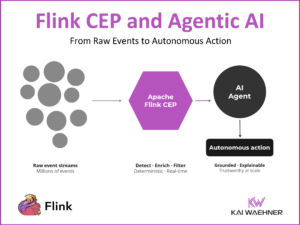
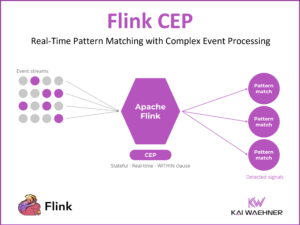
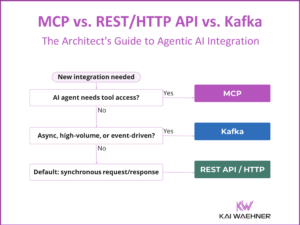
Internet of things, cloud and mobile are the major drivers for stream processing. Use cases are network monitoring, intelligent surveillance, but also less technical things such as inventory management or fraud detection. The book helps a lot to get a basic understanding about history, concepts and patterns of the stream processing paradigm.
“Fundamentals of Stream Processing: Application Design, Systems, and Analytics” (www.amazon.com/Fundamentals-Stream-Processing-Application-Analytics/dp/1107015545) is one of only few books available about stream processing. Published in 2014 by Cambridge University Press. Authors are Henrique C. M. Andrade (JP Morgan, New York), Bugra Gedik (Bilkent University, Turkey), Deepak S. Turaga (IBM Thomas J. Watson Research Center, New York).
Stream Processing
If you are not sure, if stream processing is relevant for you, you should take a look at my slides of a talk I gave at a conference some weeks ago: “Hadoop and Data Warehouse – Friends, Enemies or Profiteers? What about Real Time?” (https://www.kai-waehner.de/blog/2014/05/13/hadoop-and-data-warehouse-dwh-friends-enemies-or-profiteers-what-about-real-time-slides-including-tibco-examples-from-jax-2014-online/). These slides explain why stream processing is required as part of a big data architecture besides a Data Warehouse and Apache Hadoop to be able to realize “fast data” use cases. Actually, stream processing solves the problem of using a “too late architecture”.
Book Content
The book starts with an introduction to stream processing explaining the motivation and need for this paradigm. Part 1 (Fundamentals) contains my favorite chapters of this book as you get a lot of knowledge about stream processing and why different academic and commercial projects and products emerged for stream processing – and how they differ. The end of part 1 gives an overview about academic systems such as TelegraphCQ, STREAM, Aurora and Borealis. Afterwards, commercial systems such as TIBCO BusinessEvents and Oracle CEP are discussed, before switching over to “real” stream processing frameworks and products: IBM InfoSphere Streams and TIBCO StreamBase as proprietary alternatives, and Twitter Storm (now Apache Storm) and Yahoo S4 as open source options.
Part 2 (application development – data flow programming) discusses some basic concepts of stream processing such as flow composition (static, dynamic, nested), flow manipulation (operators, punctuations, windowing), modularity and extensibility. Part 3 discusses the architecture of a stream processing system and its applications. Part 4 goes into more detail discussing design principles and patterns for functional / non-functional topics and data processing / transformation. Part 5 describes three use cases from different verticals (general operations monitoring, healthcare and semiconductor).
Altogether, you get a good overview about the stream processing paradigm, including history, basic concepts, design principles and use cases.
IBM InfoSphere vs. TIBCO StreamBase vs. Apache Storm vs. XYZ
The book has a lot of great content. However, you should be aware that it is focused on IBM InfoSphere Streams (http://www-03.ibm.com/software/products/en/infosphere-streams) and its programming language SPL. All screenshots and code examples (and there are a lot!) use these. That is absolutely legitimate as the authors were involved in creating this product / this language respectively its academic ancestors.
If you want to or have to use another programming language, framework (such as Apache Storm) or product (such as TIBCO StreamBase), you can skip several parts of this book (all code examples; chapter about IBM InfoSphere Streams architecture; implementation of use cases; etc). Also, you should keep this in mind when reading the first part of the book, which compares different products.
Nevertheless, the book is still worthy reading as you learn a lot about stream processing concepts in general.
Criticism
There is only a few things to criticize. What I did not like:
- The book is written in a very academic style. When I wrote my degree dissertation, I had to use the same style. Not suited for a “business book”, in my opinion.
- The price for the book is very high (100 USD / 80 Euro).
- The book has over 500 pages, but a lot of it is source code, which is not needed or read by most readers, probably. If you want to / have to learn IBM InfoSphere Streams, you will probably do a training session with IBM coaches instead of trying to learn with this book (I doubt this would work as this is no training book). On the other side, if you will use another product instead of IBM’s, then you also do not care about the source code.
Off Topic – Which Stream Processing Framework or Product to Choose?
If you want to use a great product, you should try out TIBCO StreamBase (http://www.tibco.com/products/event-processing/complex-event-processing/streambase-complex-event-processing/default.jsp), which has much better and easier tooling than IBM InfoSphere Streams (watch out, I work for TIBCO, so this sentence might also be biased – so try out both, and decide by yourself)! Besides IBM and TIBCO, in my opinion, there are no other good stream processing products on the market at the time of this writing.
There are some nice open source frameworks such as Apache Storm (https://storm.incubator.apache.org/) or Apache Spark (http://spark.apache.org/), which support stream processing, but you will miss good tool support, maturity and commercial support here.
Conclusion
This book is not good for evaluation of different products as it is very IBM-biased. Nevertheless I really enjoyed reading the chapters about history, concepts and design patterns. I learned a lot about stream processing in general. As you do not have many options, if you want to buy a book about stream processing, my recommendation is to buy this one, even if you do not care about IBM’s product, but want to use another one such as TIBCO StreamBase.
Feel free to contact me for any feedback or discussion via Twitter (@KaiWaehner), email (kontakt@kai-waehner.de) or social network (LinkedIn, Xing).
Kai Wähner