Can and should Apache Kafka replace a database? How long can and should I store data in Kafka? How can I query and process data in Kafka? These are common questions that come up more and more. Short answers like “Yes” or “It depends” are not good enough for you? Then this read for you! This blog post explains the idea behind databases and different features like storage, queries and transactions to evaluate when Kafka is a good fit and when it is not.
Jay Kreps, the co-founder of Apache Kafka and Confluent, explained already in 2017 why “It’s okay to store data in Apache Kafka”. However, many things have improved and new components and features were added in the last three years. This update covers the core concepts of Kafka from a database perspective. It includes Kafka-native add-ons like Tiered Storage for long-term cost-efficient storage and ksqlDB as event streaming database. The relation and trade-offs between Kafka and other databases are explored to complement each other instead of thinking about a replacement. This discussion includes different options for pull and push based bi-directional integration.
I also created a slide deck and video recording about this topic.
What is a Database? Oracle? NoSQL? Hadoop?
Let’s think about the term “database” on a very high level. According to Wikipedia,
“A database is an organized collection of data, generally stored and accessed electronically from a computer system.
The database management system (DBMS) is the software that interacts with end users, applications, and the database itself to capture and analyze the data. The DBMS software additionally encompasses the core facilities provided to administer the database. The sum total of the database, the DBMS and the associated applications can be referred to as a “database system”. Often the term “database” is also used to loosely refer to any of the DBMS, the database system or an application associated with the database.
Computer scientists may classify database-management systems according to the database models that they support. Relational databases became dominant in the 1980s. These model data as rows and columns in a series of tables, and the vast majority use SQL for writing and querying data. In the 2000s, non-relational databases became popular, referred to as NoSQL because they use different query languages.”
Based on this definition, we know that there are many databases on the market. Oracle. MySQL. Postgres. Hadoop. MongoDB. Elasticsearch. AWS S3. InfluxDB. Kafka.
Hold on. Kafka? Yes, indeed. Let’s explore this in detail…

Storage, Transactions, Processing and Querying Data
A database infrastructure is used for storage, queries and processing of data, often with specific delivery and durability guarantees (aka transactions).
There is not just one database as we all should know from all the NoSQL and Big Data products on the market. For each use case, you (should) choose the right database. It depends on your requirements. How long to store data? What structure should the data have? Do you need complex queries or just retrieval of data via key and value? Require ACID transactions, exactly-once semantics, or “just” at least once delivery guarantees?
These and many more questions have to be answered before you decide if you need a relational database like MySQL or Postgres, a big data batch platform like Hadoop, a document store like MongoDB, a key-value store like RocksDB, a time series database like InfluxDB, an in-memory cache like Memcached, or something else.
Every database has different characteristics. Thus, when you ask yourself if you can replace a database with Kafka, which database and what requirements are you talking about?
What is Apache Kafka?
Obviously, it is also crucial to understand what Kafka is to decide if Kafka can replace your database. Otherwise, it is really hard to proceed with this evaluation… 🙂
Kafka is an Event Streaming Platform => Messaging! Stream Processing! Database! Integration!
First of all, Kafka is NOT just a pub/sub messaging system to send data from A to B. This is what some unaware people typically respond to such a question when they think Kafka is the next IBM MQ or RabbitMQ. Nope. Kafka is NOT a messaging system. A comparison with other messaging solutions is an apple to orange comparison (but still valid to decide when to choose Kafka or a messaging system).
Kafka is an event streaming platform. Companies from various industries presented hundred of use cases where they use Kafka successfully for much more than just messaging. Just check out all the talks from the Kafka Summits (including free slide decks and video recordings).
