
The integration between Apache Kafka and Snowflake is often cumbersome. Options include near real-time ingestion with a Kafka Connect connector, batch ingestion from large files, or leveraging a standard table format like Apache Iceberg. This blog post explores the alternatives and discusses its trade-offs. The end shows how data streaming helps with hybrid architectures where data needs to be ingested from the private data center into Snowflake in the public cloud.
Blog Series: Snowflake and Apache Kafka
Snowflake is a leading cloud-native data warehouse. Its usability and scalability made it a prevalent data platform in thousands of companies. This blog series explores different data integration and ingestion options, including traditional ETL / iPaaS and data streaming with Apache Kafka. The discussion covers why point-to-point Zero-ETL is only a short term win, why Reverse ETL is an anti-pattern for real-time use cases and when a Kappa Architecture and shifting data processing “to the left” into the streaming layer helps to build transactional and analytical real-time and batch use cases in a reliable and cost-efficient way.
Blog series:
- Snowflake Integration Patterns: Zero ETL and Reverse ETL vs. Apache Kafka
- THIS POST: Snowflake Data Integration Options for Apache Kafka (including Iceberg)
- Apache Kafka + Flink + Snowflake: Cost Efficient Analytics and Data Governance
Subscribe to my newsletter to get an email about the next publications.
Data Ingestion from Apache Kafka into Snowflake (Batch vs. Streaming)
Several options exist to ingest data into Snowflake. Criteria to evaluate the options include complexity, latency, throughout and cost.
The article “Streaming on Snowflake” by Paul Needleman explored the three common architecture patterns for data ingestion from any data source into Snowflake:
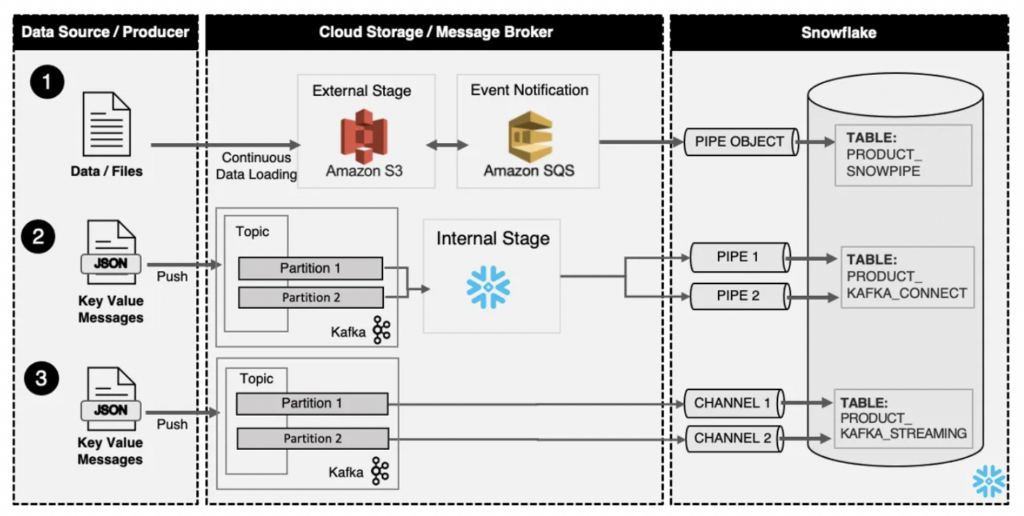
Paul’s article described the architecture options without and with Kafka. The numbered list below follows the numbers in the upper diagram:
- Snowpipe — This solution provides Cloud storage (e.g., Amazon S3, Azure Blob Storage, Google Cloud Storage) the ability for serverless alerting Snowflake to auto-ingest data upon arrival. Once a file lands, Snowflake is alerted to pick up and process the file. Snowpipe is used for micro-batch file transfer, not real-time message ingestion.
- Kafka Connector — This connector provides a simple yet elegant solution to connect Kafka Topics with Snowflake, abstracting the complexity through Snowpipe. The Kafka Topics write the data to a Snowflake-managed internal stage, which is auto-ingested to the table using Snowpipe. The internal stage and pipe objects are created automatically as part of the process.
- Kafka with Snowpipe Streaming — This builds upon the first two approaches and allows for a more native connection between Snowflake and Kafka through a new channel object. This object seamlessly streams message data into a Snowflake table without needing first to store the data. The data is also stored in an optimized format to support the low-latency data interval.
Read the article “Streaming on Snowflake” for more details about these options.
Snowflake = SaaS => Integration Layer Should Be SaaS!
