
Alibaba
The cloud revolution has reshaped how businesses deploy and manage data streaming with solutions like Apache Kafka and Flink. Distinctions between SaaS and PaaS models

The cloud revolution has reshaped how businesses deploy and manage data streaming with solutions like Apache Kafka and Flink. Distinctions between SaaS and PaaS models
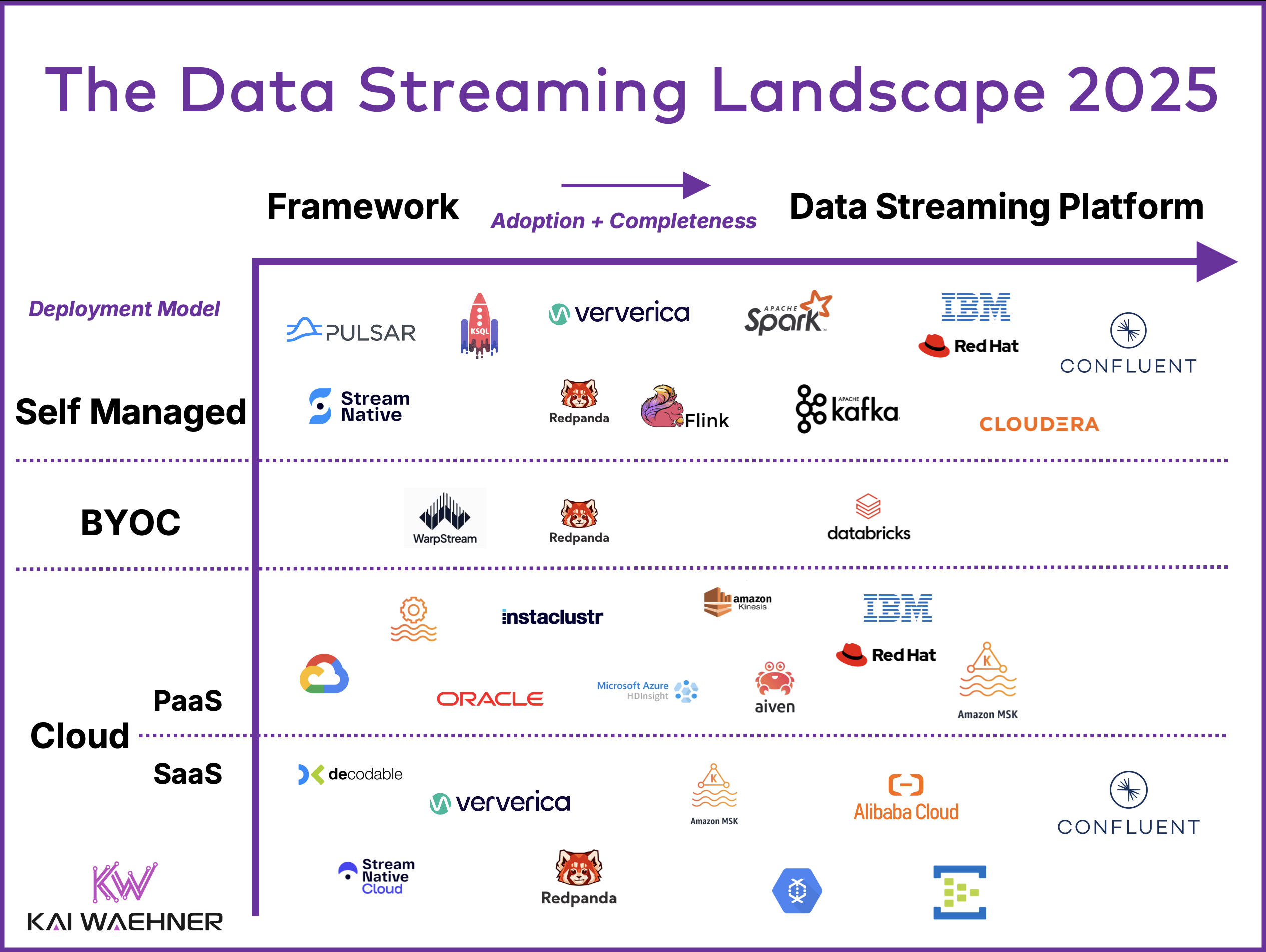
Data streaming is a new software category. It has grown from niche adoption to becoming a fundamental part of modern data architecture, leveraging open source
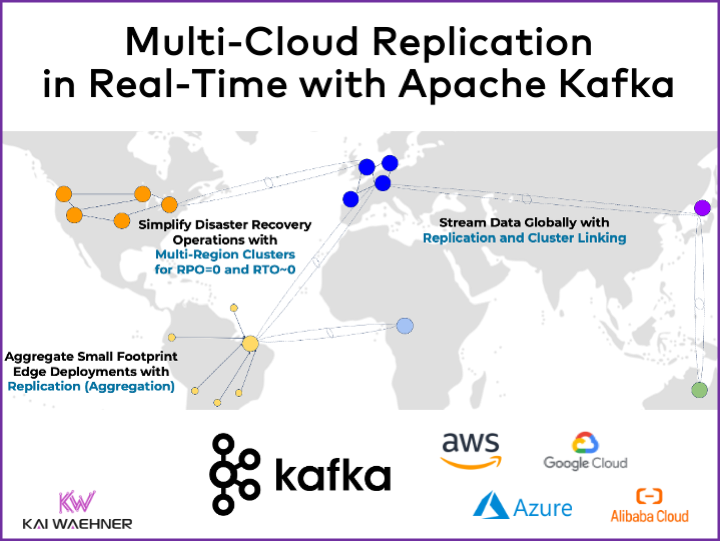
Multiple Apache Kafka clusters are the norm; not an exception anymore. Hybrid integration and multi-cloud replication for migration or disaster recovery are common use cases.
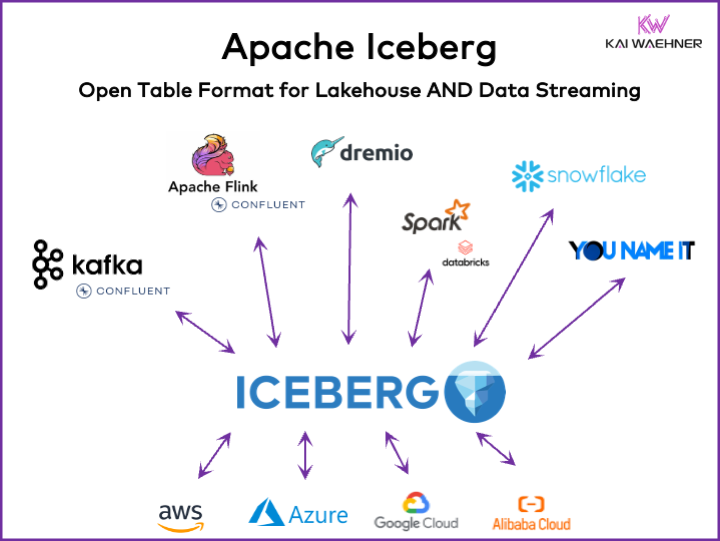
An open table format framework like Apache Iceberg is essential in the enterprise architecture to ensure reliable data management and sharing, seamless schema evolution, efficient

