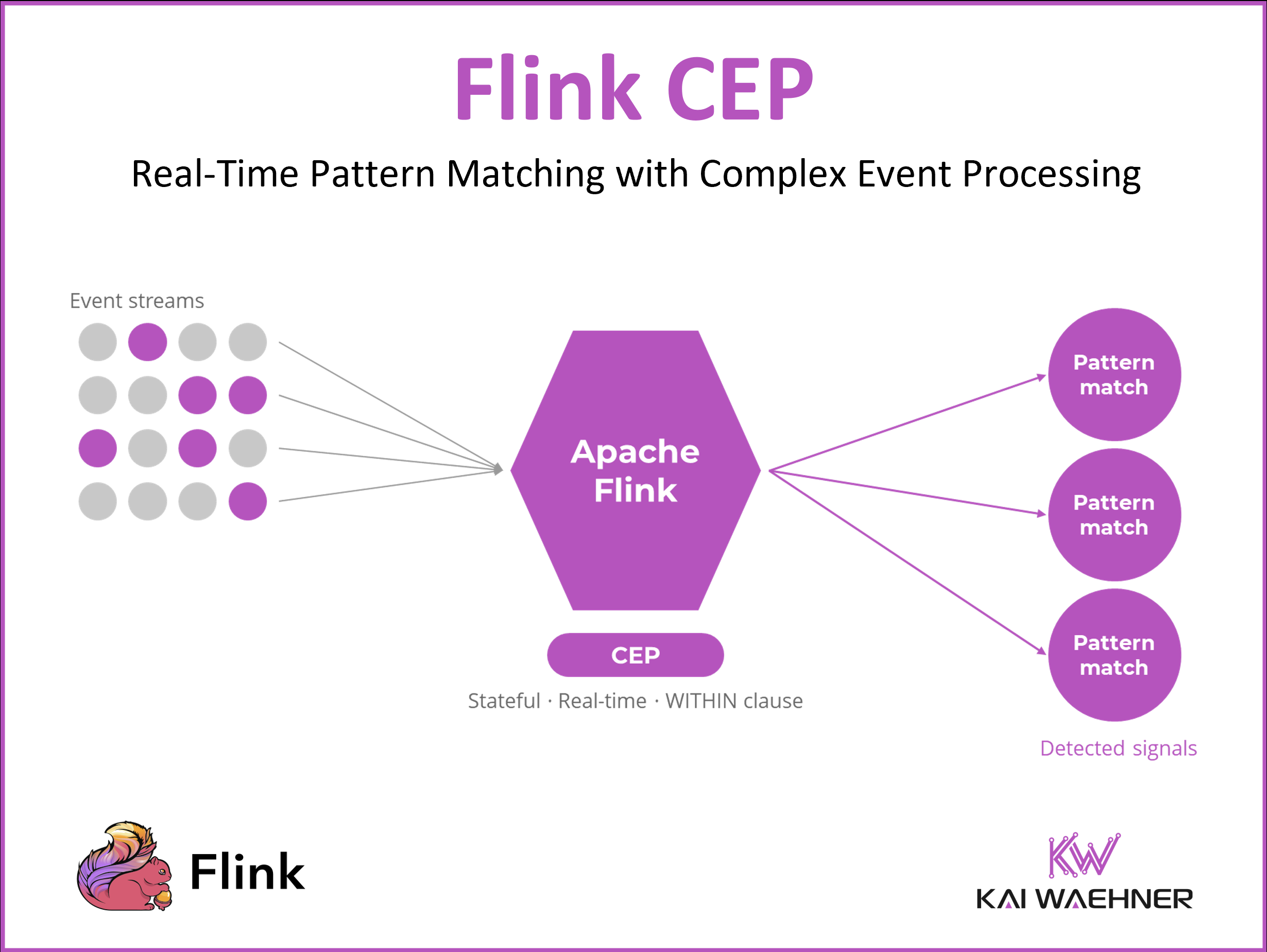
Complex Event Processing is the most underused capability in Apache Flink. It detects meaningful event sequences in real time, fires only when a pattern is
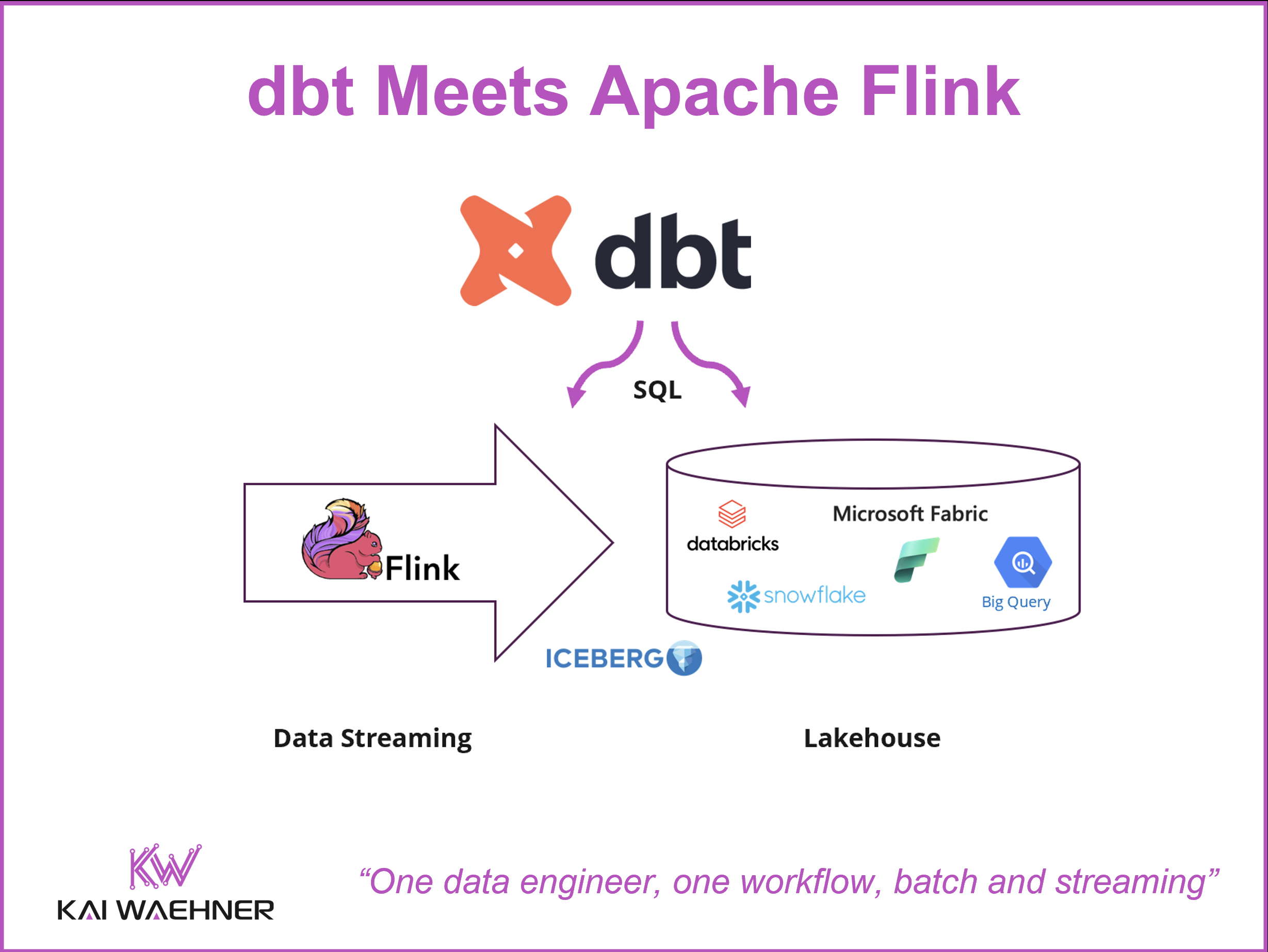
Two toolchains, two skill sets, two CI/CD pipelines — that has been the reality for data engineers working across batch and streaming. dbt extending to
