
This blog post discusses the concepts, use cases, and architectures behind Event Streaming, Apache Kafka, Distributed Ledger (DLT), and Blockchain. A comparison of different technologies such as Confluent, AIBlockchain, Hyperledger, Ethereum, Ripple, IOTA, and Libra explores when to use Kafka, a Kafka-native blockchain, a dedicated blockchain, or Kafka in conjunction with another blockchain.

Use Cases for Secure and Tamper-Proof Data Processing with a Blockchain
Blockchain is a hype topic for many years. While many companies talk about the buzzword, it is tough to find use cases where Blockchain is the best solution. The following examples show the potential of Blockchain. Here it might make sense:
- Supply Chain Management (SCM): Manufacturing, transportation, logistics, and retailing see various use cases, including transaction settlement, tracking social responsibility, accurate cost information, precise shipping, and logistics data, automated purchasing and planning using integrated ERP and CRM systems, enforcement of partner contracts, food safety.
- Healthcare: Management of patient data (especially access control), management and use of academic research data, prevention of compliance violations, reducing human errors, cross-cutting up-to-date patient information, secure identity management.
- Telecom Industry: Blockchain solution for the settlement of roaming discount agreements to transact seamlessly with an ecosystem of partners and to reach significant growth of operators’ business relationships and business models.
- Financial Services: Instant global payments with cryptocurrencies (including a digital US Dollar or EURO), reduced cost for end-users, audit transparency, data provenance, data lineage, fraud reduction, savings on business operations/finance reporting/compliance.
These are great, valid use cases. But you should ask yourself some critical questions:
Do you need a blockchain? What parts of “blockchain” do you need? Tamper-proof storage and encrypted data processing? Consortium deployments with access from various organizations? Does it add business value? Is it worth the added efforts, complexity, cost, risk?
Challenges and Concerns of Blockchain Technologies
Why am I so skeptical about Blockchain? I love the concepts and technologies! But I see the following concerns and challenges in the real world:
- Technical complexity: Blockchain technology is still very immature, and the efforts to implement a blockchain project are massive and often underestimated
- Organizational complexity: Deploying a blockchain over multiple organizations requires enormous efforts, including compliance and legal concepts.
- Transaction speed: Bitcoin is slow. But also, most other blockchain frameworks are not built for millions of messages. Some solutions are in the works to improve from hundreds to thousands of messages per second. This scale is still not good enough for financial trading, supply chain, Internet of Things, and many other use cases.
- Energy consumption: Bitcoin and some other cryptocurrencies use ‘Proof-of-Work‘ (POW) as a consensus mechanism. The resources used for Bitcoin mining is crazy. Period! (this issue is typically only relevant in public blockchains; private blockchains use other concepts for this reason)
- Security: Providing a tamper-proof deployment is crucial. Deploying this over different organizations (permissioned / consortium blockchain) or public (permissionless) is hard. Security is much more than just a feature or API.
- Data tenancy: Data privacy, compliance (across countries), and ownership of the data (who is allowed to use it for creating added value) are hard to define.
- Lifecycle costs: Blockchain infrastructure is complex. It is not just an application but a cross-company distributed infrastructure. Development, operations, and management and are very different from hosting your monolith or microservices.
Hence, it is important to only choose a blockchain technology when it makes sense. Most projects I have seen in the last years were about evaluating technologies and doing technical POCs. Similar to Hadoop data lakes 5-10 years ago. I fear the same result as in the Hadoop era: The technical proof worked out, but no real business value or enormous additional and unnecessary complexity and cost were added.
Distributed Ledger and Blockchain Technologies
It is crucial to understand that people often don’t mean ‘Blockchain’ when they say ‘Blockchain’. What they actually mean is ‘Distributed Ledger Technology’ (DLT). What is the relation between Blockchain and DLT?