Google announced its Apache Kafka for BigQuery cloud service at its conference Google Cloud Next 2024 in Las Vegas. Welcome to the data streaming club
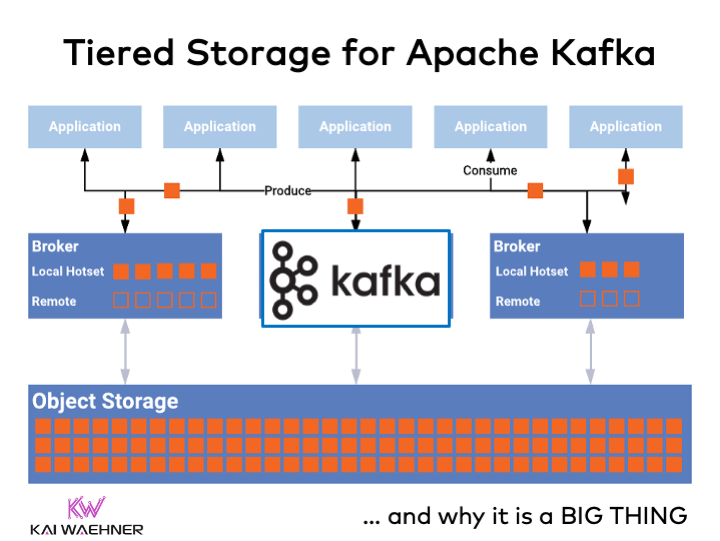
Apache Kafka added Tiered Storage to separate compute and storage. The capability enables more scalable, reliable and cost-efficient enterprise architectures. This blog post explores the

