
Apache Kafka
Nine years at Confluent: from a Silicon Valley startup with 100 people to an $11 billion IBM acquisition. A personal reflection on the Apache Kafka

Nine years at Confluent: from a Silicon Valley startup with 100 people to an $11 billion IBM acquisition. A personal reflection on the Apache Kafka
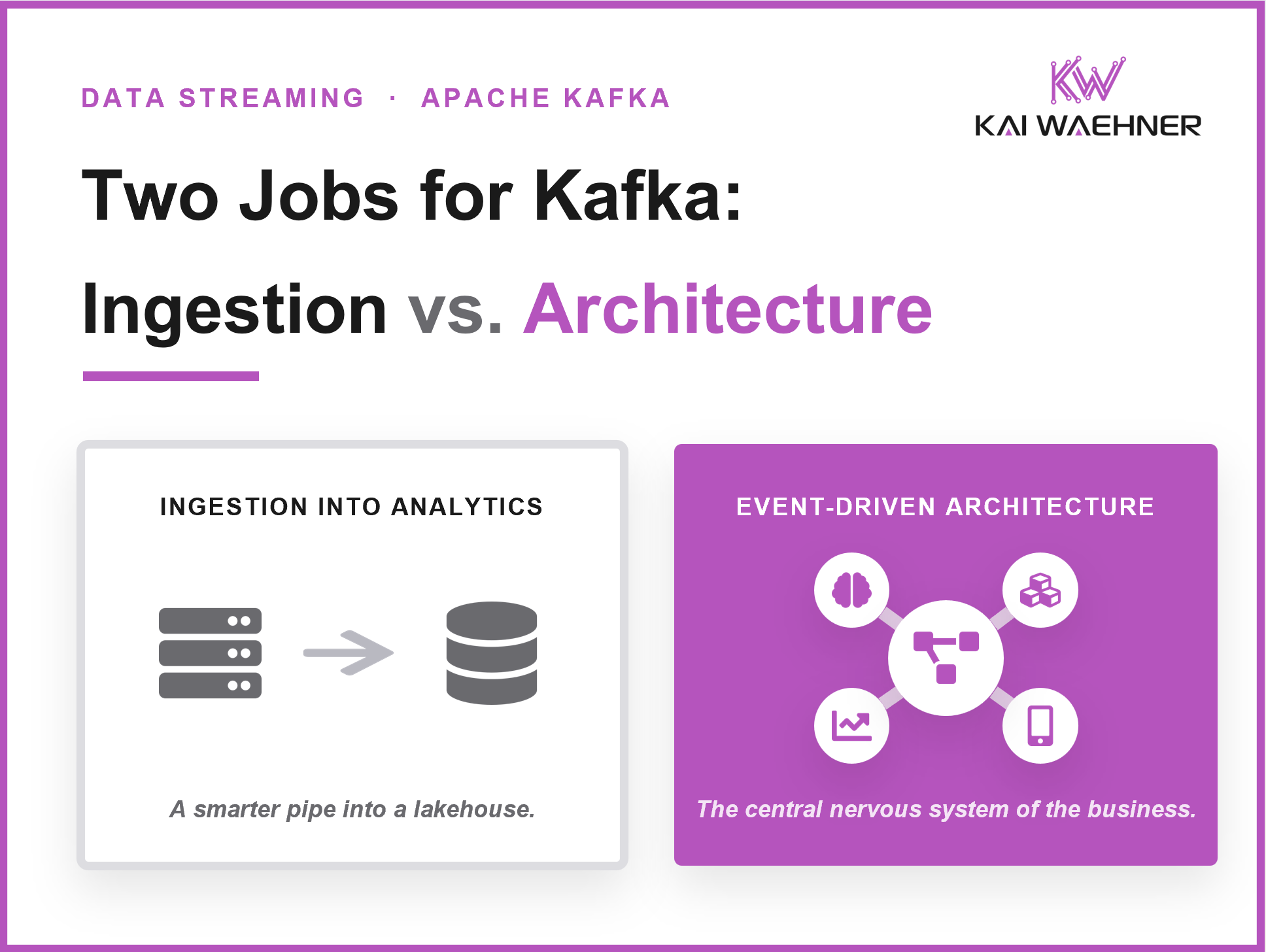
