
In late April 2026, SAP published an updated API policy with surprisingly little fanfare. Section 2.2.2 of API Policy v4/2026 prohibits the use of SAP APIs for “interaction or integration with (semi-)autonomous or generative AI systems that plan, select, or execute sequences of API calls.” In plain language: no third-party AI agents on your SAP data unless SAP says so.
The community reacted immediately. Consultants called it lock-in. Partners warned about undocumented APIs. CEO Christian Klein walked the message back on the Q1 investor call, clarifying that the intent is to protect SAP’s domain know-how and prevent performance degradation, not to block customers from their own data. The EU Data Act, effective September 2025, anchors customer rights to data they generate in connected systems. SAP acknowledged this. But legal rights and practical access architecture are two different things. A legal right without an integration layer is not operational.
The debate that followed largely missed the more important question underneath it. When your most critical business data lives inside a vendor platform, who controls how AI agents access it? And what happens when those agents start consuming that data at a scale the platform was never designed to handle? That question is not unique to SAP. It is not even new. Enterprises have been navigating versions of it for decades. Agentic AI is now forcing every enterprise to confront it directly.

SAP’s API Policy Does More Than Protect Infrastructure
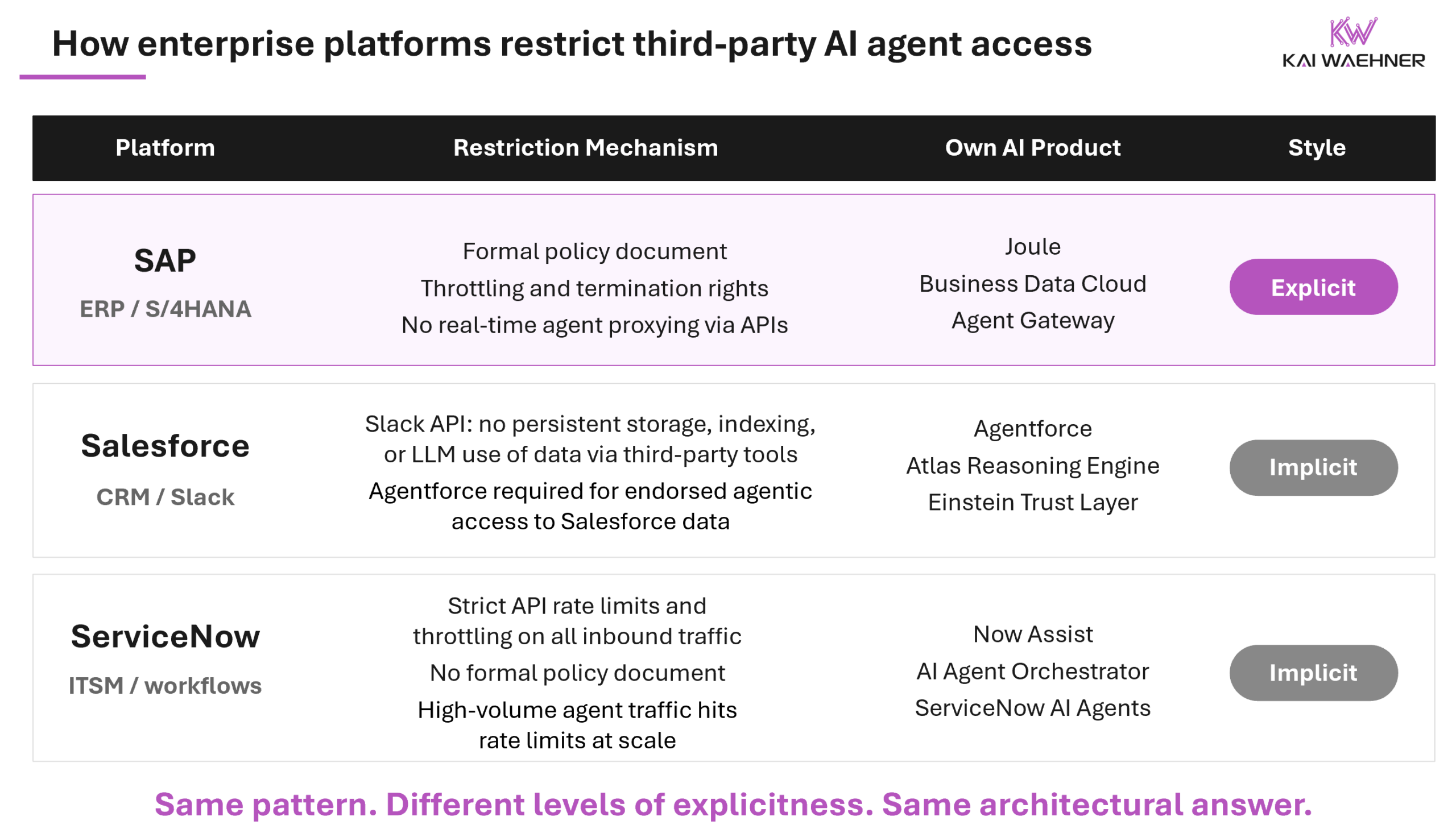
The policy restricts third-party AI agent access to SAP APIs and routes agentic traffic toward SAP’s own endorsed stack: Joule, Business Data Cloud, the Agent Gateway. Third-party AI tools, including Microsoft Copilot, Salesforce Einstein, and a long tail of agentic vendors that have built SAP connectors, now face formal restrictions. SAP’s own AI products do not face those same restrictions.
The infrastructure argument SAP offers is legitimate. SAP was built for mission-critical business transactions. Payroll. Financial close. Supply chain execution. Processes where 85 or 90 percent accuracy is not good enough. Autonomous agents create a fundamentally different load profile than human users. No enterprise wants its ERP destabilized by an agent loop gone wrong.
But the policy creates an asymmetry that goes beyond infrastructure protection. SAP controls which AI systems can access SAP data, and its own products sit on the permitted side of that line. Every enterprise running a third-party agent strategy against SAP data now has a compliance problem that SAP’s own customers using Joule do not have. That asymmetry is commercially convenient for SAP. Enterprises should name it clearly rather than accepting only the stability framing.
