Recognizing and handling errors is essential for any reliable data streaming pipeline. This blog post explores best practices for implementing error handling using a Dead Letter Queue in Apache Kafka infrastructure. The options include a custom implementation, Kafka Streams, Kafka Connect, the Spring framework, and the Parallel Consumer. Real-world case studies show how Uber, CrowdStrike, Santander Bank, and Robinhood build reliable real-time error handling at an extreme scale.

Apache Kafka became the favorite integration middleware for many enterprise architectures. Even for a cloud-first strategy, enterprises leverage data streaming with Kafka as a cloud-native integration platform as a service (iPaaS).
Message Queue Patterns in Data Streaming with Apache Kafka
Before I go into this post, I want to make you aware that this content is part of a blog series about “JMS, Message Queues, and Apache Kafka”:
- 10 Comparison Criteria for JMS Message Broker vs. Apache Kafka Data Streaming
- THIS POST – Alternatives for Error Handling via a Dead Letter Queue (DLQ) in Apache Kafka
- Implementing the Request-Reply Pattern with Apache Kafka
- UPCOMING – A Decision Tree for Choosing the Right Messaging System (JMS vs. Apache Kafka)
- UPCOMING – From JMS Message Broker to Apache Kafka: Integration, Migration, and/or Replacement
I will link the other posts here as soon as they are available. Please follow my newsletter to get updated in real-time abo t new posts. (no spam or ads)
What is the Dead Letter Queue Integration Pattern (in Apache Kafka)?
The Dead Letter Queue (DLQ) is a service implementation within a messaging system or data streaming platform to store messages that are not processed successfully. Instead of passively dumping the message, the system moves it to a Dead Letter Queue.
The Enterprise Integration Patterns (EIP) call the design pattern Dead Letter Channel instead. We can use both as synonyms.
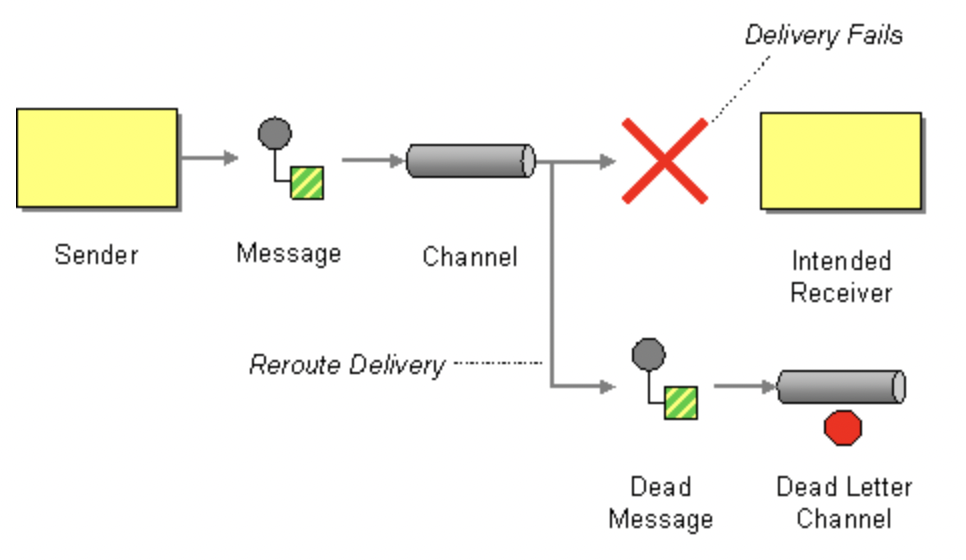
This article focuses on the data streaming platform Apache Kafka. The main reason for putting a message into a DLQ in Kafka is usually a bad message format or invalid/missing message content. For instance, an application error occurs if a value is expected to be an Integer, but the producer sends a String. In more dynamic environments, a “Topic does not exist” exception might be another error why the message cannot be delivered.
Therefore, as so often, don’t use the knowledge from your existing middleware experience. Message Queue middleware, such as JMS-compliant IBM MQ, TIBCO EMS, or RabbitMQ, works differently than a distributed commit log like Kafka. A DLQ in a message queue is used in message queuing systems for many other reasons that do not map one-to-one to Kafka. For instance, the message in an MQ system expires because of per-message TTL (time to live).
Hence, the main reason for putting messages into a DLQ in Kafka is a bad message format or invalid/missing message content.
Alternatives for a Dead Letter Queue in Apache Kafka
A Dead Letter Queue in Kafka is one or more Kafka topics that receive and store messages that could not be processed in another streaming pipeline because of an error. This concept allows continuing the message stream with the following incoming messages without stopping the workflow due to the error of the invalid message.