Snowflake is one of the first most successful true cloud data warehouses, i.e. fully managed with no need to operate and worry about the infrastructure. SaaS, Snowflake offers benefits such as scalability, ease of use, vendor-managed updates and maintenance, multi-cloud support, enhanced security, cost-effectiveness with consumption-based pricing, and global accessibility. These advantages make it an attractive choice for organizations looking to leverage a modern and efficient data warehousing solution.
The same benefits exist for fully managed data integration solutions. It does not matter if you use open source-based technologies (e.g., Apache Camel), a traditional iPaaS middleware, or a data streaming solution like Kafka.
I wrote a detailed article comparing iPaaS offerings like Dell Boomi, SnapLogic, Informatica, and fully managed data streaming cloud platforms like Confluent Cloud or Amazon MSK. Read this article to understand why your next integration platform should be fully managed the same way Snowflake is.
Example: Data Ingestion with Confluent Cloud and Snowpipe Streaming
Confluent Cloud and Snowflake are a perfect combination for fully managed end-to-end data pipelines. For instance, connecting to a data source like Salesforce CRM via CDC, streaming data through Kafka, and ingesting the events into Snowflake is entirely fully managed.
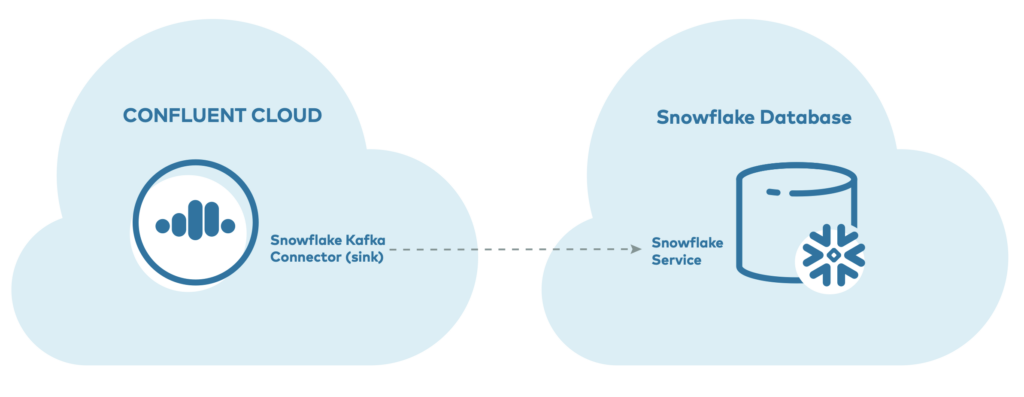
Using Kafka Connect with Snowpipe Streaming has several advantages:
- Faster, more efficient data pipelines
- Reduced architectural complexity
- Support for exactly-once delivery
- Ordered ingestion
- Error handling with dead-letter queue (DLQ) support
Streaming ingestion is not meant to replace file-based ingestion. Rather, it augments the existing integration architecture for data-loading scenarios where it makes sense, such as
- Low-latency telemetry analytics of user-application interactions for clickstream recommendations
- Identification of security issues in real-time streaming log analytics to isolate threats
- Stream processing of information from IoT devices to monitor critical assets
Why should you NOT only use Snowpipe Streaming mode? Cost. Snowflake has different pricing models for the ingestion modes.
Processing Large Files in Kafka before Snowflake Ingestion?
A last aspect of data ingestion options via Kafka into Snowflake: What to do with large files?
One of the most common use cases for data ingestion into Snowflake is large CSV, XML or JSON files generated from batch legacy analytics systems.
Option 1: Send the large files via Kafka into Snowflake and process it in the data warehouse. Apache Kafka was never built for large messages. Nevertheless, more and more projects send and process 1Mb, 10Mb, and even bigger files and other large payloads via Kafka into Snowflake. Why? Because it just works.
Option 2: Apache Kafka splits up and chunks large messages into small pieces.