Salesforce, ServiceNow, and Others Are Doing the Same Thing, More Quietly
SAP’s policy stands out because it is explicit, legally binding, and published as a formal document. But the underlying dynamic is not unique to SAP.
Salesforce has tightened Slack API access, restricting third-party tools from storing, indexing, or using Slack data to train or fine-tune AI models. That cuts off a critical input stream for AI agents that rely on persistent organizational memory.
Agents built outside Salesforce’s endorsed stack get less context and less capability. The practical effect is a quieter version of what SAP made explicit: third-party agents work, but with structural disadvantages compared to Agentforce.
ServiceNow enforces strict rate limits and throttling on inbound agent traffic at the API layer. As agent volumes scale, those limits become an architectural constraint for any third-party integration, not just a configuration detail.
The pattern is consistent across every major business application platform. These systems were built to run specific business domains at high accuracy. They were not designed to be general-purpose data sources for arbitrary agent consumption. SAP is the most explicit and legally binding in how it has drawn that line. Salesforce and ServiceNow have been more implicit, embedding governance controls without a blanket policy document. The direction of travel is the same across all of them.
This is not a SAP problem. It is an industry-wide structural shift. Enterprises that treat this as a SAP-specific issue will face the same constraint again with every other platform in their stack.
Enterprises Already Solved This. The Pattern Is Older Than SAP.
This problem has a known solution. Enterprises have built it before, across different systems, different eras, and different tooling generations.
The mainframe is the clearest example. No enterprise architect in the 1980s or 1990s connected every downstream application directly to the mainframe. The mainframe ran the core transactions. Everything else consumed from an extracted, staged, distributed copy of that data. Change Data Capture, IBM MQ, and batch extraction pipelines were the standard answer. Protect the core system. Distribute the data. Scale consumption separately.

Apache Kafka became the most widely adopted technology for making that pattern real-time and scalable. But the pattern itself is tool-agnostic. It works with MQ-based middleware, with ETL pipelines, with modern iPaaS platforms, and with event-driven streaming. The production results at large enterprises are well-documented.