This blog post explores the state of data streaming in 2023 for digital natives born in the cloud. Data streaming allows integrating and correlating data
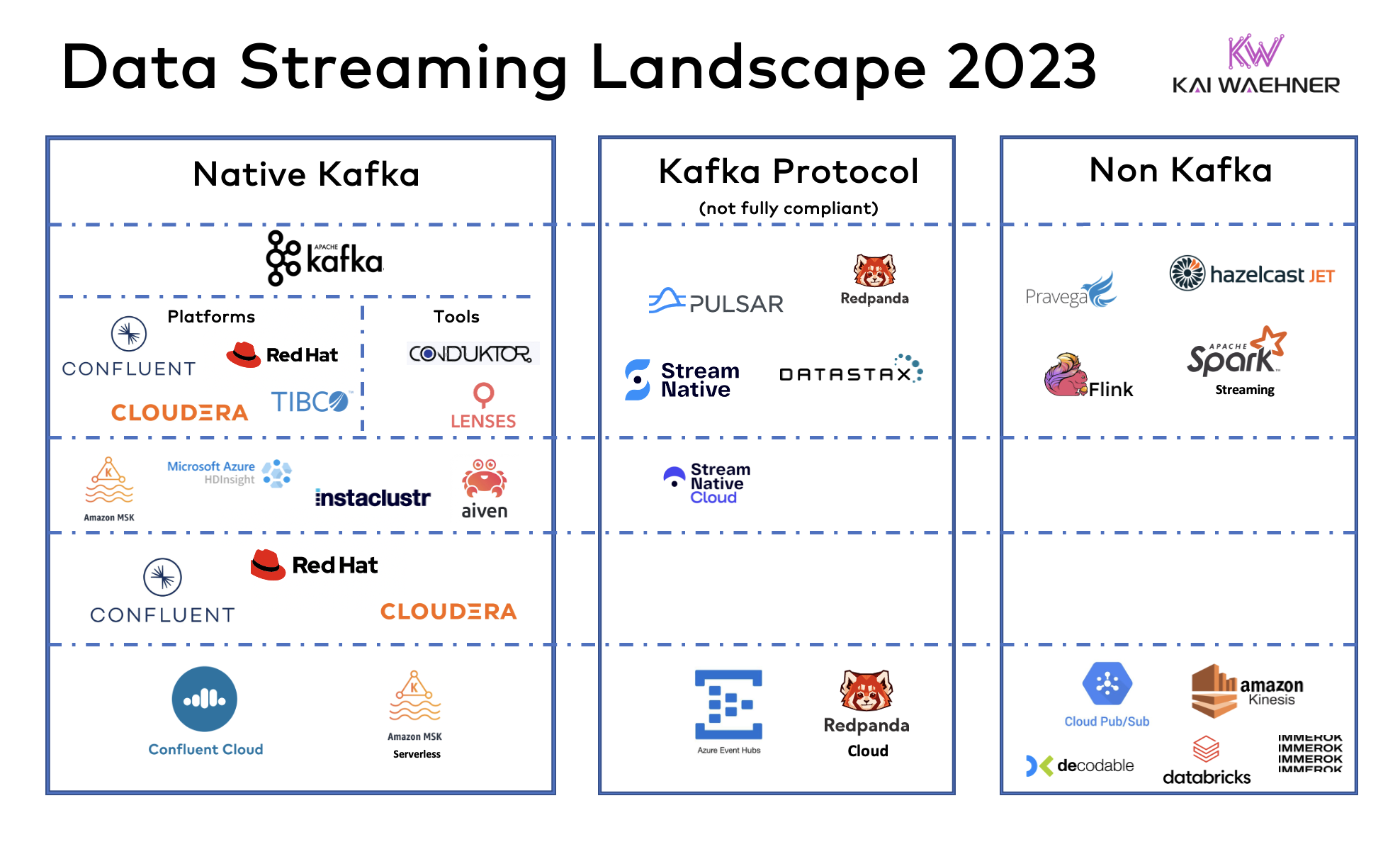
Data streaming is a new software category to process data in motion. Apache Kafka is the de facto standard used by over 100,000 organizations. Plenty

If there were a buzzword of the hour, it would undoubtedly be “data mesh”! This new architectural paradigm unlocks analytic and transactional data at scale
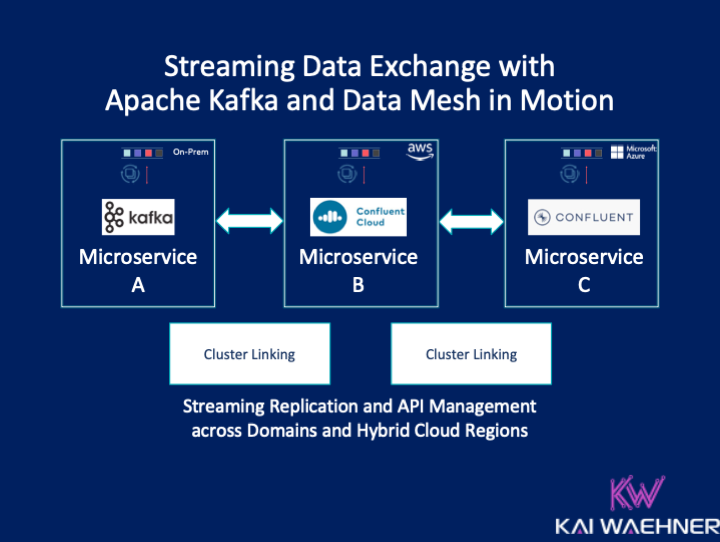
Data Mesh is a new architecture paradigm that gets a lot of buzzes these days. This blog post looks into this principle deeper to explore




You need to load content from reCAPTCHA to submit the form. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Turnstile. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Vimeo. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from YouTube. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou need to load content from reCAPTCHA to submit the form. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Elfsight. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Facebook. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More Information