For the latter approach, ideally, events are processed line by line, if possible. The enormous benefit of this approach is bringing even batch-based monolithic systems into an event-driven architecture. Snowflake and other downstream applications consume the events in near real-time. This architecture leverages the Composed Message Processor Enterprise Integration Pattern (EIP):
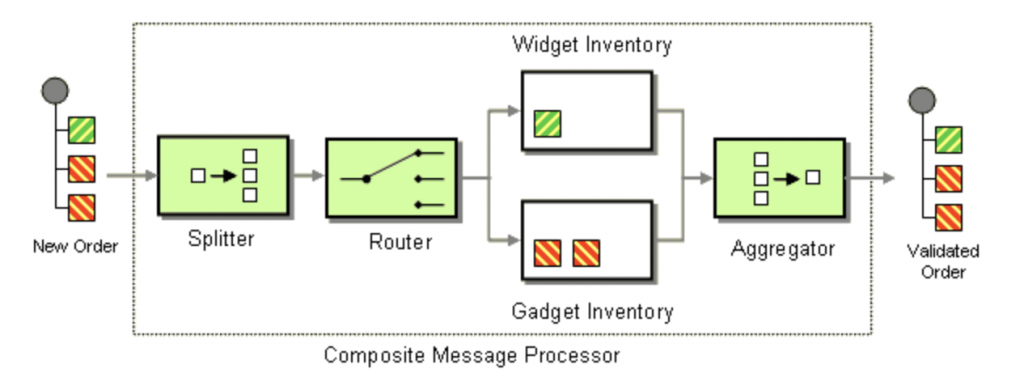
For a deep dive including various use cases and customer stories, check out the article “Handling Large Messages With Apache Kafka“.
Bi-Directional Integration between Apache Kafka and Snowflake with Apache Iceberg
After covering batch, file, and streaming integration from Kafka to Snowflake, let’s move to the latest innovation that is more compelling than old the “legacy approaches”: Native integration between Apache Kafka and Snowflake using Apache Iceberg.
Apache Iceberg is the leading open-source table format for storing large-scale structured data in cloud object stores or distributed file systems, designed for high-performance querying and analytics. It provides features such as schema evolution, time travel, and data versioning, making it well-suited for data lakes and modern data architectures.
Snowflake Support for Apache Iceberg
Snowflake already supports Apache Iceberg.
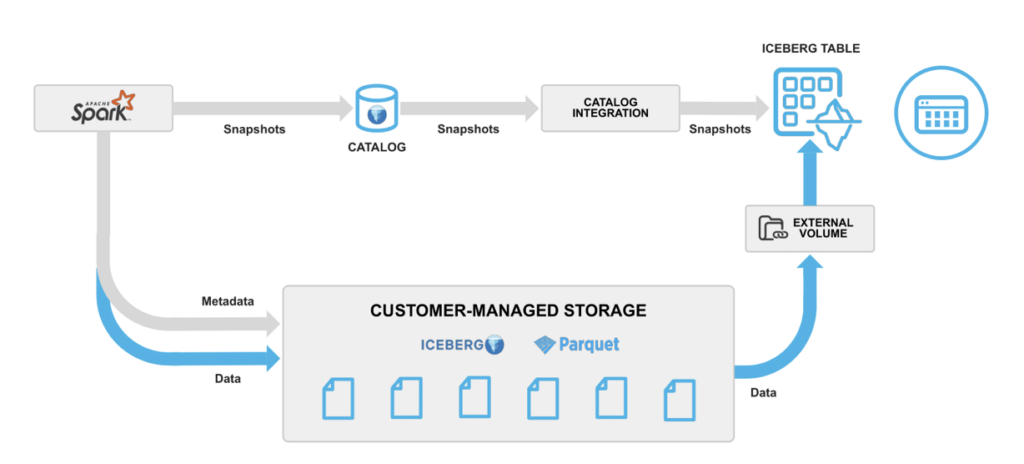
Augusto Kiniama Rosa points out in his Overview of Snowflake Apache Iceberg Tables:
“Iceberg will always use customer-controlled external storage, like an AWS S3 or Azure Blog Storage. Snowflake Iceberg Tables support Iceberg in two ways: an Internal Catalog (Snowflake-managed catalog) or an externally managed catalog (AWS Glue or Objectstore).”
I won’t start a flame war of Apache Iceberg vs. Apache Hudi and Databricks’ Delta Lake here. It reminds me about the containers wars with Kubernetes, Cloud Foundry and Apache Mesos. In the end, Kubernetes won. The competitors adopted it. The same seems to be happening with Iceberg. If not, the as principles and benefits will be the same, no matter if the future is Iceberg or a competing technology. As it seems today like Iceberg will win this war, I focus on this technology in the following sections.