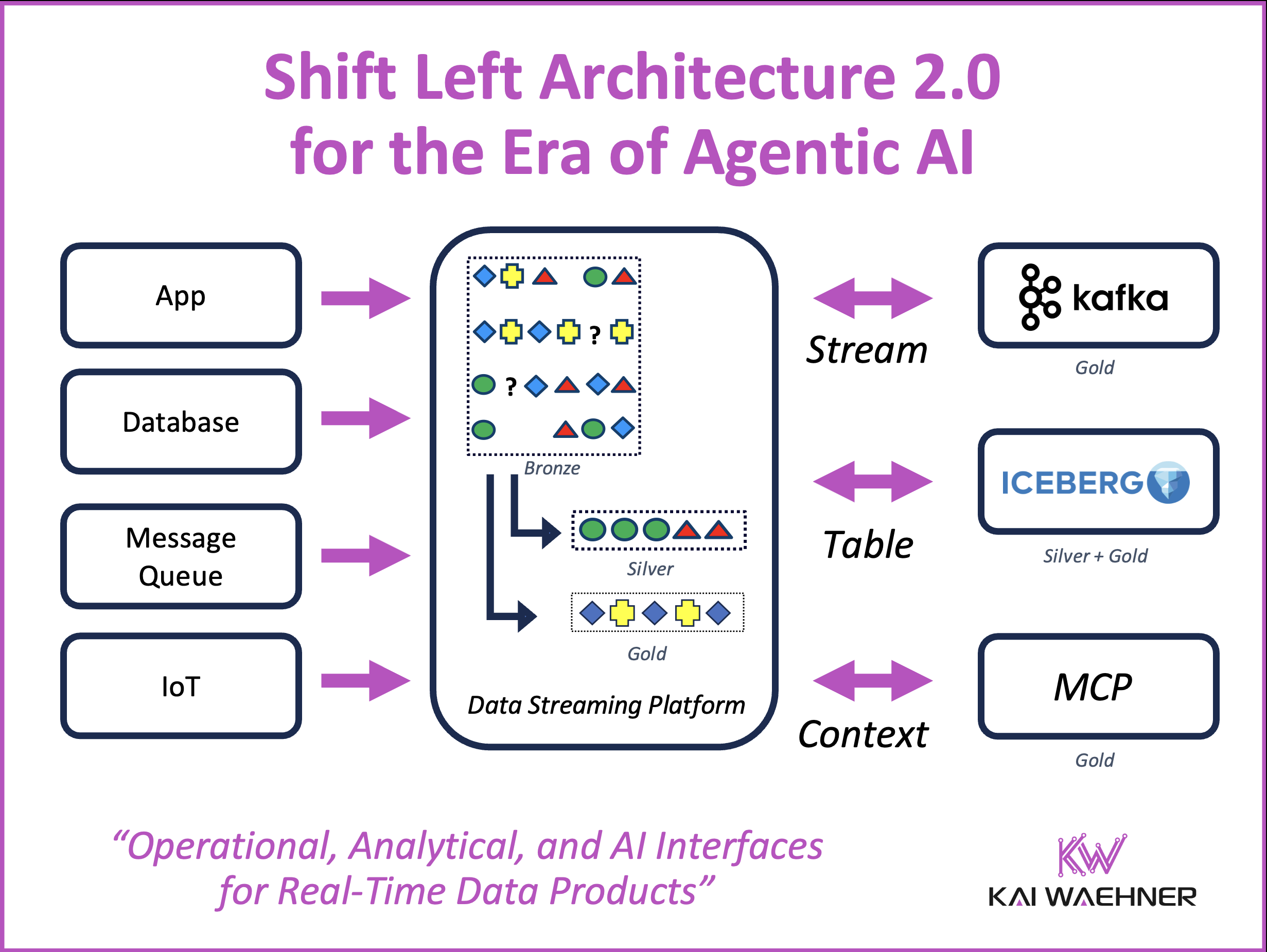
The Shift Left Architecture moves data integration logic into an event-driven architecture where governed data products are built once and served to multiple consumers. The
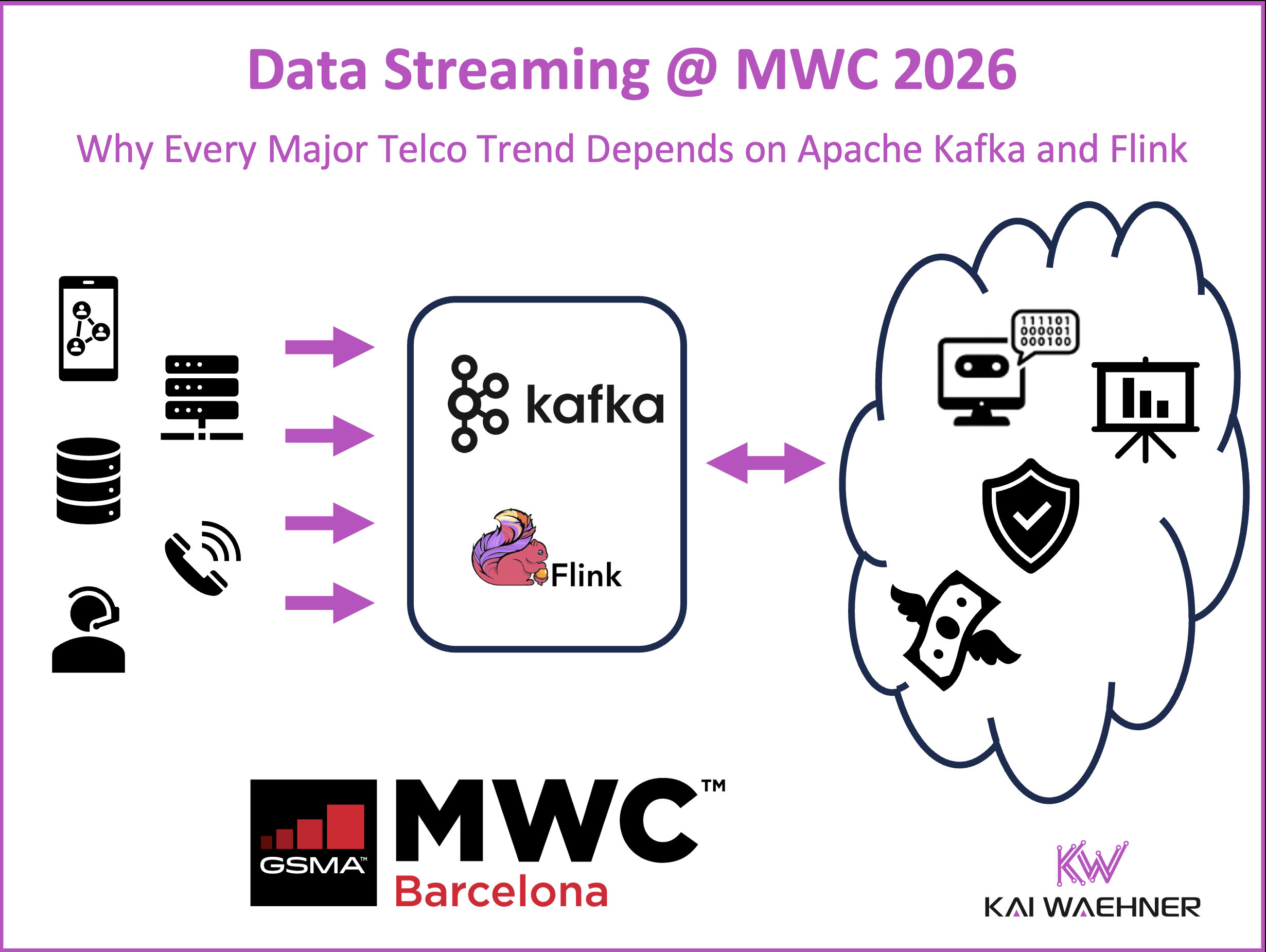
Mobile World Congress (MWC) 2026 highlights the shift from batch systems to real time data streaming in telecom. AI and agentic automation, network APIs, sovereign