One of the main reasons why Apache Kafka became the de facto standard for so many different use cases is its combination of four powerful concepts:
- Publish and subscribe to streams of events, similar to a message queue or enterprise messaging system
- Store streams of events in a fault-tolerant storage as long as you want (hours, days, months, forever)
- Process streams of events in real time, as they occur
- Integration of different sources and sinks (no matter if real time, batch or request-response)
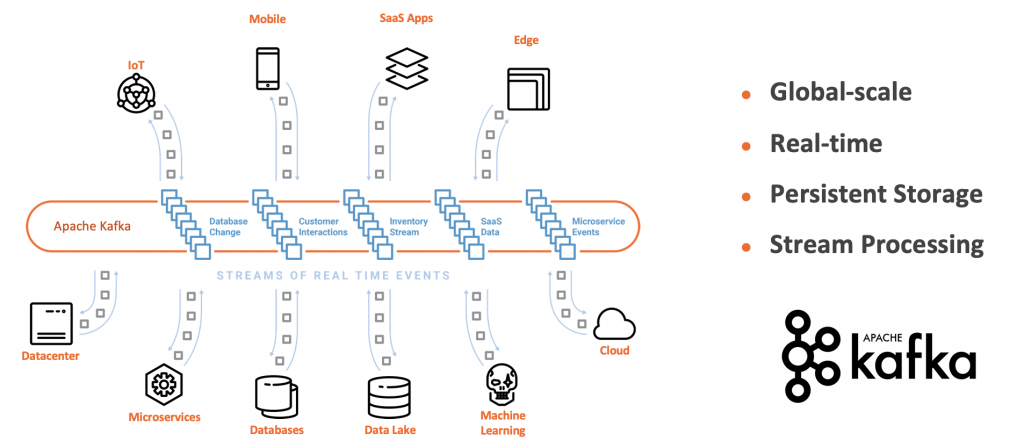
Decoupled, Scalable, Highly Available Streaming Microservices
With these four pillars built into one distributed event streaming platform, you can decouple various applications (i.e., producers and consumers) in a reliable, scalable, and fault-tolerant way.
As you can see, storage is one of the key principles of Kafka. Therefore, depending on your requirements and definition, Kafka can be used as a database.
Is “Kafka Core” a Database with ACID Guarantees?
I won’t cover the whole discussion about how “Kafka Core” (meaning Kafka brokers and its concepts like distributed commit log, replication, partitions, guaranteed ordering, etc.) fits into the ACID (Atomicity, Consistency, Isolation, Durability) transaction properties of databases. This was discussed already by Martin Kleppmann at Kafka Summit San Francisco 2018 (“Is Kafka a Database?”) and a little bit less technically by Tim Berglund (“Dissolving the Problem – Making an ACID-Compliant Database Out of Apache Kafka”).
TL;DR: Kafka is a database and provides ACID guarantees. However, it works differently than other databases. Kafka is also not replacing other databases; but a complementary tool in your toolset.
The Client Side of Kafka
In messaging systems, the client API provides producers and consumers to send and read messages. All other logic is implemented using low level programming or additional frameworks.
In databases, the client API provides a query language to create data structures and enables the client to store and retrieve data. All other logic is implemented using low level programming or additional frameworks.
In an event streaming platform, the client API is used for sending and consuming data like in a messaging system. However, in contrary to messaging and databases, the client API provides much more functionality.
Independent, scalable, reliable components applications can be built with the Kafka APIs. Therefore, a Kafka client application is a distributed system that queries, processes and stores continuous streams of data. Many applications can be built without the need for another additional framework.
The Kafka Ecosystem – Kafka Streams, ksqlDB, Spring Kafka, and Much More…
The Kafka ecosystem provides various different components to implement applications.
Kafka itself includes a Java and Scala client API, Kafka Streams for stream processing with Java, and Kafka Connect to integrate with different sources and sinks without coding.
Many additional Kafka-native client APIs and frameworks exist. Here are some examples:
- librdkafka: A C library implementation of the Apache Kafka protocol, providing Producer, Consumer and Admin clients. It was designed with message delivery reliability and high performance in mind, current figures exceed 1 million msgs/second for the producer and 3 million msgs/second for the consumer. In addition to the C library, it is often used as wrapper to provide Kafka clients from other programming languages such as C++, Golang, Python and JavaScript.
- REST Proxy: Provides a RESTful interface to a Kafka cluster. It makes it easy to produce and consume messages, view the state of the cluster, and perform administrative actions without using the native Kafka protocol or clients.
- ksqlDB: An event streaming database for Apache Kafka that enables you to build event streaming applications leveraging your familiarity with relational databases.
