Workloads for analytics and transactions have very unlike characteristics and requirements. The use cases differ significantly. SLAs are very different, too. Many people think that Apache Kafka is not built for transactions and should only be used for big data analytics. This blog post explores when and how to use Kafka in resilient, mission-critical architectures and when to use the built-in Transaction API.
Analytical and transactional workloads
- In OLTP (online transaction processing), information systems typically facilitate and manage transaction-oriented applications.
- In OLAP (online analytical processing), information systems generally execute much more complex queries, in a smaller volume, for the purpose of business intelligence or reporting rather than to process transactions.
There are some overlaps in some use cases and products. Hence, I use the more generic terms “transactions” and “analytics” in this blog post.
Analytical workloads
Analytical workloads have the following characteristics:
- Processing large amounts of information for creating aggregates
- Read-only queries and (usually) batch-write data loads
- Supporting complex queries with multiple steps of data processing, join conditions, and filtering
- Highly variable ad hoc queries, many of which may only be run once, ever
- Not mission-critical, meaning downtime or data loss is not good, but in most cases not a disaster for the core business
Analytics solutions
Analytics solutions exist on-premises and in all major clouds. The tools differ regarding their capabilities and sweet spots. Examples include:
- Redshift (Amazon Web Services)
- BigQuery (Google Cloud)
- Snowflake
- Hive / HDFS / Spark
- And many more!
Transactional workloads
Transactional workloads have unique characteristics and SLAs compared to analytical workloads:
- Manipulating one object at a time (often across different systems)
- Create Read Update and Delete (CRUD) operations inserting data one object at a time or updating existing data (often across different systems)
- Precisely managing state with guarantees about what has or hasn’t been written to disk
- Supporting many operations per second in real-time with high throughput
- Mission-critical SLAs for uptime, availability, and latency of the end-to-end data communication
Transactional solutions
Transactional solutions include applications, databases, messaging systems, and integration middleware:
- IBM Mainframe (including CICS, IMS, DB2)
- TIBCO EMS
- PostgreSQL
- Oracle Database
- MongoDB
- And many more!
Often, a transactional workload has to guarantee ACID principles (i.e., all or nothing writes to different applications and technologies).
A mix of transactional and analytical workloads
Many solutions support a mix of transactional and analytical workloads.
For instance, many enterprises store transactional data in MongoDB but also process complex queries for analytics use cases in the same database. MongoDB started as document-based NoSQL database. In the meantime, it is a general-purpose database platform that also supports other forms of database queries like MongoDB provides graph and tree traversal capabilities:
Hence, focus on the business problem first. Then, you can decide if your existing infrastructure can solve the problem or if you need yet another one. But there is no silver bullet. A vendor-independent best of breed approach works best in most enterprise architectures I see in the success stories from the field.
Data at Rest vs. Data in Motion
Batch vs. real-time data processing is an important discussion you should have in every project. Statements like “batch processing is for analytics, real-time processing is for transactions” are not always correct. Real-time beats slow data in almost all use cases from a business value perspective. Nevertheless, batch processing is the better approach for some specific use cases.
Analytics platforms for batch processing
Data at Rest means to store data in a database, data warehouse, or data lake. This means that the data is processed too late in many use cases – even if a real-time streaming component (like Kafka) ingests the data. The data processing is still a web service call, SQL query, or map-reduce batch process away from providing a result to your problem.
Don’t get me wrong. Data at Rest is not a bad thing. Several use cases such as reporting (business intelligence), analytics (batch processing), and model training (machine learning) require this approach… If you do it right! Data at Rest can be used for transactional workloads, too!
Apache Kafka for real-time data streaming
The Kafka API is the De Facto Standard API for Data in Motion like Amazon S3 for object storage. Why is Kafka so successful? Real-time beats slow data in most use cases across industries.
The same cloud-native approach is required for event streaming as for the modern data lake. Building a scalable and cost-efficient infrastructure is crucial for the success of a project. Event streaming and data lake technologies are complementary, not competitive.
I will not explore the reasons and use cases for the success of Kafka in this post. Instead, check out my overview about Kafka use cases across industries for more details. Or read some of my vertical-specific blog posts.
In short, most added value comes from processing Data in Motion while it is relevant instead of storing Data at Rest and processing it later (or too late). Many analytical and transactional workloads use Kafka for this reason.