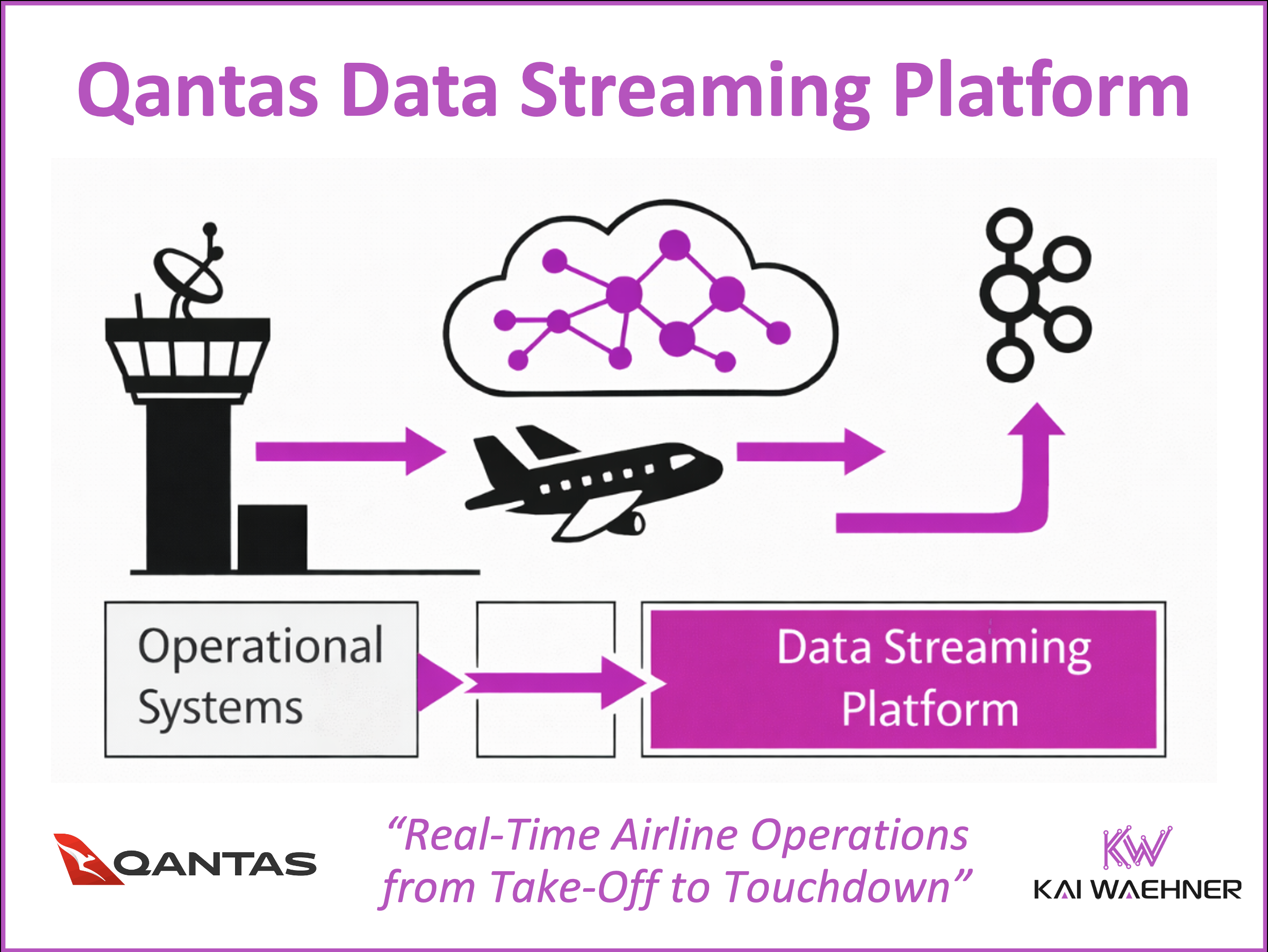
This blog post explores how data streaming transforms airline operations by enabling real-time visibility, faster decision-making, and improved customer experience. Using Qantas as a leading

Rivian and Volkswagen, through their joint venture RV Tech, process high-frequency telemetry from connected