- Spring for Kafka: Applies core Spring concepts to the development of Kafka-based messaging and streaming solutions. It provides a “template” as a high-level abstraction for sending messages. Includes first-class support for Kafka Streams. Additional Spring frameworks like Spring Cloud Stream and Spring Cloud Data Flow also provide native support for event streaming with Kafka.
- Faust: A library for building streaming applications in Python, similar to the original Kafka Streams library (but more limited functionality and less mature).
- TensorFlow I/O + Kafka Plugin: A native integration into TensorFlow for streaming machine learning (i.e. directly consuming models from Kafka for model training and model scoring instead of using another data lake).
- Many more…
Domain-Driven Design (DDD), Dumb Pipes, Smart Endpoints
The importance of Kafka’s client side is crucial for the discussion of potentially replacing a database because Kafka applications can be stateless or stateful; the latter keeping state in the application instead of using an external database. The storage section below contains more details about how the client application can store data long term and is highly available.
With this, you understand that Kafka has a powerful server and a powerful client side. Many people are not aware of this when they evaluate Kafka versus other messaging solutions or storage systems.
This in conjunction with the capability to do real decoupling between producer and consumers leveraging the underlying storage of Kafka, it becomes clear why Apache Kafka became the de facto standard and backbone for microservice architectures – not just replacing other traditional middleware but also building the client applications using Domain Driven Design (DDD) for decoupled applications, dumb pipes and smart endpoints:
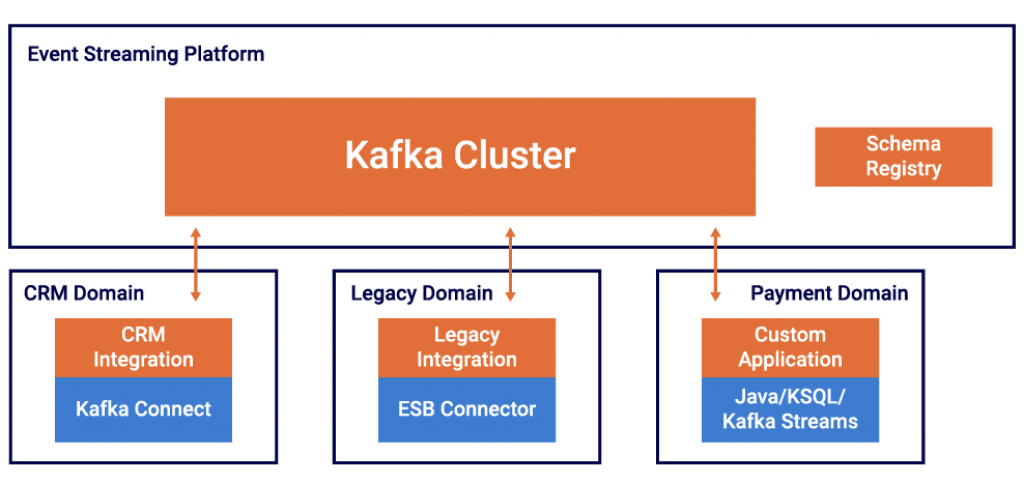
Check out the blog post “Microservices, Apache Kafka, and Domain-Driven Design (DDD)” for more details on this discussion.
Again, why is this important for the discussion around Kafka being a database: For every new microservice you create, you should ask yourself: Do I really need a “real database” backend in my microservice? With all its complexity and cost regarding development, testing, operations, monitoring?
Often, the answer is yes, of course. But I see more and more applications where keeping the state directly in the Kafka application is better, easier or both.
Storage – How long can you store Data in Kafka? And what is the Database under the Hood?
The short answer: Data can be stored in Kafka as long as you want. Kafka even provides the option to use a retention time of -1. This means “forever”.
The longer answer is much more complex. You need to think about the cost and scalability of the Kafka brokers. Should you use HDDs or SDDs? Or maybe even Flash based technology? Pure Storage wrote a nice example leveraging flash storage to write 5 million messages per second with three producers and 3x replication. It depends on how much data you need to store and how fast you need to access data and be able to recover from failures..
Publishing with Apache Kafka at The New York Times is a famous example for storing data in Kafka forever. Kafka is used for storing all the articles ever published by The New York Times and replacing their API-based approach. The Streams API is used to feed published content in real-time to the various applications and systems that make it available to our readers.