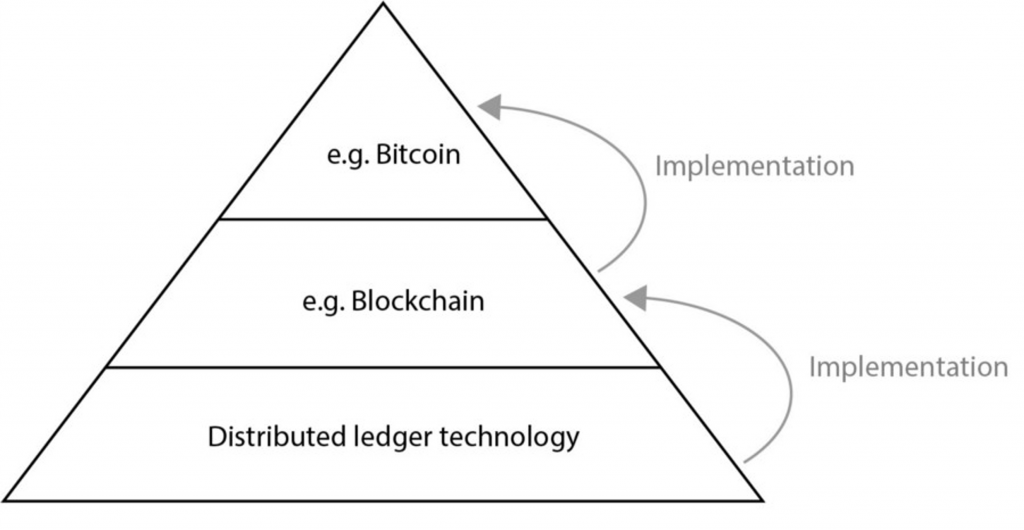
Blockchain: A Catchall Phrase for Distributed Ledger Technology (DLT)
The following explores Blockchain and DLT in more detail:
Distributed Ledger Technology (DLT):
- Decentralized database
- Managed by various participants. No central authority acts as an arbitrator or monitor
- Distributed log of records, greater transparency
- Fraud and manipulation more difficult, more complicated to hack the system
Blockchain:
- Blockchain is nothing else but a DLT with a specific set of features
- Shared database – a log of records – but in this case, shared using blocks that form a chain
- Blocks are closed by a type of cryptographic signature called a ‘hash’; the next block begins with that same ‘hash’, a kind of wax seal
- Hashing verifies that the encrypted information has not been manipulated and that it can’t be manipulated
Blockchain Concepts
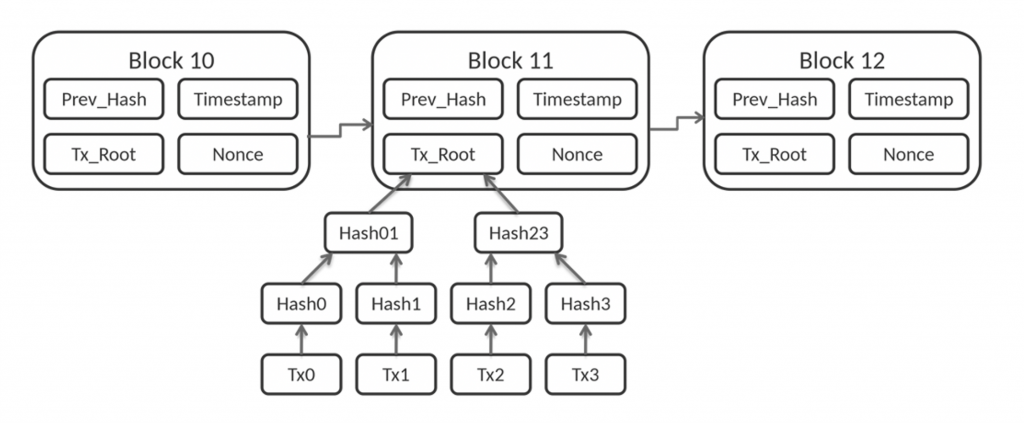
A blockchain is either permissionless (i.e., public and accessible by everyone, like Bitcoin) or permissioned (using a group of companies or consortium).
Different consensus algorithms exist, including Proof-of-Work (POW), Proof-of-Stake (POS), or voting systems.
Blockchain uses global consensus across all nodes. In contrary, DLT can build the consensus without having to validate across the entire Blockchain
A Blockchain is a growing list of records, called blocks, linked using cryptography. Each block contains a cryptographic hash of the previous block, a timestamp, and transaction data.