Royal Bank of Canada decoupled consumption from the mainframe entirely, enabling real-time analytics across more than 50 applications while cutting infrastructure costs. Citizens Bank reflected 99.99 percent of mainframe changes in cloud applications within four seconds, reducing IT costs by 30 percent. Fidelity Investments ran Kafka Connect directly on z/OS for real-time bidirectional messaging with no network latency overhead. Krungsri cut fraud detection from hours to under 60 seconds by offloading core banking data to a streaming layer instead of querying the source system directly.
The trigger in every case was cost and scale. The solution is the same one SAP customers need now. For the full architecture breakdown, integration patterns, and additional customer stories, my post on Mainframe Integration with Data Streaming: Architecture, Business Value, Real-World Success covers this in depth.
The Integration Pattern Is Universal. The Tooling Is Not.
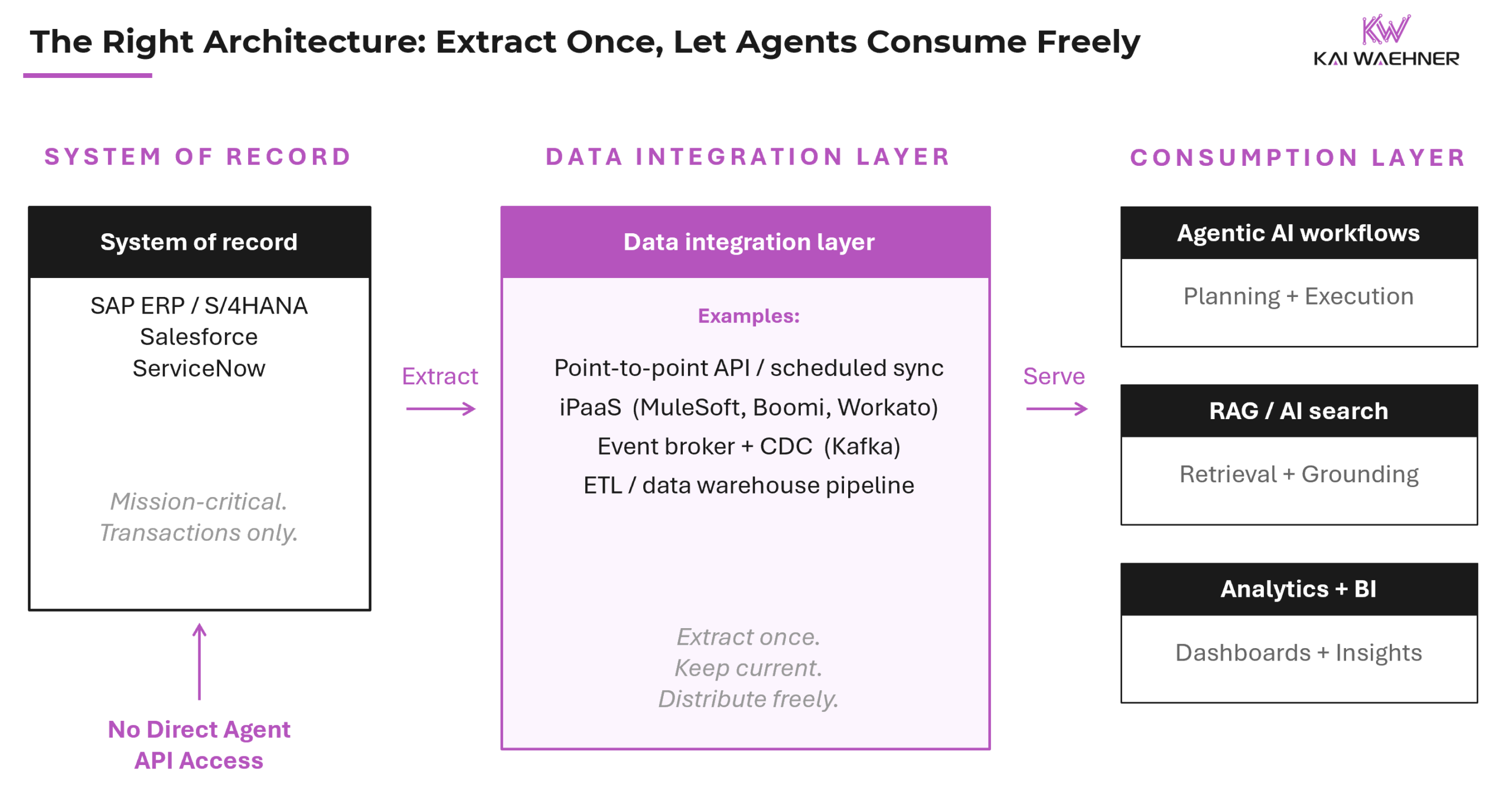
Extract SAP data into a layer you control. Keep it current. Let agents consume from there. That is the principle. What it looks like in practice depends on your situation.
