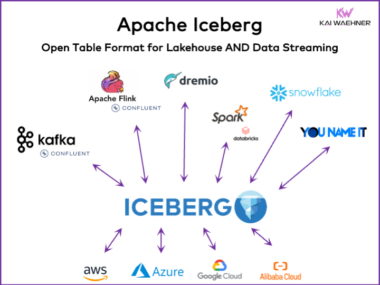
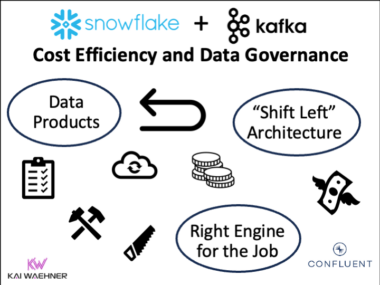
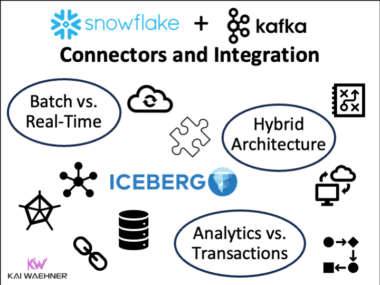
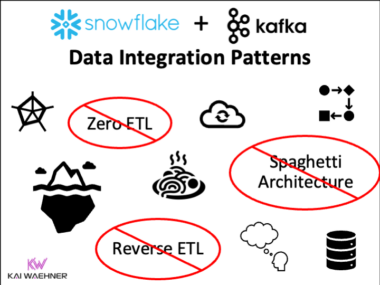
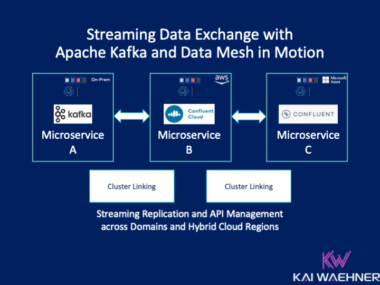
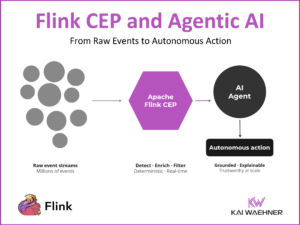
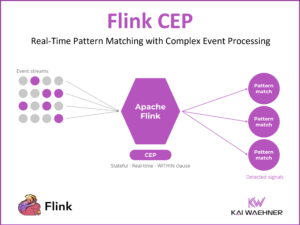
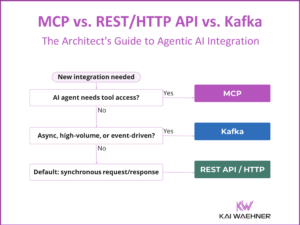
Shift Left Architecture at Siemens: Real-Time Innovation in Manufacturing and Logistics with Data Streaming
Industrial enterprises face increasing pressure to move faster, automate more, and adapt to constant change—without compromising reliability. Siemens Digital Industries addresses this challenge by combining real-time data streaming, modular design, and Shift Left principles to modernize manufacturing and logistics. This blog outlines how technologies like Apache Kafka, Apache Flink, and Confluent Cloud support scalable, event-driven architectures. A real-world example from Siemens’ Modular Intralogistics Platform illustrates how this approach improves data quality, system responsiveness, and operational agility.