Blockchain is a catchall phrase in most of the success stories I have seen in the last years. Many articles you read on the internet say ‘Blockchain’, but the underlying implementation is a DLT. Be aware of this when evaluating these technologies to find the best solution for your project.
The Relation between Kafka and Blockchain
Now you have a good understanding of use cases and concepts of Blockchains and DLTs.
How blockchain and DLT this related to event streaming and the Apache Kafka ecosystem?
I will not give an introduction to Apache Kafka here. Just mentioning a few reasons why Event Streaming with Apache Kafka is used for various use cases in any industry today:
- Real-time
- Scalable
- High throughput
- Cost reduction
- 24/7 – zero downtime, zero data loss
- Decoupling – storage, domain-driven design (DDD)
- Data (re-)processing and stateful client applications
- Integration – connectivity to IoT, legacy, big data, everything
- Hybrid architecture – On-premises, multi-cloud, edge computing
- Fully managed cloud
- No vendor locking
Single Kafka clusters can even be deployed over multiple regions and globally. Mission-critical deployments without downtime or data loss are crucial for Blockchain and many other use cases. ‘Architecture patterns for distributed, hybrid, edge, and global Apache Kafka deployments‘ explores these topics in detail. High availability is the critical foundation for thinking about using Kafka in the context of blockchain projects!
Kafka is NOT a Blockchain!
Kafka is not a blockchain. But it provides many characteristics required for real-world “enterprise blockchain” projects:
- Real-Time
- High Throughput
- Decentralized database
- Distributed log of records
- Immutable log
- Replication
- High availability
- Decoupling of applications/clients
- Role-based access control to data
Three essential requirements are missing in Kafka for “real blockchain projects”:
- Tamper-Proof
- Encrypted payloads
- Deployment over various independent organizations
These missing pieces are crucial for implementing a blockchain. Having said this, do you need all of them? Or just some of them? Evaluating this question clarifies if you should choose just Kafka, Kafka as native blockchain implementation, or Kafka in conjunction with a blockchain technology like Hyperledger or Ethereum.
Kafka in conjunction with Blockchain – Use Cases and Architectures
I wrote about “Blockchain – The Next Big Thing for Middleware” on InfoQ a long time ago in 2016 already. There is a need to integrate Blockchain and the rest of the enterprise.
Interestingly, many projects from that time don’t exist anymore today, for instance, Microsoft’s Project Bletchley initiative on Github to integrate blockchains with the rest of the enterprise is dead. A lot of traditional middleware (MQ, ETL, ESB) is considered legacy and replaced by Kafka at enterprises across the globe.
Today, blockchain projects use Kafka in two different ways. Either you connect Kafka to one or more blockchains, or you implement a Kafka-native blockchain:
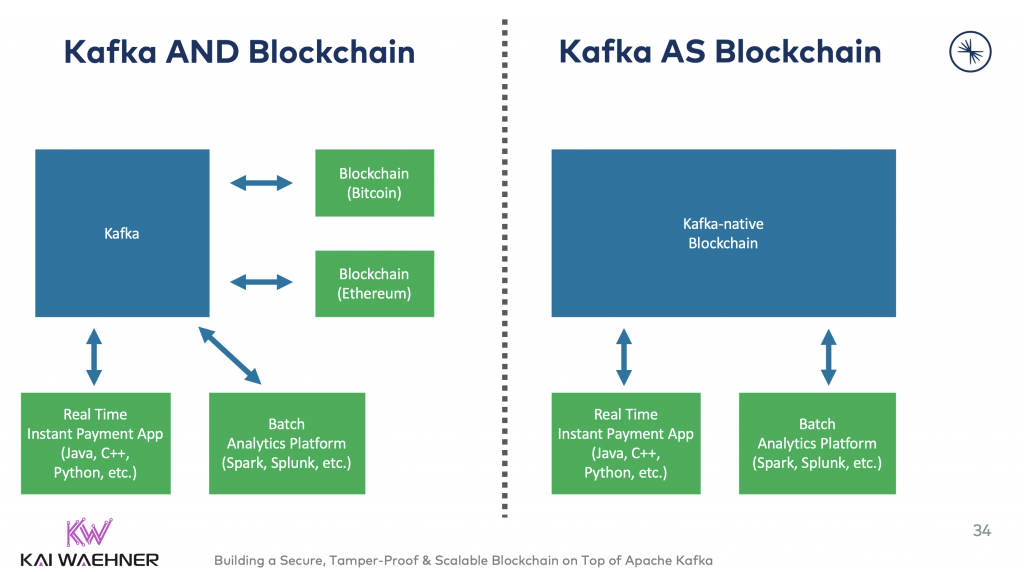
Let’s take a look at a few different examples for Kafka in conjunction with blockchain solutions.
