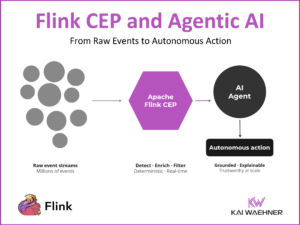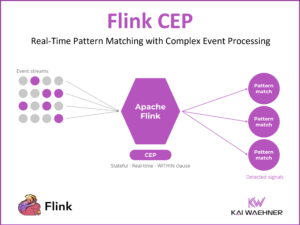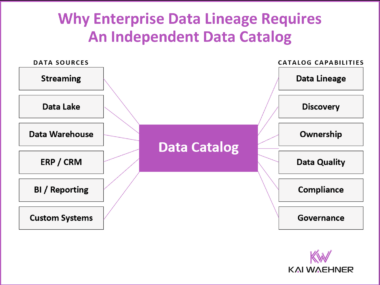
Beyond Enterprise Data Lineage: The Case for a Platform-Independent Data Catalog
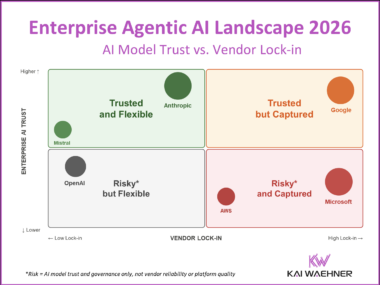
Most organizations start their data governance journey by asking how to track where data comes from and where it goes. They quickly discover a harder question: why can none of their existing tools answer that across all systems? Vendor-specific lineage tools like Confluent, Snowflake Horizon, and Databricks Unity Catalog each do a good job within their platform boundary. The problem is the boundary. Enterprise-wide lineage requires a platform-independent catalog layer that integrates everything and is owned by none of the platforms it connects.