The Kafka Broker is Dumb – Smart Endpoints provide the Error Handling
The Kafka architecture does not support DLQ within the broker. Intentionally, Kafka was built on the same principles as modern microservices using the ‘dumb pipes and smart endpoints‘ principle. That’s why Kafka scales so well compared to traditional message brokers. Filtering and error handling happen in the client applications.
The true decoupling of the data streaming platform enables a much more clean domain-driven design. Each microservice or application implements its logic with its own choice of technology, communication paradigm, and error handling.
In traditional middleware and message queues, the broker provides this logic. The consequence is worse scalability and less flexibility in the domains, as only the middleware team can implement integration logic.
Custom Implementation of a Kafka Dead Letter Queue in any Programming Language
A Dead Letter Queue in Kafka is independent of the framework you use. Some components provide out-of-the-box features for error handling and Dead Letter Queues. However, it is also easy to write your Dead Letter Queue logic for Kafka applications in any programming language like Java, Go, C++, Python, etc.
The source code for a Dead Letter Queue implementation contains a try-cath block to handle expected or unexpected exceptions. The message is processed if no error occurs. Send the message to a dedicated DLQ Kafka topic if any exception occurs.
The failure cause should be added to the header of the Kafka message. The key and value should not be changed so that future re-processing and failure analysis of historical events are straightforward.
Out-of-the-box Kafka Implementations for a Dead Letter Queue
You don’t always need to implement your Dead Letter Queue. Many components and frameworks provide their DLQ implementation already.
With your own applications, you can usually control errors or fix code when there are errors. However, integration with 3rd party applications does not necessarily allow you to deal with errors that may be introduced across the integration barrier. Therefore, DLQ becomes more important and is included as part of some frameworks.
Built-in Dead Letter Queue in Kafka Connect
Kafka Connect is the integration framework of Kafka. It is included in the open-source Kafka download. No additional dependencies are needed (besides the connectors themselves that you deploy into the Connect cluster).
By default, the Kafka Connect task stops if an error occurs because of consuming an invalid message (like when the wrong JSON converter is used instead of the correct AVRO converter). Dropping invalid messages is another option. The latter tolerates errors.
The configuration of the DLQ in Kafka Connect is straightforward. Just set the values for the two configuration options ‘errors.tolerance’ and ‘errors.deadletterqueue.topic.name’ to the right values:
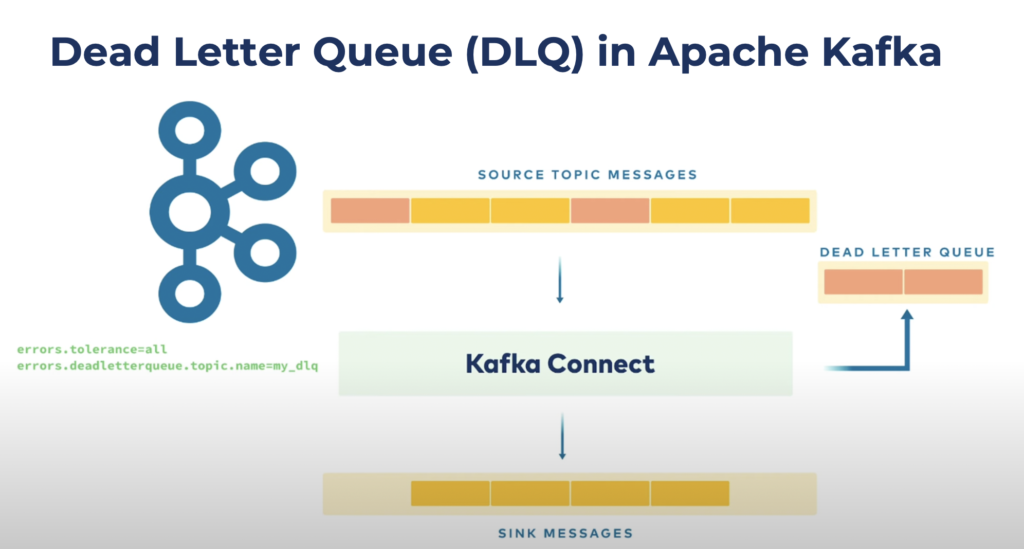
The blog post ‘Kafka Connect Deep Dive – Error Handling and Dead Letter Queues‘ shows a detailed hands-on code example for using DLQs.