Kafka AND Blockchains – A Financial Services Platform
Nash is an excellent example of a modern trading platform for cryptocurrencies using Blockchain under the hood. The heart of Nash’s platform leverages Apache Kafka. The following quote from their community page says:
“Nash is using Confluent Cloud, google cloud platform to deliver and manage its services. Kubernetes and apache Kafka technologies will help it scale faster, maintain top-notch records, give real-time services which are even hard to imagine today.”
Nash provides the speed and convenience of traditional exchanges and the security of non-custodial approaches. Customers can invest in, make payments with, and trade Bitcoin, Ethereum, NEO, and other digital assets. The exchange is the first of its kind, offering non-custodial cross-chain trading with the full power of a real order book. The distributed, immutable commit log of Kafka enables deterministic replayability in its exact order at any time.
Kafka-Native Blockchain – A Tamper-Proof Blockchain implemented with Kafka
Kafka can be combined with blockchains, as described above. Another option is to use or build a Kafka-native blockchain infrastructure. High scalability and high volume data processing in real-time for mission-critical deployments is a crucial differentiator of using Kafka compared to “traditional blockchain deployments” like Bitcoin or Ethereum.
Kafka enables a blockchain for real-time processing and analysis of historical data with one single platform:
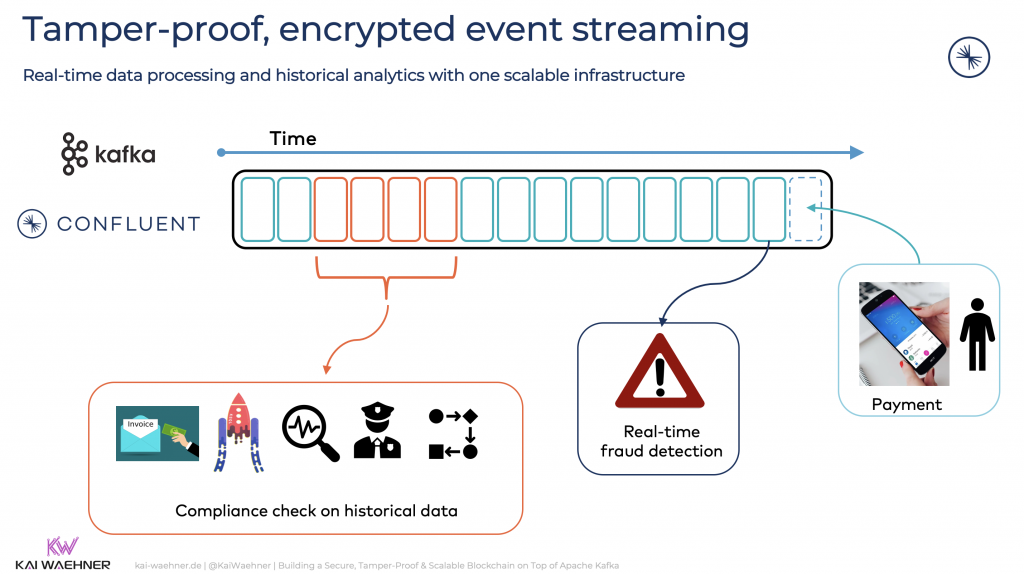
The following sections describe two examples of Kafka-native blockchain solutions:
- Hyperledger Fabric: A complex, powerful framework used for deployment over various independent organizations
- AIBlockchain: A flexible and straightforward approach to building a blockchain infrastructure within the enterprise
Hyperledger Fabric leveraging Apache Kafka under the Hood for Transaction Ordering
Hyperledger Fabric is a great (but also very complex) blockchain solution using Kafka under the hood.