The Spectrum: From Simple API Sync to Real-Time Event Streaming
For small or simple scenarios, a point-to-point API integration between SAP and a downstream data store is often enough. A manufacturer with a single SAP instance and a handful of agents querying product or inventory data can set up a scheduled sync to a local database or cloud store and cover most agent use cases without any streaming infrastructure. Fast to implement, easy to maintain.
For mid-market enterprises, SaaS iPaaS platforms and low-code visual integration tools are the practical answer. Tools like MuleSoft, Boomi, Workato, or Informatica Cloud can connect SAP to a downstream data store, keep data current via API polling or CDC, and do so without a dedicated data engineering team. A competent integration developer can stand up a working pipeline in days.
For large enterprises with high-volume, real-time, multi-system requirements, event-driven streaming with CDC is the architecture of choice. CDC connectors capture changes from SAP in near real-time and stream them to a downstream platform. Agents consume from there. The source system is never directly exposed to agent traffic. This is where Apache Kafka and similar platforms operate at production scale.
In every case, the outcome is the same. SAP stays stable. Agents get the data they need. No policy violation. No performance degradation.
The full vendor and tooling landscape across all of these tiers is the subject of an upcoming Data Integration Landscape post (coming in a few weeks). It will cover the full spectrum of integration patterns, company sizes, and use case complexity for SAP, Salesforce, ServiceNow, and other business application data sources, in the same format as the Data Streaming Landscape and the Agentic AI Landscape published earlier this year.
Large Enterprises Already Run This. The Trigger Was Cost, Not AI.
Many of the enterprises reacting most strongly to SAP’s API policy have been calling SAP APIs directly at scale for years. It was the path of least resistance. It was also already the wrong architecture before agentic AI existed.
SAP licensing and infrastructure costs money. SAP has a long history of enforcing indirect access licensing when third-party systems interact with SAP data in ways that substitute for named user activity. That exposure is not new. Direct agent API calls at scale sharpen it significantly. Every agent query that hits SAP directly is a potential indirect access event. Offloading was already the right answer for cost and licensing reasons alone, years before the first AI agent touched SAP data.
Large enterprises that built proper data integration layers years ago are largely insulated from this debate. They already extract SAP data into downstream platforms. Their agents consume from those platforms. The policy changes very little for them in practice. The urgency is real for everyone else.
SAP’s AI Policy Is a Real Constraint. The Missing Architecture Is the Bigger Problem.
The concern about SAP lock-in through endorsed architectures is legitimate and should be named clearly. Restricting third-party AI agent access while steering customers toward Joule, Business Data Cloud, and the Agent Gateway is a commercially motivated move. The DSAG user group has formally flagged the contradiction between the policy and SAP’s open platform messaging, and the EU Data Act creates a legal backdrop that will shape how this plays out in European markets.
But none of that changes the architectural reality. The enterprises best positioned to navigate this are the ones that do not depend on direct API access to systems of record in the first place.
Build the integration layer. Extract the data. Let agents consume from a stable, governed, downstream source. That is not a workaround for SAP’s policy. It is the architecture that should have been there regardless.
Stop arguing about the gate. Build the infrastructure that makes it irrelevant.
Stay informed about the latest thinking on real-time data integration, process intelligence, and trusted agentic AI by subscribing to my newsletter and following me on LinkedIn or X. And download my free book, The Ultimate Data Streaming Guide, a practical resource covering data streaming use cases, architectures, and real-world industry case studies.