vehicles using Apache Kafka and Apache Flink. With a shift left
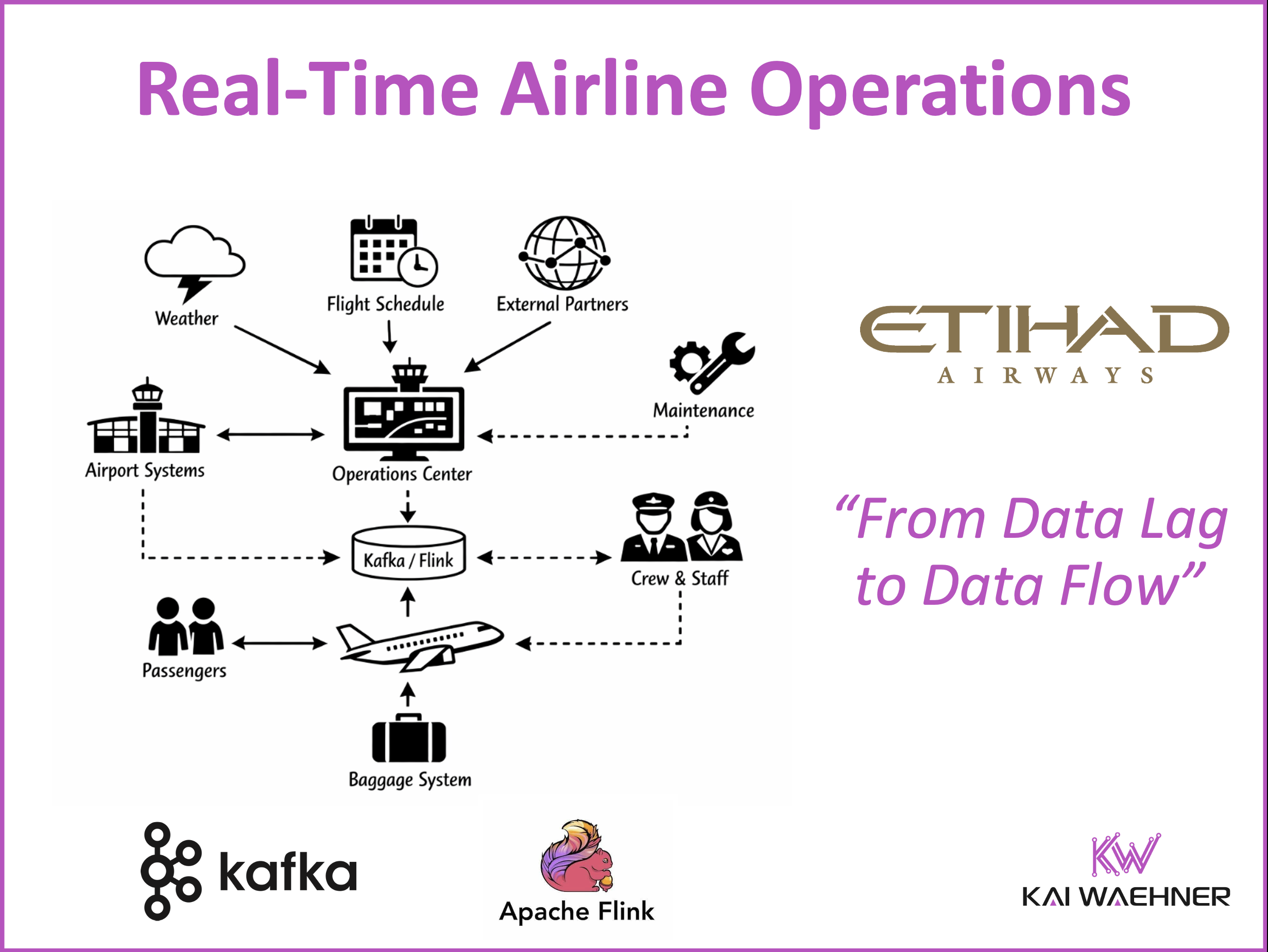
Airlines face constant pressure to deliver reliable service while managing complex operations and rising customer expectations. This blog post explores how Etihad Airways uses real-time

Running Apache Flink on a mainframe may sound surprising, but it is already happening and for good reason. As modern mainframes like IBM z17 evolve

Each year brings new momentum to the data streaming space. In 2026, six key trends stand out. Platforms and vendors are consolidating. Diskless Kafka and




You need to load content from reCAPTCHA to submit the form. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Turnstile. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Vimeo. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from YouTube. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou need to load content from reCAPTCHA to submit the form. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Elfsight. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Facebook. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More Information