Another great example is the Account Activity Replay API from Twitter: It uses Kafka as Storage to provide “a data recovery tool that lets developers retrieve events from as far back as five days. This API recovers events that weren’t delivered for various reasons, including inadvertent server outages during real-time delivery attempts.”
Until now we are just talking about the most commonly used Kafka features: Log-based storage with retention time and disks attached to the broker. However, you also need to consider the additional capabilities of Kafka to have a complete discussion about long-term storage in a Kafka infrastructure: Compacted topics, tiered storage and client-side storage. All of these features can quickly change your mind of how you think about Kafka, its use cases and its architecture.
Compacted Topics – Log Compaction and “Event Updates”
Log compaction ensures that Kafka will always retain at least the last known value for each message key within the log of data for a single topic partition. It addresses use cases and scenarios such as restoring state after application crashes or system failure or reloading caches after application restarts during operational maintenance. Therefore, log compaction does not have a retention time.
Obviously, the big trade-off is that log compaction does not keep all events and the full order of changes. For this, you need to use the normal Kafka Topics with a specific retention time.
Or you can use -1 to store all data forever. The big trade-offs here are high cost for the disks and more complex operations and scalability.
Tiered Storage – Long-Term Storage in Apache Kafka
KIP 405 (Kafka Improvement Proposal) was created to standardize the interface for Tiered Storage in Kafka to provide different implementations by different contributors and vendors. The KIP is not implemented yet and the interface is still under discussion by contributors from different companies.
Confluent already provides a (commercial) implementation for Kafka to use Tiered Storage for storing data long term in Kafka at low cost. The blog post “Infinite Storage in Confluent Platform” talks about the motivation and implementation of this game-changing Kafka add-on.
Tiered Storage for Kafka reduces cost (due to cheaper object storage), increases scalability (due to the separation between storage and processing), and eases operations (due to simplified and much faster rebalancing).
Here are some examples for storing the complete log in Kafka long-term (instead of leveraging compacted topics):
- New Consumer, e.g. a complete new microservices or a replacement of an existing application
- Error-Handling, e.g. re-processing of data in case of error to fix errors and process events again
- Compliance / Regulatory Processing: Reprocessing of already processed data for legal reasons; could be very old data (e.g. pharma: 10 years old)
- Query and Analysis of Existing Events; No need for another data store / data lake; ksqlDB (position first, but know the various limitations); Kafka-native analytics tool (e.g. Rockset with Kafka connector and full SQL support for Tableau et al)
- Machine Learning and Model Training: Consume events for model training with a) different one machine learning framework and different hyperparameters or b) different Machine Learning frameworks
The last example is discussed in more detail here: Streaming Machine Learning with Tiered Storage (no need for a Data Lake).
Client-Side Database – Stateful Kafka Client Applications and Microservices
As discussed above, Kafka is not just the server side. You build highly available and scalable real time applications on the Kafka client side.
RocksDB for Stateful Kafka Applications
Often, these Kafka client applications (have to) keep important state. Kafka Streams and ksqlDB leverage RocksDB for this (you could also just use in-memory storage or replace RocksDB with another storage; I have never seen the latter option in the real world, though). RocksDB is a key-value store for running mission-critical workloads. It is optimized for fast, low latency storage.
In Kafka Streams applications, that solves the problem of abstracting access to local stable storage instead of using an external database. Using an external database would require external communication / RPC every time an event is processed. A clear anti-pattern in event streaming architectures.
RocksDB allows software engineers to focus their energies on the design and implementation of other areas of their systems with the peace of mind of relying on RocksDB for access to stable storage. It is battle-tested at several silicon valley companies and used under the hood of many famous databases like Apache Cassandra, CockroachDB or MySQL (MyRocks). RocksDB Is Eating the Database World covers the history and use cases in more detail.