Ordering in Hyperledger Fabric is what you might know from other blockchains as a ‘consensus algorithm’. It guarantees the integrity of transactions:
Hyperledger Fabric provides three ordering mechanisms for transactions: SOLO, Apache Kafka, and Simplified Byzantine Fault Tolerance (SBFT). Hyperledger Fabric and Apache Kafka share many characteristics. Hence, this combination is a natural fit. Choosing Kafka for the transaction ordering enables a fault-tolerant, highly scalable, and performant infrastructure.
AIBlockchain – A Tamper-proof Kafka-native Blockchain Implementation
AIBlockchain has implemented and patented a Kafka-native blockchain.
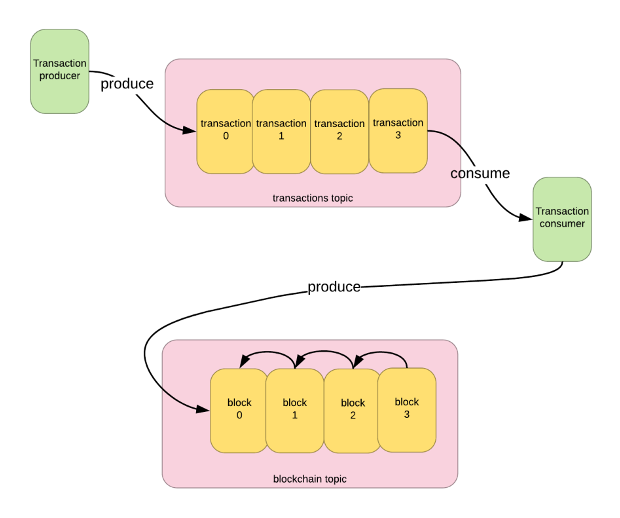
The project KafkaBlockchain is available on Github. It provides a Java library for tamper-evidence using Kafka. Messages are optionally encrypted and hashed sequentially. The library methods are called within a Kafka application’s message producer code to wrap messages and called within the application’s consumer code to unwrap messages.
Because blockchains must be strictly sequentially ordered, Kafka blockchain topics must either have a single partition, or consumers for each partition must cooperate to sequence the records:
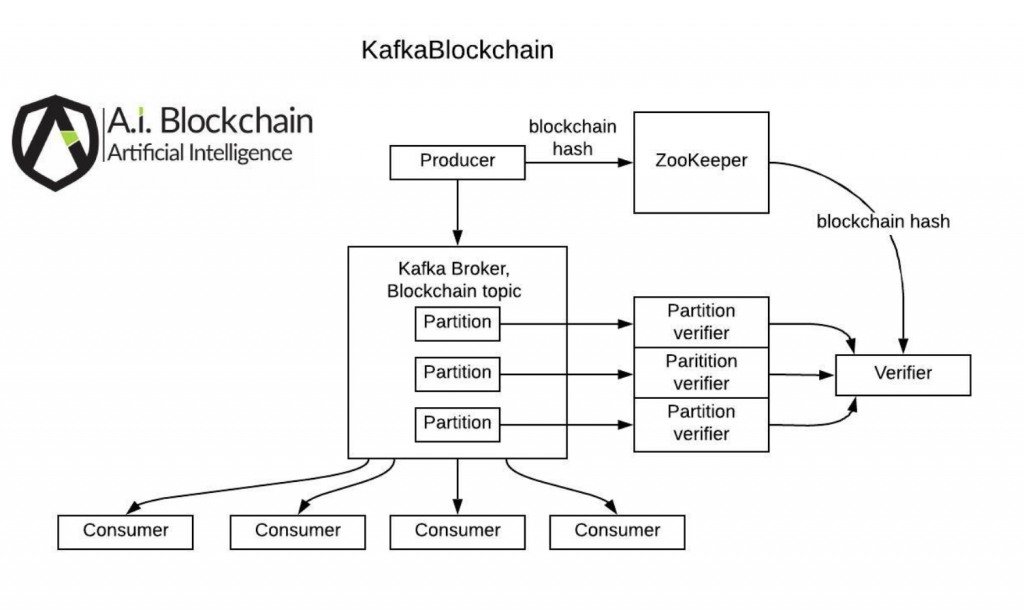
Kafka already implements checksums for message streams to detect data loss. However, an attacker can provide false records that have correct checksums. Cryptographic hashes such as the standard SHA-256 algorithm are very difficult to falsify, which makes them ideal for tamper-evidence despite being a bit more computation than checksums:
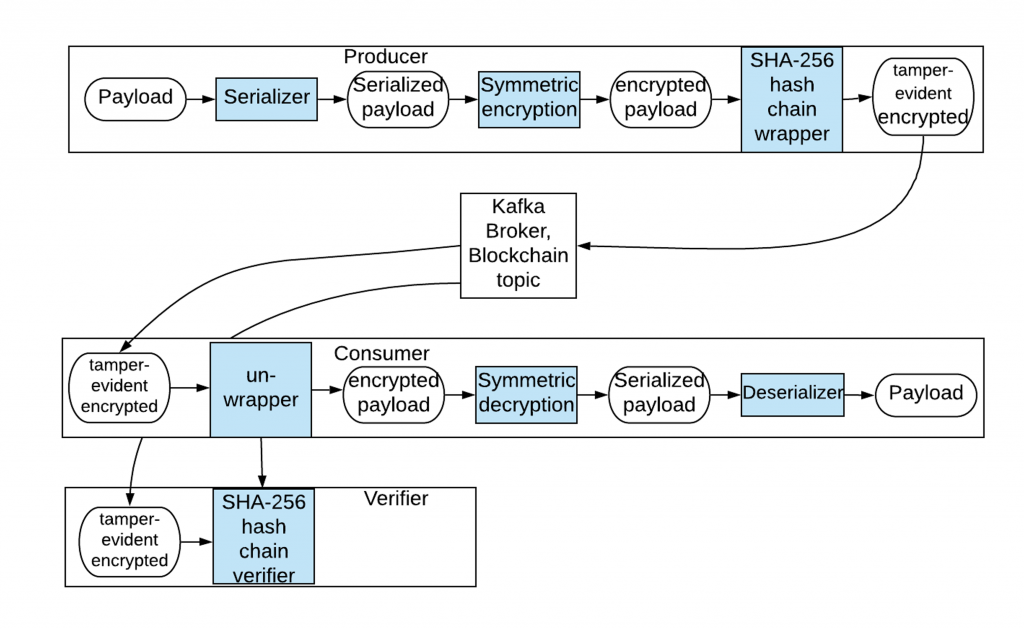
The provided sample in the Github project stores the first (genesis) message SHA-256 hash for each blockchain topic in ZooKeeper. In production, secret-keeping facilities such as Vault can be used.
Please contact the AIBlockchain team for more information about the open-source KafkaBlockchain library, their blockchain patent, and the blockchain projects at customers. The on-demand webinar discussed below also covers this in much more detail.