Databricks and Snowflake now speak the Kafka protocol. But using the Kafka API to feed a lakehouse is very different from running Kafka as the
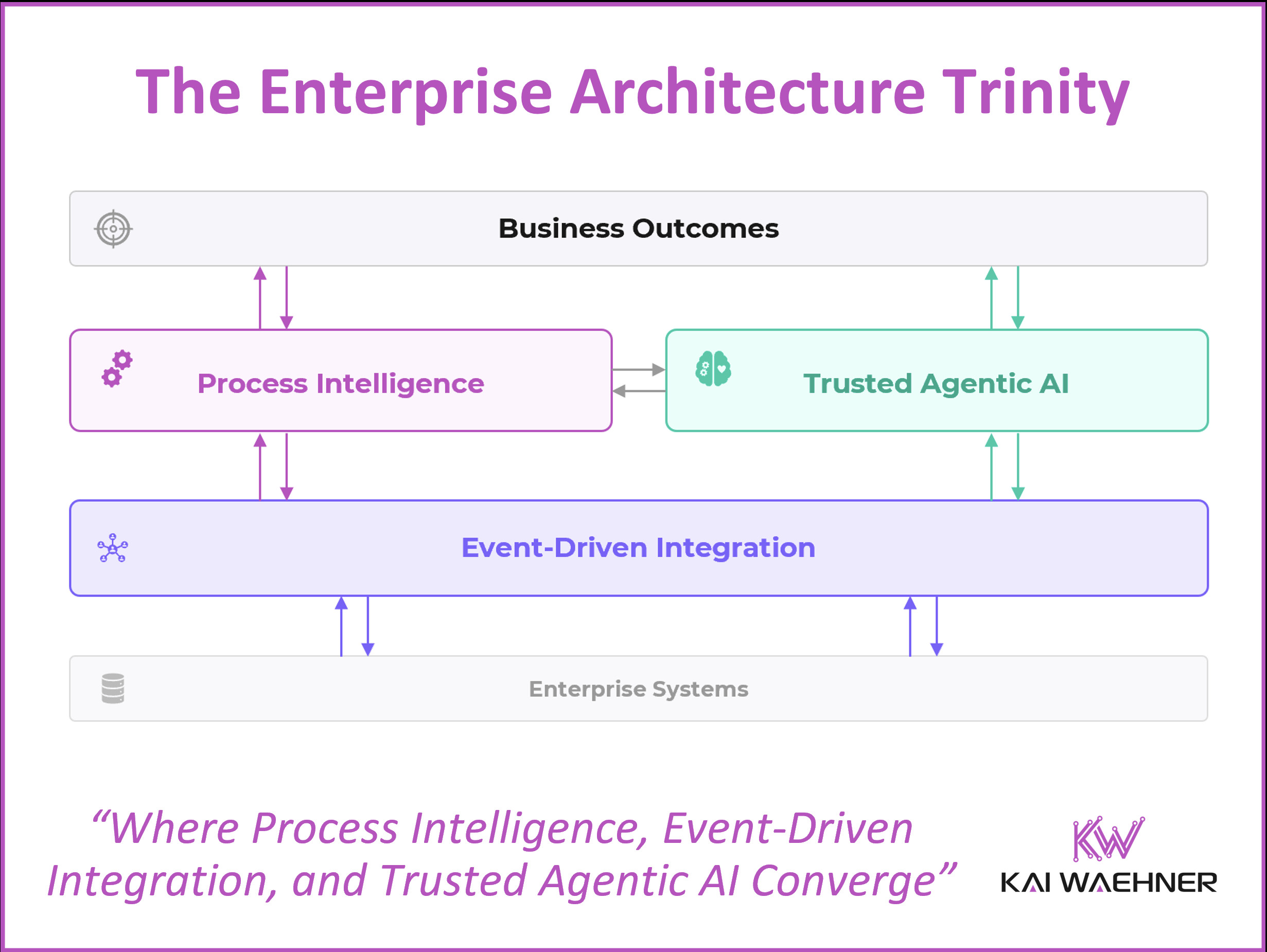
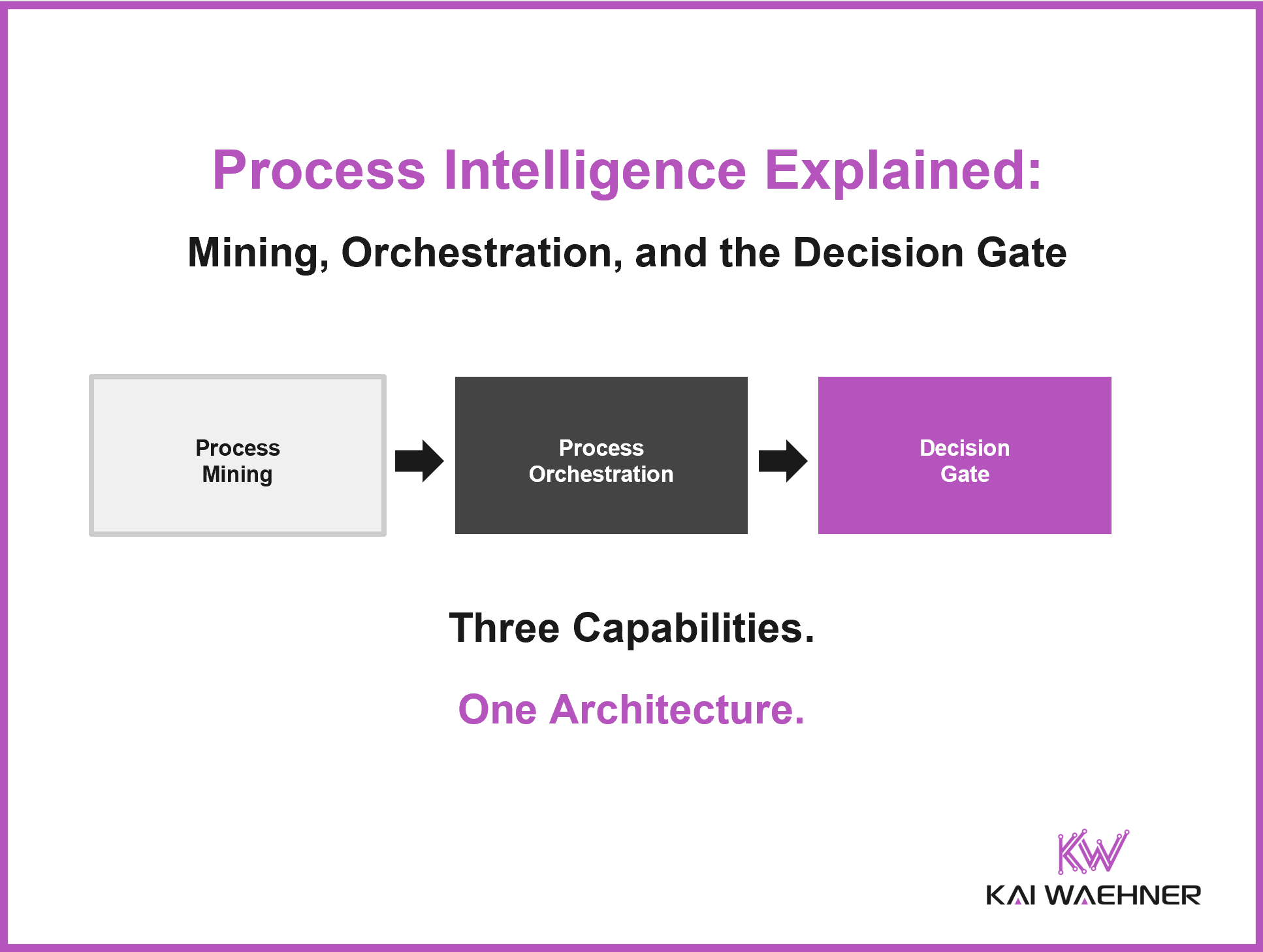
Agentic AI without governed processes is fast but ungoverned. Event-driven integration without process intelligence moves data but not decisions. Process intelligence without live data automates