ksqlDB as Event Streaming Database
Kafka Streams and ksqlDB – the event streaming database for Kafka – allow building stateful streaming applications; including powerful concepts like joins, sliding windows and interactive queries of the state. The following example shows how you build a stateful payment application:
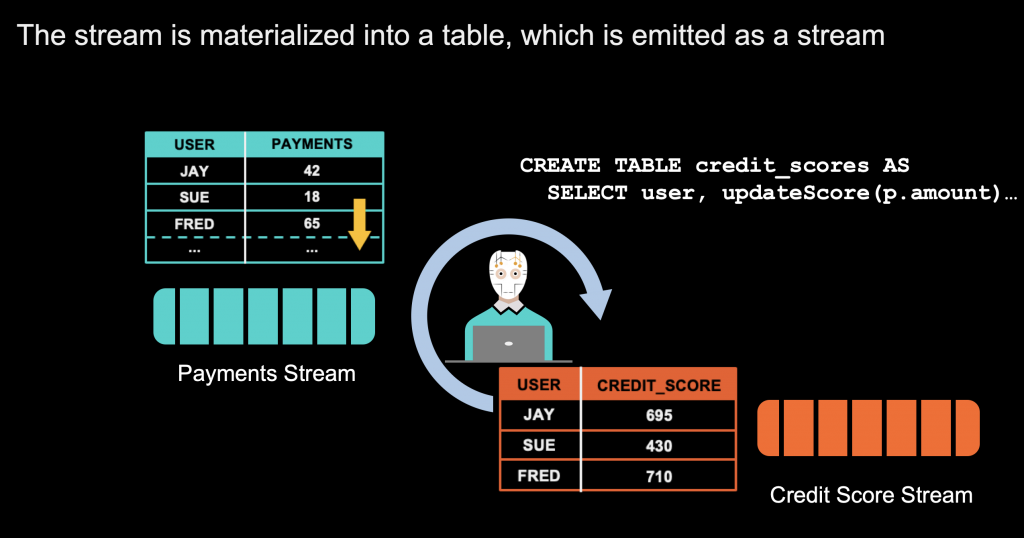
The client application keeps the data in its own application for real time joins and other data correlations. It combines the concepts of a STREAM (unchangeable event) and a TABLE (updated information like in a relational database). Keep in mind that this application is highly scalable. It is typically not just a single instance. Instead, it is a distributed cluster of client instances to provide high availability and parallelizing data processing. Even if something goes down (VM, container, disk, network), the overall system will not lose and data and continue running 24/7.
As you can see, many questions have to be answered and various features have to be considered to make the right decision about how long and where you want to store data in Kafka.
One good reason to store data long-term in Kafka is to be able to use the data at a later point in time for processing, correlations or analytics.
Query and Processing – Can you Consume and Analyze the Kafka Storage?
Kafka provides different options to consume and query data.
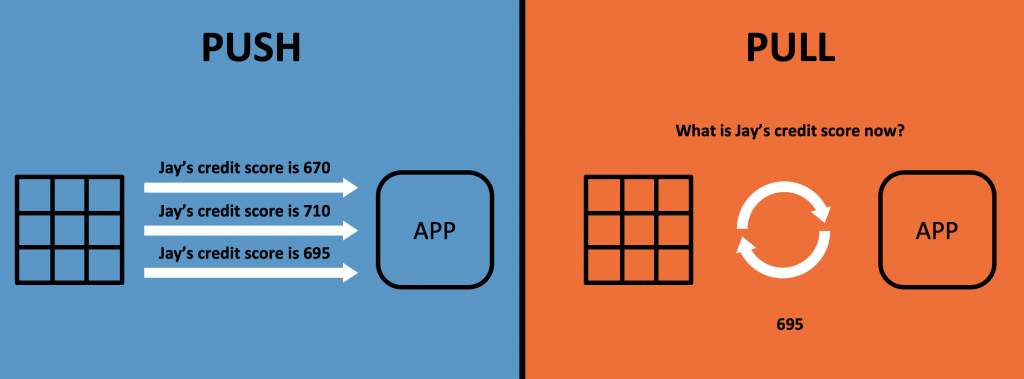
Queries in Kafka can be either PUSH (i.e. continuously process and forward events) or PULL (i.e. the client requests events like you know it from your favorite SQL database).