Apache Kafka for analytics
Even in 2022, many people think about Kafka as a data ingestion layer into data stores. This is still a critical use case. Enterprises use Kafka as the ingestion layer for different analytics platforms:
- Batch reporting and dashboards
- Interactive queries (using Tableau, Qlik, and similar tools)
- Data preparation for batch calculations, model training, and other analytics
- Connectivity into different data warehouses, data lakes, and other data sinks using a best of breed approach
But Kafka is much more than a messaging and ingestion layer. Here are a few analytics examples using Kafka for analytics (often with other analytics tools to solve a specific problem together):
- Data integration for various source systems using Kafka Connect and pre-built connectors (including real-time, near real-time, batch, web service, file, and proprietary interfaces)
- Decoupling and backpressure handling as the sink systems are often not ready for vast volumes of real-time data. Domain-driven design (DDD) for true decoupling is a crucial differentiator of Kafka compared to other middleware and message queues.
- Data processing at scale in real-time filters, transforms, generalizes, or aggregates incoming data sets before ingesting them into sink systems.
- Real-time analytics applied within the Kafka application. Many analytics platforms were designed for near real-time or batch workloads but not for resilient model scoring with low latency – especially at scale). An example could be an analytic model trained with batch machine learning algorithms in a data lake with Spark MLlib or TensorFlow and then deployed into a Kafka Streams or ksqlDB application.
- Replay historical events in cases such as onboarding a new consumer application, error-handling, compliance or regulatory processing, schema changes in an analytics platform. This becomes especially relevant if Tiered Storage is used under the hood of Kafka for cost-efficient and scalable long-term storage.
Analytics example with Confluent Cloud and AWS services
Here is an illustration from an AWS architecture combining Confluent and its ecosystem including connectors, stream processing capabilities, and schema management together with several 1st party AWS cloud services:
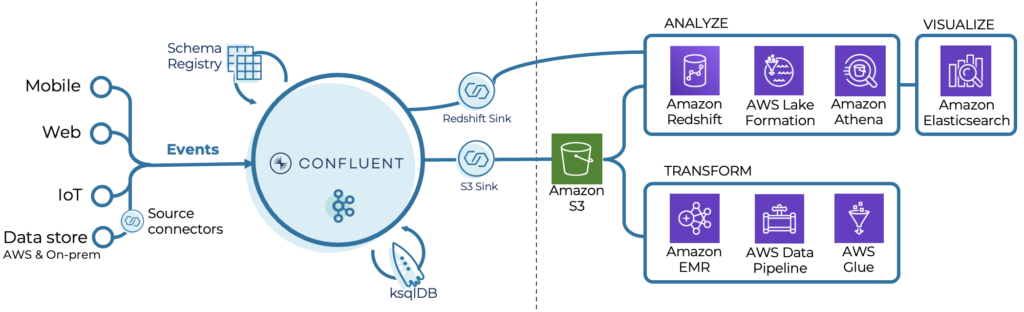
As you can see, Kafka is an excellent tool for analytical workloads. It is not a silver bullet but used for appropriate parts of the overall data management architecture. I have another blog post that explores the relationship between Kafka and other serverless analytics platforms.
However, Kafka is NOT just used for analytical workloads!
Apache Kafka for transactions
Around 60 to 70% of use cases and deployments I see at customers across the globe leverage the Kafka ecosystem for transactional workloads. Enterprises use Kafka for:
- core banking platforms
- fraud detection
- global replication of order and inventory information
- integration with business-critical platforms like CRM, ERP, MES, and many other transactional systems
- supply chain management
- customer communication like point-of-sale integration or context-specific upselling
- and many other use cases where every single event counts.
Kafka is a distributed, fault-tolerant system that is resilient by nature (if you deploy and operate it correctly). No downtime and no data loss can be guaranteed, like in your favorite database, mainframe, or other core platforms.
Elastic scalability and rolling upgrades allow building a flexible and reliable data streaming infrastructure for transactional workloads to guarantee business continuity. The architect can even stretch a cluster across regions to ensure zero data loss and zero downtime even in case of a disaster where a data center is completely down. The post “Global Kafka Deployments” explores the different deployment options and their trade-offs in more detail.
Kafka Transactions API example
And even better: Kafka’s Transaction API, i.e., Exactly-Once Semantics (EOS), has been available since Kafka 0.11 (that GA’ed a long time ago). EOS makes building transactional workloads even easier as you don’t need to handle duplicates anymore.
Kafka now supports atomic writes across multiple partitions through the transactions API. This allows a producer to send a batch of messages to multiple partitions. Either all messages in the batch are eventually visible to any consumer, or none are ever visible to consumers. Here is an example:

Kafka provides a built-in transactions API. And the performance impact (that many people are worried about) is minimal. Here is a simple rule of thumb: If you care about exactly-once semantics, simply activate it! If performance issues force you to disable it, you can still fine-tune your application or disable it. But most projects are fine with the minimal performance trade-offs versus the enormous benefit of handling transactional behavior out-of-the-box.