When to Choose Kafka and/or Blockchain?
Price vs. value is the fundamental question to answer when deciding if you should choose a blockchain technology.

If you consider blockchain / DLT, it is pretty straightforward to make a comparison and make the right choice:
Use a Kafka-native blockchain such as AIBlockchain for
- Enterprise infrastructure
- Open, scalable, real-time requirements
- Flexible architectures for many use cases
Use a real blockchain / DLTs like Hyperledger, Ethereum, Ripple, Libra, IOTA, et al. for
- Deployment over various independent organizations (where participants verify the distributed ledger contents themselves)
- Specific use cases
- Server-side managed and controlled by multiple organizations
- Scenarios where the business value overturns the added complexity and project risk
Use Kafka and Blockchain together to combine the benefits of both for
- Integration between blockchain / DLT technologies and the rest of the enterprise, including CRM, big data analytics, and any other custom business applications
- Reliable data processing at scale in real-time with Kafka for internal use cases
- Blockchain for secure communication over various independent organizations
Use only Kafka if you don’t need a blockchain! This is probably true for 95+% of use cases! Period!
Infinite Long-Term Storage in Apache Kafka with Tiered Storage
Today, Kafka works well for recent events, short-horizon storage, and manual data balancing. Kafka’s present-day design offers extraordinarily low messaging latency by storing topic data on fast disks that are collocated with brokers. This concept of combining memory and storage is usually good. But sometimes, you need to store a vast amount of data for a long time.
Blockchain is such a use case!
Therefore let’s talk about long-term storage in Kafka leveraging Tiered Storage.