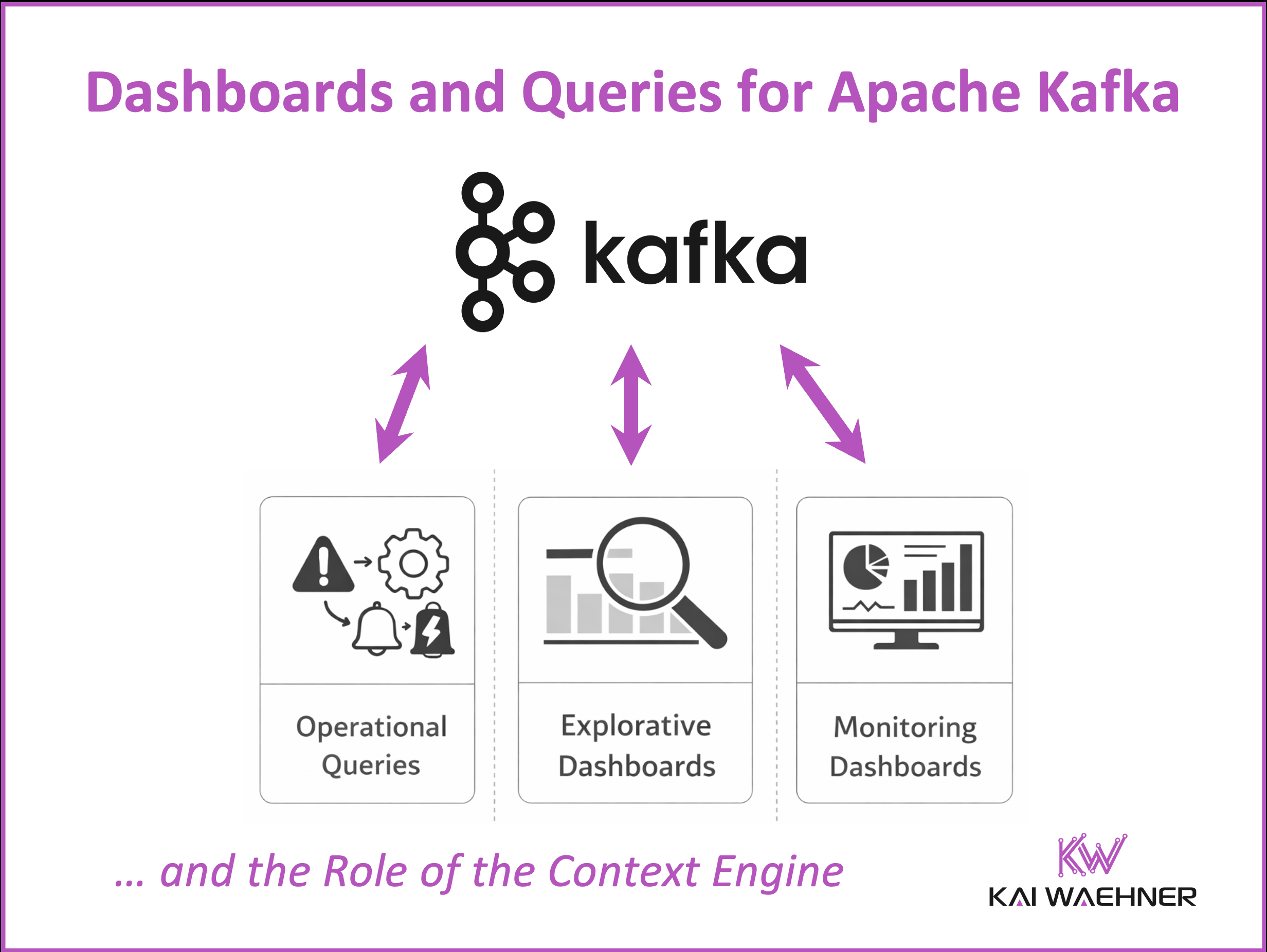
Dashboards are a popular way to make streaming data visible and useful, but they are not always the right solution. This blog post explains when
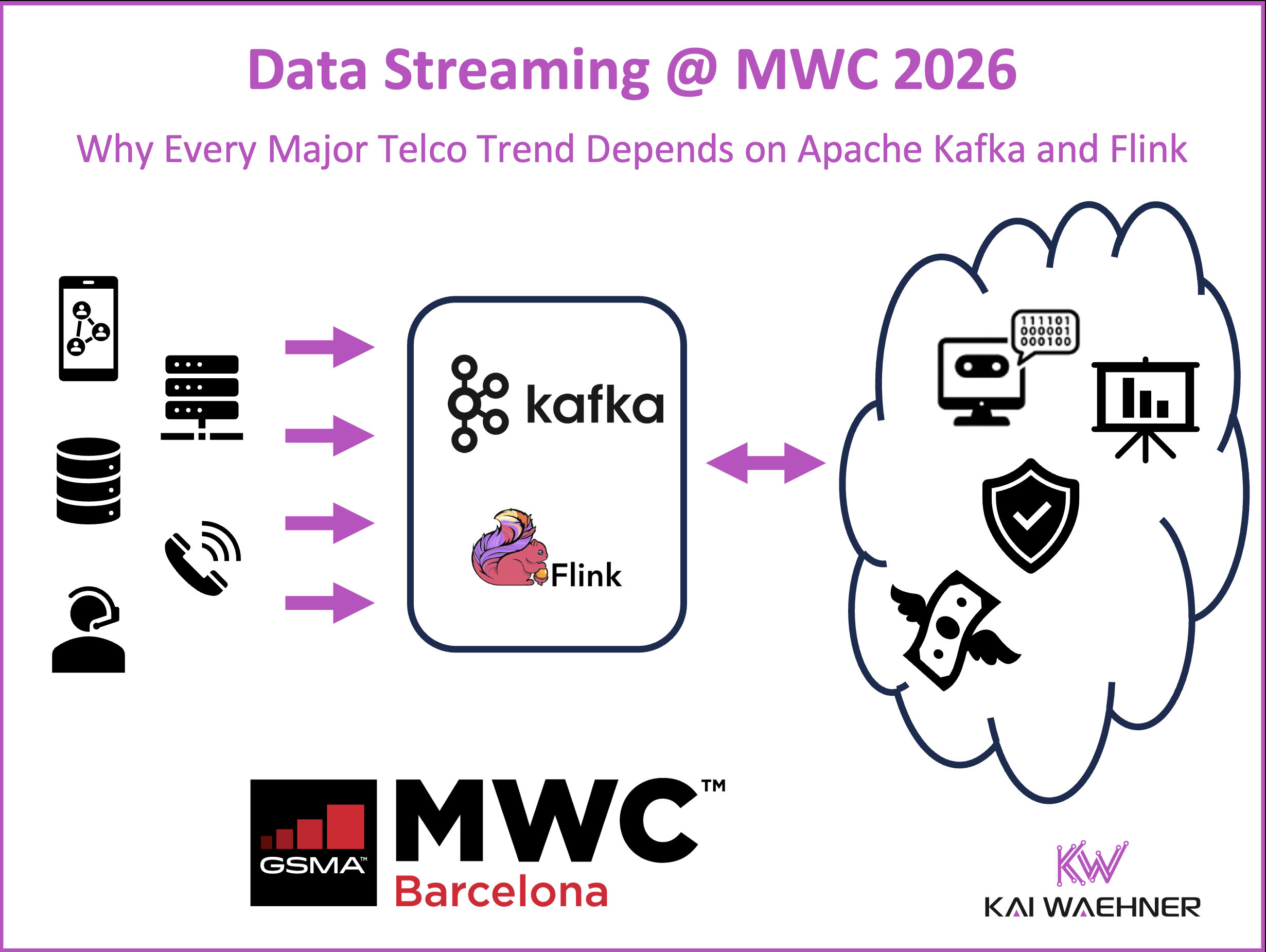
Mobile World Congress (MWC) 2026 highlights the shift from batch systems to real time data streaming in telecom. AI and agentic automation, network APIs, sovereign

