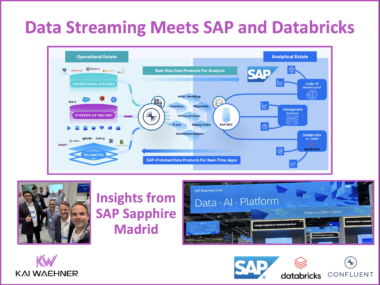
Data Streaming Meets the SAP Ecosystem and Databricks – Insights from SAP Sapphire Madrid
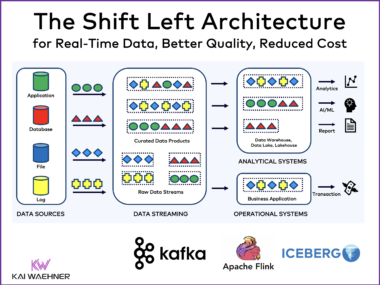
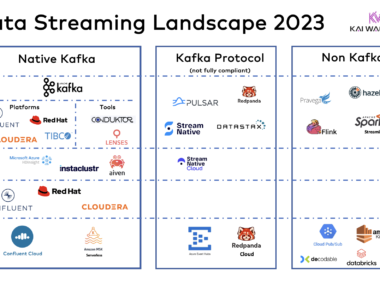
SAP Sapphire 2025 in Madrid brought together global SAP users, partners, and technology leaders to showcase the future of enterprise data strategy. Key themes included SAP’s Business Data Cloud (BDC) vision, Joule for Agentic AI, and the deepening SAP-Databricks partnership. A major topic throughout the event was the increasing need for real-time integration across SAP and non-SAP systems—highlighting the critical role of event-driven architectures and data streaming platforms like Confluent. This blog shares insights on how data streaming enhances SAP ecosystems, supports AI initiatives, and enables industry-specific use cases across transactional and analytical domains.