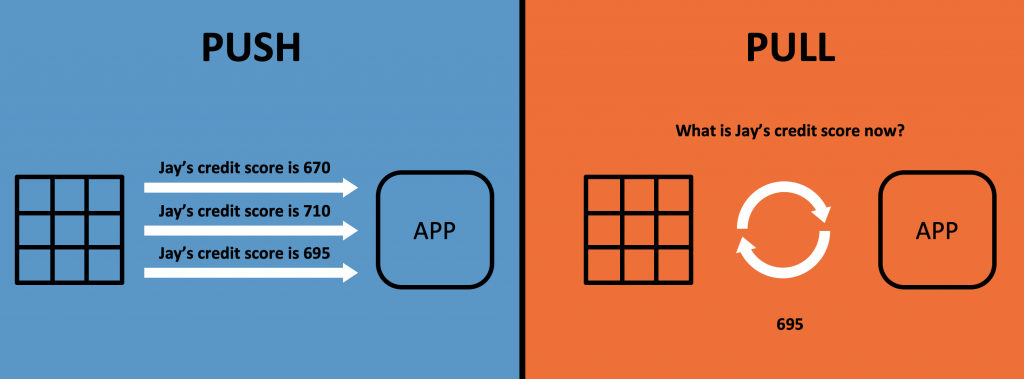
I will show you different options in the following sections.
Consumer Applications Pull Events
Kafka clients pull the data from the brokers. This decouples producers, brokers and consumers and makes the infrastructure scalable and reliable.
Kafka itself includes a Java and Scala client to consume data. However, Kafka clients are available for almost any other programming language, including widespread languages like C, C++, Python, JavaScript or Golang and exotic languages like RUST. Check out Yeva Byzek’s examples to see your favorite programming language in action. Additionally, Confluent provides a REST Proxy. This allows consumption of events via HTTP(S) from any language or tool supporting this standard.
Applications have different options to consume events from the Kafka broker:
- Continuous consumption of the latest events (in real time or batch)
- Just specific time frames or partitions
- All data from the beginning
Stream Processing Applications / Microservices Pull and Push Events
Kafka Streams and ksqlDB pull events from the brokers, process the data and then push the result back into another Kafka topic. These queries are running continuously. Powerful queries are possible; including JOINs and stateful aggregations.
These features are used for streaming ETL and real time analytics at scale, but also to build mission-critical business applications and microservices.
This discussion needs much more detail and cannot be covered in this blog post focusing on the database perspective. Get started e.g. with my intro to event streaming with ksqlDB from Big Data Spain in Madrid covering use cases and more technical details. “Confluent Developer” is another great point for getting started with building event streaming applications. The site provides plenty of tutorials, videos, demos, and more around Apache Kafka.
The feature “interactive queries” allows querying values from the client applications’ state store (typically implemented with RocksDB under the hood). The events are pulled via technologies like REST / HTTP or pushed via intermediaries like a WebSockets proxy. Kafka Streams provides the core functionality. The interactive query interface has to be implemented by yourself on top. Pro: Flexibility. Con: Not provided out-of-the-box.
Kafka as Query Engine and its Limitations
None of the above described Kafka query capabilities are as powerful as your beloved Oracle database or Elasticsearch!
Therefore, Kafka will not replace other databases. It is complementary. The main idea behind Kafka is to continuously process streaming data; with additional options to query stored data.
Kafka is good enough as database for some use cases. However, the query capabilities of Kafka are not good enough for some other use cases.
Kafka is then often used as central streaming platform where one or more databases (and other applications) build their own materialized real time view leveraging their own technology.
The principle is often called „turning the database inside out“. This design pattern allows using the right database for the right problem. Kafka is used in these scenarios
- as scalable event streaming platform for data integration
- for decoupling between different producers and consumers
- to handle backpressure
- to continuously process and correlate incoming events
- for enabling the creation and updating of materialized views within other databases
- to allow interactive queries directly to Kafka (depending on the use case and used technology)
Kafka as Single Source of Truth and Leading System?
For many scenarios, it is great if the central event streaming platform is the central single source of truth. Kafka provides an event-based real time infrastructure that is scalable and decouples all the producers and consumers. However, in the real world, something like an ERP system will often stay the leading system even it pushes the data via Kafka to the rest of the enterprise.
That’s totally fine! Kafka being the central streaming platform does not force you to make it the leading system for every event. For some applications and databases, the existing source of truth is still the source of truth after the integration with Kafka.