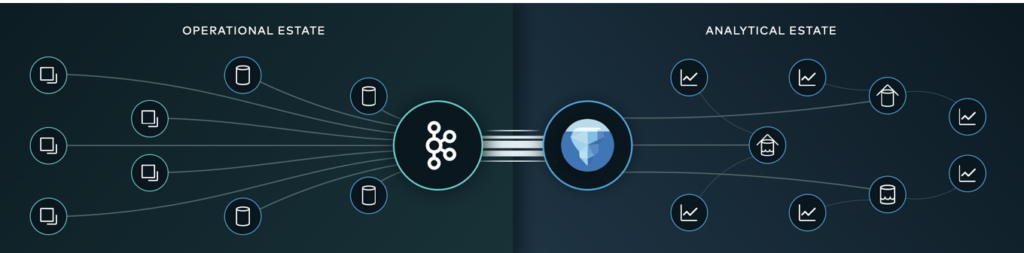
Kafka and Iceberg to Unify Transactional and Analytical Workloads
Any data source can feed data via Apache Kafka directly into Snowflake (or any other analytics engine) as Apache Iceberg table. This solves the challenges of the above described integration options between Kafka and Snowflake. Operational data is accessible to the analytical world without a complex, expensive, and fragile process.
Confluent Tableflow: Fully Managed Kafka-Iceberg Integration
Confluent announced Tableflow at Kafka Summit 2024 in London, UK, to demonstrate its fully managed out-of-the-box integration between a Kafka Topic and Schema and an Iceberg Tables in Confluent Cloud. Confluent’s Marc Selwan writes:
“In the past, there has been a tight coupling of tables (storage) and query engines. In recent years, we’ve witnessed the rise of ‘headless’ data infrastructure where companies are building a more open lakehouse in cloud object storage that is accessible by many tools.
Just like the Apache Kafka API has evolved to be the de facto open standard for data streaming, we’re seeing Apache Iceberg grow into the de facto open-table standard for large-scale datasets stored in lakehouses. We’ve seen its ecosystem grow with robust tooling and support from compute engines such as Apache Spark, Snowflake, Amazon Athena, Dremio, Trino, Apache Druid, and many others.
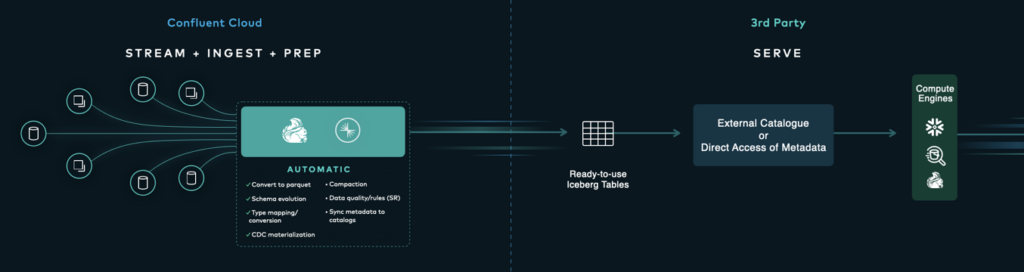
We believe the rise of open-table formats and the ‘headless’ data infrastructure is being driven by the needs of data engineers evolving beyond the tight coupling of table to computing platform. These factors made Apache Iceberg support a natural first choice for us.”
Check out Confluent’s blog post Announcing Tableflow. Other Kafka vendors will likely provide Apache Iceberg support in the near future, too. I am really excited about this development of unifying operational and analytics with a standardized interface across open source frameworks and cloud solutions.
Hybrid Architectures with Kafka On-Premise and in the Public Cloud for Snowflake Integration
Snowflake is only available in the public cloud on AWS, GCP or Azure. Most companies across industries follow a cloud-first strategy for new applications. However, as existing companies exist for years or decades, they are typically not born in the cloud. Therefore, hybrid cloud architectures are the new black for most companies. Apache Kafka is the best approach to synchronize and replicate data in a single pipeline with low latency, reliability and guaranteed ordering from the data center to the public cloud.

Legacy infrastructure has to be maintained, integrated, and (maybe) replaced over time. Data Streaming with the Apache Kafka ecosystem is a perfect technology for building hybrid synchronization in real-time at scale. This enables bidirectional integration for transactional and analytical workloads without creating a spaghetti architecture with various point-to-point connections between on-prise and the cloud.
There is no Silver Bullet for Kafka to Snowflake Integration!
Various data integration options are available between Apache Kafka and Snowflake. Kafka Connect connectors are a great option, no matter if you do batch or near real-time ingestion. Even large files can be ingested via data streaming using the right enterprise integration patterns.
A new and innovative approach is Apache Iceberg as the integration interface. The standard table format allows connecting from Snowflake; and any other analytics engine. But data needs to be stored only once. Kafka to Iceberg integration is even more interesting as it unifies transactional and analytical workloads.
Data Streaming also helps with hybrid integrations where data needs to be replicated from the on-premise data center into the public cloud in near real-time with consistent near real-time synchronization.
How do you integrate between Kafka and Snowflake? Do you already look at Apache Iceberg? Or maybe even another Table Format like Apache Hudi or Databricks’ Delta Lake? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.
