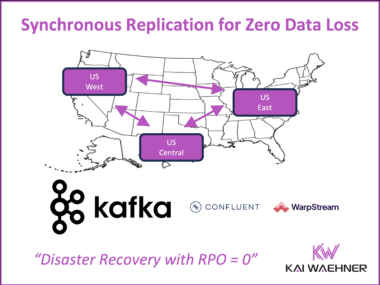
Multi-Region Kafka using Synchronous Replication for Disaster Recovery with Zero Data Loss (RPO=0)
Apache Kafka is the backbone of real-time data streaming. Choosing the right deployment model – self-managed, fully managed, or bring-your-own-cloud (BYOC) – is a strategic decision. It affects performance, compliance, and cost. This article explains the most common Kafka deployment strategies and highlights the innovation of synchronous multi-region replication to achieve zero data loss (RPO=0). Alternatives like stretched Kafka clusters, Confluent Multi-Region Clusters (MRC), and WarpStream offer different paths to RPO=0. They support critical workloads with strong durability and high availability. For mission critical and regulated use cases, zero data loss is no longer a future goal. It is now achievable with the right architecture.