The key point here is that your single source of truth should not be a database that stores the data at rest, e.g. in a data lake like Hadoop or AWS S3. This way your central storage is a slow batch system. You cannot simply connect a real time consumer to it. On the other side, if an event streaming platform is your central layer, then you can ingest it into your data lake for data processing at rest, but you can also easily add another real time consumer.
Native ANSI SQL Query Layer to Pull Events? Tableau, Qlik, Power BI et al to analyze Kafka?
Access to massive volumes of event streaming data through Kafka has sparked a strong interest in interactive, real-time dashboards and analytics, with the idea being similar to what was built on top of traditional databases like Oracle or MySQL using Tableau, Qlik, or Power BI and batch frameworks like Hadoop using Impala, Presto, or BigQuery: The user wants to ask questions and get answers quickly.
Leveraging Rockset, a scalable SQL search and analytics engine based on RocksDB, and in conjunction with BI and analytics tools like Tableau, you can directly query the Kafka log. With ANSI SQL. No limitations. At scale. In real time. This is a good time to question your data lake strategy, isn’t it? 🙂
Check out details about the technical implementation and use cases here: “Real-Time Analytics and Monitoring Dashboards with Apache Kafka and Rockset“. Bosch Power Tools is a great real world example for using Kafka as long-term storage and Rockset for real time analytics and powerful interactive queries.
Transactions – Delivery and Processing Guarantees in Kafka
TL;DR: Kafka provides end-to-end processing guarantees, durability and high availability to build the most critical business applications. I have seen many mission-critical infrastructures built on Kafka in various industries, including banking, telco, insurance, retailing, automotive and many others.
I want to focus on delivery guarantees and correctness as critical characteristics of messaging systems and databases. Transactions are required in many applications to guarantee no data loss and deterministic behavior.
Transaction processing in databases is information processing that is divided into individual, indivisible operations called transactions. Each transaction must succeed or fail as a complete unit; it can never be only partially complete. Many databases with transactional capabilities (including Two-Phase-Commit / XA Transactions) do not scale well and are hard to operate.
Therefore, many distributed systems provide just “at least once semantics”.
Exactly-Once Semantics (EOS) in Kafka
In the contrary, Kafka is a distributed system that provides various guarantee deliveries. Different configuration options allow at-least-once, at-most-once and exactly-once semantics (EOS).
Exactly-once semantics is what people compare to database transactions. The idea is similar: You need to guarantee that each produced information is consumed and processed exactly once. Many people argued that this is not possible to implement with Kafka because individual, indivisible operations can fail in a distributed system! In the Kafka world, many people referred to the famous Hacker News discussion “You Cannot Have Exactly-Once Delivery” and similar Twitter conversations.
In mid of 2017, the “unbelievable thing” happened: Apache Kafka 0.11 added support for Exactly-Once Semantics (EOS). Note that it does not include the term “transaction” intentionally. Because it is not a transaction. Because a transaction is not possible in a distributed system. However, the result is the same: Each consumer consumes each produced message exactly once. “Exactly-once Semantics are Possible: Here’s How Kafka Does it” covers the details of the implementation. In short, EOS includes three features:
- Idempotence: Exactly-once in order semantics per partition
- Transactions: Atomic writes across multiple partitions
- Exactly-once stream processing in Apache Kafka
Matthias J. Sax did a great job explaining EOS at Kafka Summit 2018 in London. Slides and video recording are available for free.
EOS works differently than transactions in databases but provides the same result in the end. It can be turned on by configuration. By the way: The performance penalty compared to at-least-once semantics is not big. Typically something between 10 and 25% slower end-to-end processing.
Exactly-Once Semantics in the Kafka Ecosystem (Kafka Connect, Kafka Streams, ksqlDB, non-Java Clients)
EOS is not just part of Kafka core and the related Java / Scala client. Most Kafka components support exactly-once delivery guarantees, including:
- Some (but not all) Kafka Connect connectors. For example AWS S3 and Elasticsearch.
- Kafka Streams and ksqlDB to process data exactly once for streaming ETL or in business applications.