The second edition of The Ultimate Data Streaming Guide is now available as a free eBook. It includes over 70 use cases, over 20 customer

Diskless Kafka is transforming how fintech and financial services organizations handle observability and log analytics. By using the Kafka protocol with cloud-native object storage, companies
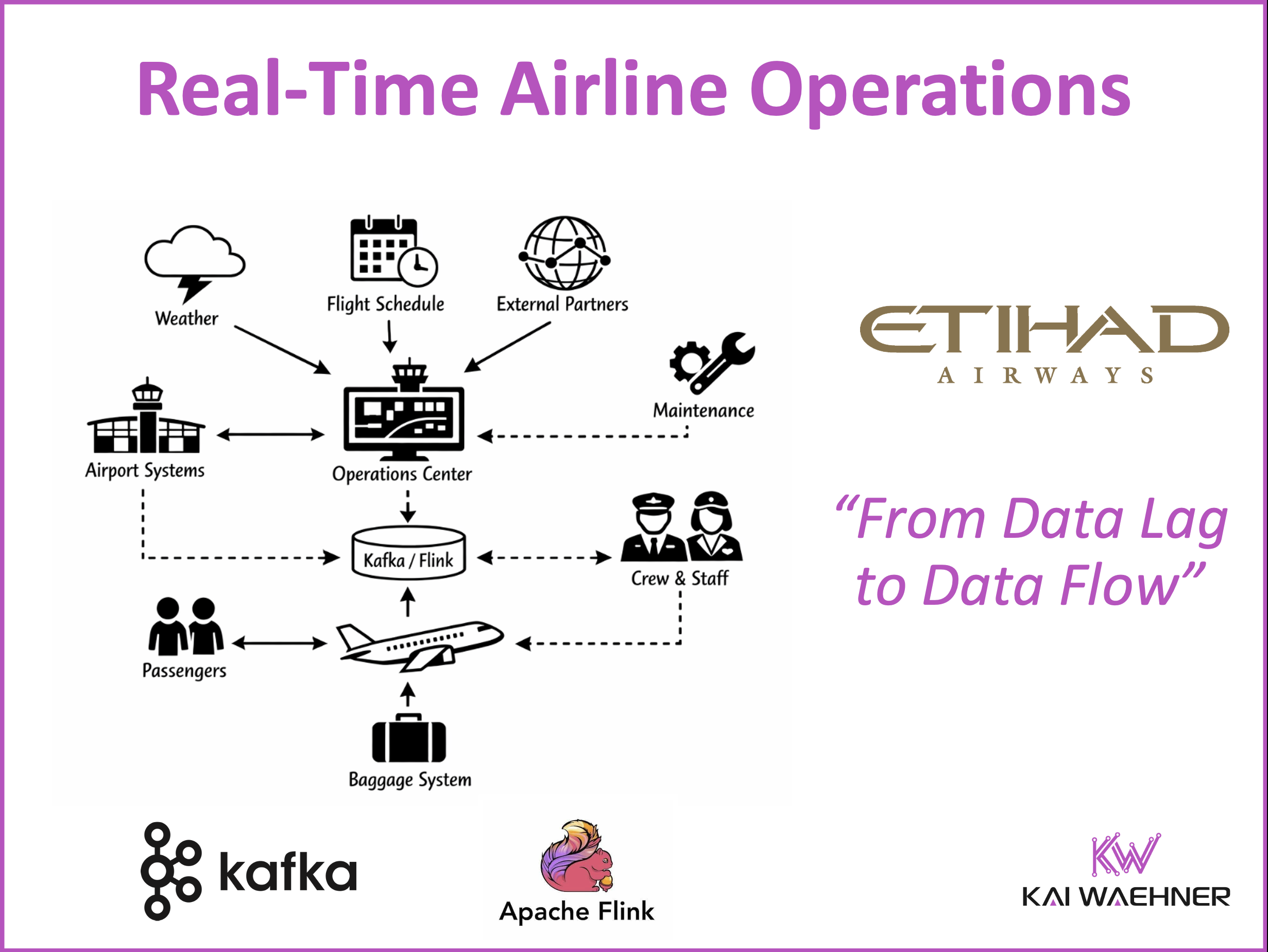
Airlines face constant pressure to deliver reliable service while managing complex operations and rising customer expectations. This blog post explores how Etihad Airways uses real-time
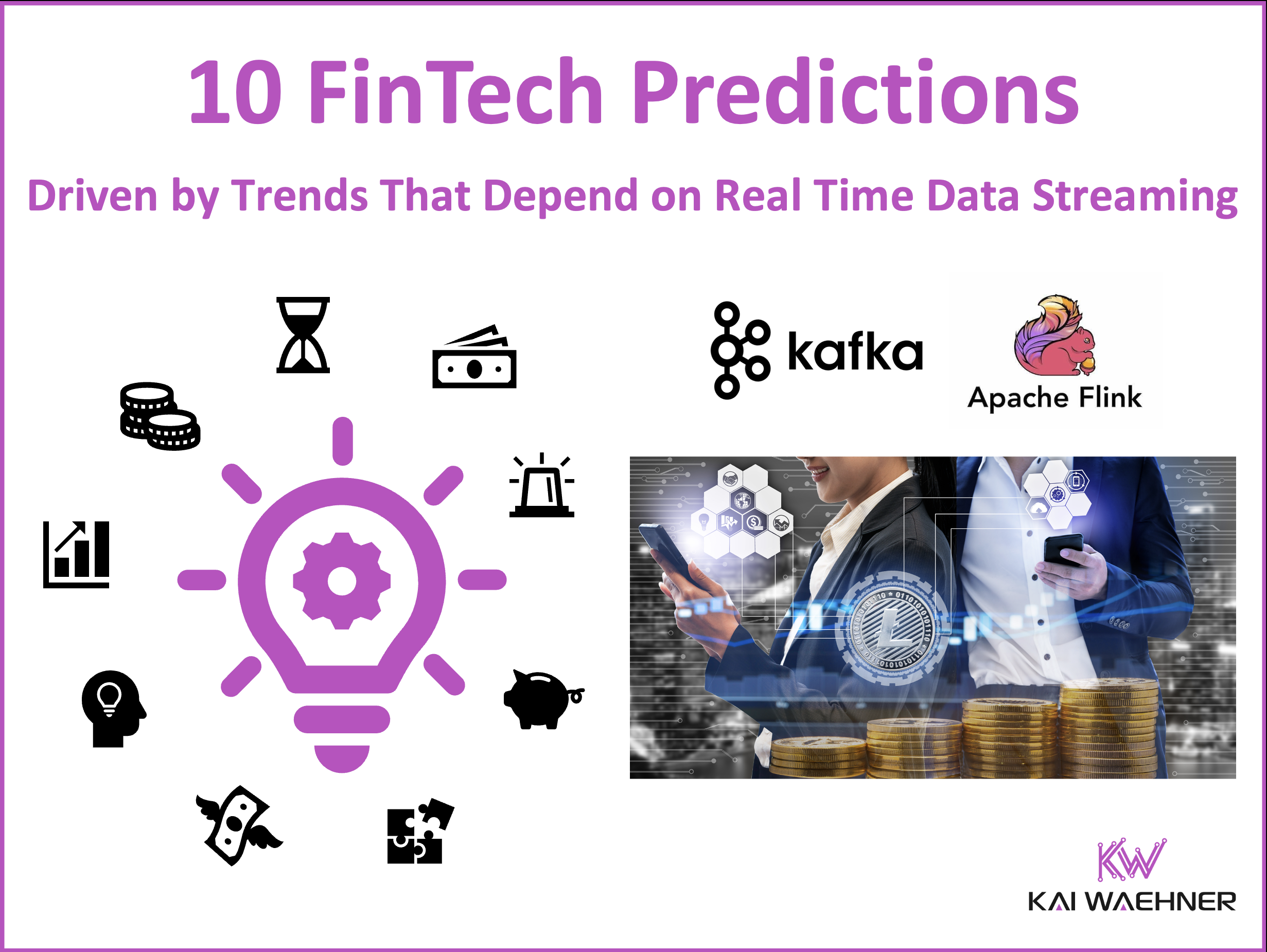
Financial services companies are moving from batch processing to real time data flow. A data streaming platform enables financial institutions to connect systems, process events

Each year brings new momentum to the data streaming space. In 2026, six key trends stand out. Platforms and vendors are consolidating. Diskless Kafka and

You need to load content from reCAPTCHA to submit the form. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Turnstile. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Vimeo. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from YouTube. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou need to load content from reCAPTCHA to submit the form. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Elfsight. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Facebook. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More Information