Confluent Tiered Storage for Kafka
(Disclaimer: The following was written in July 2020 – at a later time, make sure to check the status of Tiered Storage for Kafka as it is expected to evolve soon)
“KIP-405 – Add Tiered Storage support to Kafka” is in the works of implementing Tiered Storage for Kafka. Confluent is actively working on this with the open-source community. Uber is leading this initiative.
Confluent Tiered Storage is already available today in Confluent Platform and used under the hood in Confluent Cloud:
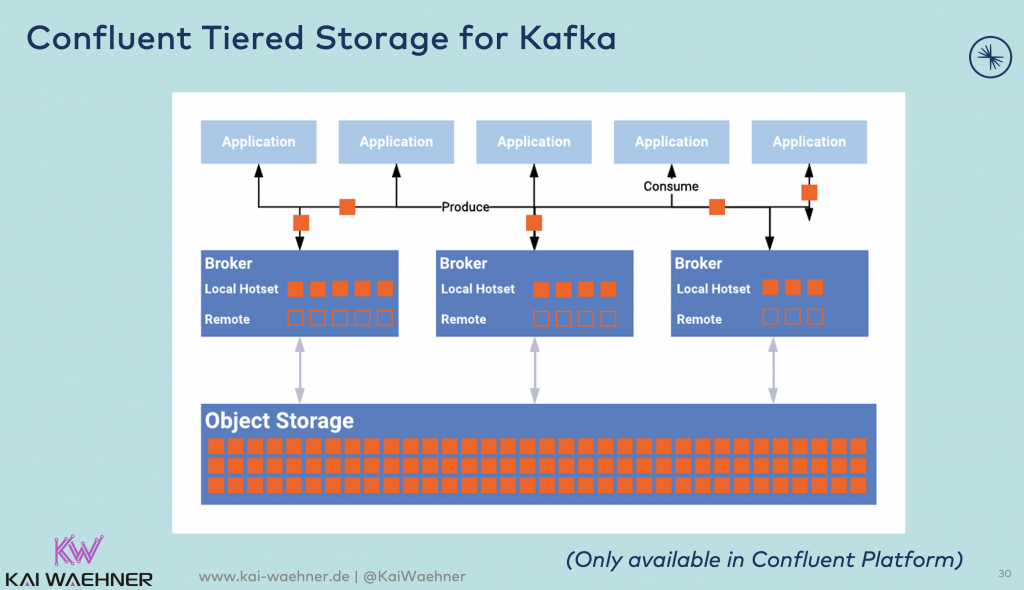
Read about the details and motivation here. Tiered Storage for Kafka creates many benefits:
- Use Cases for Reprocessing Historical Data: New consumer application, error-handling, compliance / regulatory processing, query and analyze existing events, model training using Machine Learning / Deep Learning frameworks like TensorFlow.
- Store Data Forever in Kafka: Older data is offloaded to inexpensive object storage, permitting it to be consumed at any time. Using AiB, storage can be made tamper-proof and immutable.
- Save $$$: Storage limitations, like capacity and duration, are effectively uncapped leveraging cheap object stores like S3, GCS, MinIO or PureStorage.
- Instantaneously scale up and down: Your Kafka clusters will be able to automatically self-balance load and hence elastically scale.
A Blockchain needs to store infinite data forever. Event-based with timestamps, encrypted, and tamper-proof. AiB’s tamper-proof Blockchain with KafkaBlockchain is a great example that could leverage Tiered Storage for Kafka.
Slides and Video: Kafka + Blockchain
I discussed this topic in more detail with Confluent’s partner AIBlockchain.
Check out the slide deck:
https://www.slideshare.net/KaiWaehner/apache-kafka-and-blockchain-comparison-and-a-kafkanative-implementation
Here is the on-demand video recording:

As you learned in this post, Kafka is used in various blockchain scenarios; either complementary to integrate with blockchains / distributed ledger technology and the rest of the enterprise, or Kafka-native implementation.
What are your experiences with blockchain infrastructures? Does Blockchain add value? Is this worth the added technical and organizational complexity? Did you or do you plan to use Apache Kafka and its ecosystem? What is your strategy? Let’s connect on LinkedIn and discuss it!