- Non-Java clients. librdkafka – the core foundation of many Kafka clients in various programming languages – added support for EOS recently.
Will Kafka Replace your existing Database?
In general, no! But you should always ask yourself: Do you need another data store in addition to Kafka? Sometimes yes, sometimes no. We discussed the characteristics of a database and when Kafka is sufficient.
Each database has specific features, guarantees and query options. Use MongoDB as document store, Elasticsearch for text search, Oracle or MySQL for traditional relational use cases, or Hadoop for a big data lake to run map/reduce jobs for reports.
This blog post hopefully helps you make the right decision for your next project.
However, hold on: The question is not always “Kafka vs database XYZ”. Often, Kafka and databases are complementary! Let’s discuss this in the following section…
Kafka Connect – Integration between Kafka and other Databases
Apache Kafka includes Kafka Connect: A framework for connecting Kafka with external systems such as databases, key-value stores, search indexes, and file systems. Using Kafka Connect you can use existing connector implementations for common data sources and sinks to move data into and out of Kafka:
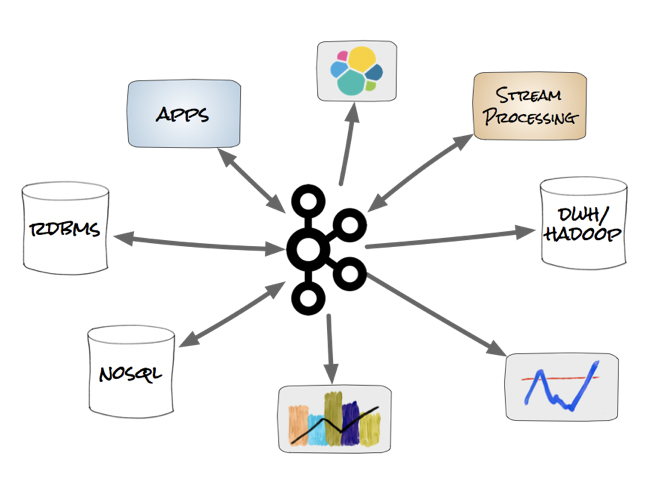
This includes many connectors to various databases. To query data from a source system, event can either be pulled (e.g. with the JDBC Connector) or pushed via Chance-Data-Capture (CDC, e.g. with the Debezium Connector). Kafka Connect can also write into any sink data storage, including various relational, NoSQL and big data infrastructures like Oracle, MongoDB, Hadoop HDFS or AWS S3.
Confluent Hub is a great resource to find the available source and sink connectors for Kafka Connect. The hub includes open source connectors and commercial offerings from different vendors. To learn more about Kafka Connect, you might want to check out Robin Moffat’s blog posts. He has implemented and explained tens of fantastic examples leveraging Kafka Connect to integrate with many different source and sink databases.
Apache Kafka is a Database with ACID Guarantees, but Complementary to other Databases!
Apache Kafka is a database. It provides ACID guarantees and is used in hundreds of companies for mission-critical deployments. However, in many cases Kafka is not competitive to other databases. Kafka is an event streaming platform for messaging, storage, processing and integration at scale in real time with zero downtime and zero data loss.
With these characteristics, Kafka is often used as central streaming integration layer. Materialized views can be built by other databases for their specific use cases like real time time series analytics, near real time ingestion into a text search infrastructure, or long term storage in a data lake.
In summary, if you get asked if Kafka can replace a database, then here are different answers:
- Kafka can store data forever in a durable and high available manner providing ACID guarantees
- Different options to query historical data are available in Kafka
- Kafka-native add-ons like ksqlDB or Tiered Storage make Kafka more powerful than ever before for data processing and event-based long-term storage
- Stateful applications can be built leveraging Kafka clients (microservices, business applications) without the need for another external database
- Not a replacement for existing databases like MySQL, MongoDB, Elasticsearch or Hadoop
- Other databases and Kafka complement each other; the right solution has to be selected for a problem; often purpose-built materialized views are created and updated in real time from the central event-based infrastructure
- Different options are available for bi-directional pull and push based integration between Kafka and databases to complement each other
Please let me know what you think and connect on LinkedIn… Stay informed about new blog posts by subscribing to my newsletter.