Nevertheless, to be clear: You don’t need to use Kafka’s Transaction API to build mission-critical, transactional workloads.
SAGA design pattern for transactional data in Kafka without transactions
The Kafka Transactions API is optional. As discussed above, Kafka is resilient without transactions. Though eliminating duplicates is your task then. Exactly-once semantics solve this problem out-of-the-box across all Kafka components. Kafka Connect, Kafka Streams, ksqlDB, and different clients like Java, C++, .NET, Go support EOS.
However, I am also not saying that you should always use the Kafka Transaction API or that it solves every transactional problem. Keep in mind that scalable distributed systems require other design patterns than a traditional “Oracle to IBM MQ transaction”.
Some business transactions span multiple services. Hence, you need a mechanism to implement transactions that span services. A familiar design pattern and implementation for such a transactional workload is the SAGA pattern with a stateful orchestration application.
Swisscom’s Custodigit is an excellent example of such an implementation leveraging Kafka Streams. It is a modern banking platform for digital assets and cryptocurrencies that provides crucial features and guarantees for seriously regulated crypto investments – more details in my blog post about Blockchain, Crypto, NFTs, and Kafka.
And yes, there are always trade-offs between the Kafka Transaction API and exactly-once semantics, stateful orchestration in a separate application, and two-phase-commit transactions like Oracle DB and IBM MQ use it. Choose the right tool to define your appropriate enterprise architecture!
Kafka with other data stores and streaming engines
Most enterprises use Kafka as the central scalable real-time data hub. Hence, use cases include analytical and transactional workloads.
Most Kafka projects I see today also leverage Kafka Connect for data integration, Kafka Streams/ksqlDB for continuous data processing, and Schema Registry for data governance.
Thus, with Kafka, one (distributed and scalable) infrastructure enables messaging, storage, integration, and data processing. But of course, most Kafka clusters connect to other applications (like SAP or Salesforce) and data management systems (like MongoDB, Snowflake, Databricks, et al.) for analytics:
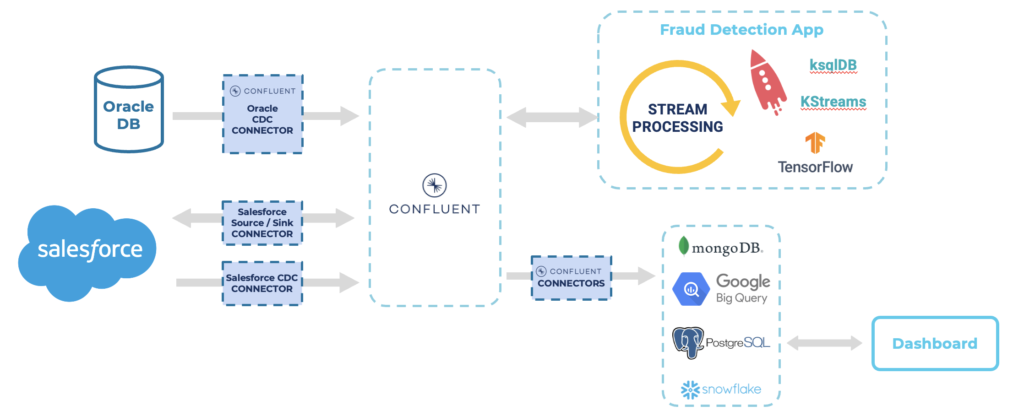
I explored in detail why Kafka is a database for some specific use cases but will NOT replace other databases and data lakes in its own blog post.
In addition to Kafka-native stream processing engines like Kafka Streams or ksqlDB, other streaming analytics frameworks like Apache Flink or Spark Streaming can easily be connected for transactional or analytical workloads. Just keep in mind that especially transactional workloads get harder end-to-end with every additional system and infrastructure you add to the enterprise architecture.
Kappa architecture for analytics AND transactions with Kafka as the data hub
Real-time data beats slow data. That’s true for almost every use case. Yet, enterprise architects build new infrastructures with the Lambda architecture that includes a separate batch layer for analytics and a real-time layer for transactional workloads.
A single real-time pipeline, called Kappa architecture, is the better fit. Real-world examples from companies such as Disney, Shopify, Uber, and Twitter explore the benefits of Kappa but also show how batch processing fits into this discussion positively with no Lambda. In its dedicated post, learn how a Kappa architecture can revolutionize how you built analytical and transactional workloads with the same scalable real-time data hub powered by Kafka.
How do you leverage data streaming for analytical or transactional workloads? Do you use exactly-once semantics to ease the implementation of transactions? Let’s connect on LinkedIn and discuss it! Stay informed about new blog posts by subscribing to my newsletter.