Kafka Connect can even be used to process the error message in the DLQ. Just deploy another connector that consumes from t e DLQ topic. For instance, if your application processes Avro messages and an incoming message is in JSON format. A connector then consumes the JSON message and transforms it into an AVRO message to be re-processed successfully:
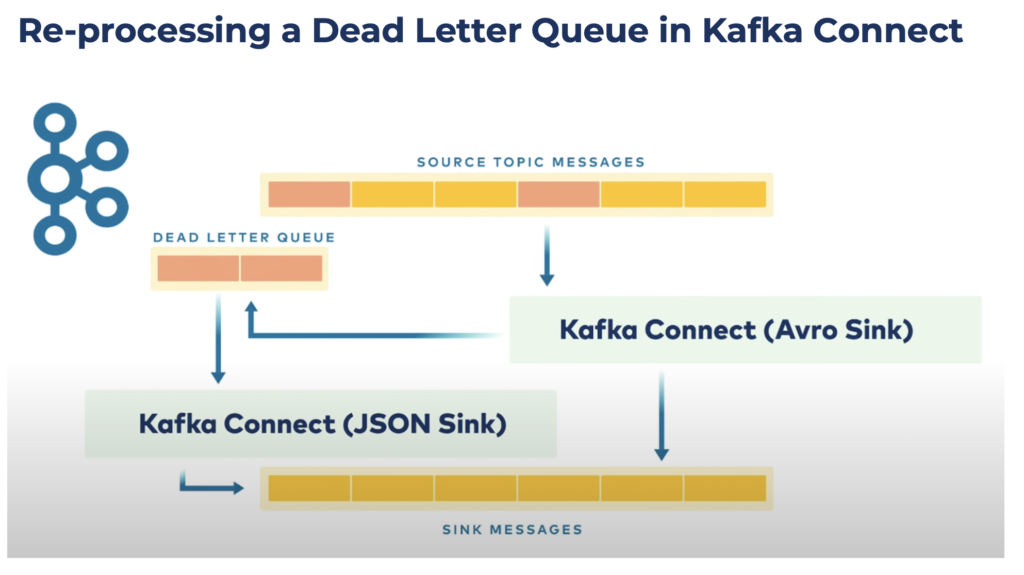
Note that Kafka Connect has no Dead Letter Queue for source connectors.
Error Handling in a Kafka Streams Application
Kafka Streams is the stream processing library of Kafka. It is comparable to other streaming frameworks, such as Apache Flink, Storm, Beam, and similar tools. However, it is Kafka-native. This means you build the complete end-to-end data streaming within a single scalable and reliable infrastructure.
If you use Java, respectively, the JVM ecosystem, to build Kafka applications, the recommendation is almost always to use Kafka Streams instead of the standard Java client for Kafka. Why?
- Kafka Streams is “just” a wrapper around the regular Java producer and consumer API, plus plenty of additional features built-in.
- Both are just a library (JAR file) embedded into your Java application.
- Both are part of the open-source Kafka download – no additional dependencies or license changes.
- Many problems are already solved out-of-the-box to build mature stream processing services (streaming functions, stateful embedded storage, sliding windows, interactive queries, error handling, and much more).
One of the built-in functions of Kafka Streams is the default deserialization exception handler. It allows you to manage record exceptions that fail to deserialize. Corrupt data, incorrect serialization logic, or unhandled record types can cause the error. The feature is not called Dead Letter Queue but solves the same problem out-of-the-box.
Error Handling with Spring Kafka and Spring Cloud Stream
The Spring framework has excellent support for Apache Kafka. It provides many templates to avoid writing boilerplate code by yourself. Spring-Kafka and Spring Cloud Stream Kafka support various retry and error handling options, including time / count-based retry, Dead Letter Queues, etc.
Although the Spring framework is pretty feature-rich, it is a bit heavy and has a learning curve. Hence, it is a great fit for a greenfield project or if you are already using Spring for your projects for other scenarios.
Plenty of great blog posts exist that show different examples and configuration options. There is also the official Spring Cloud Stream example for dead letter queues. Spring allows building logic, such as DLQ, with simple annotations. This programming approach is a beloved paradigm by some developers, while others dislike it. Just know the options and choose the right one for yourself.
Scalable Processing and Error Handling with the Parallel Consumer for Apache Kafka
In many customer conversations, it turns out that often the main reason for asking for a dead letter queue is handling failures from connecting to external web services or databases. Time-outs or the inability of Kafka to send various requests in parallel brings down some applications. There is an excellent solution to this problem:
The Parallel Consumer for Apache Kafka is an open-source project under Apache 2.0 license. It provides a parallel Apache Kafka client wrapper with client-side queueing, a simpler consumer/producer API with key concurrency, and extendable non-blocking IO processing.
This library lets you process messages in parallel via a single Kafka Consumer, meaning you can increase Kafka consumer parallelism without increasing the number of partitions in the topic you intend to process. For many use cases, this improves both throughput and latency by reducing the load on your Kafka brokers. It also opens up new use cases like extreme parallelism, external data enrichment, and queuing.
A key feature is handling/repeating web service and database calls within a single Kafka consumer application. The parallelization avoids the need for a single web request sent at a time:
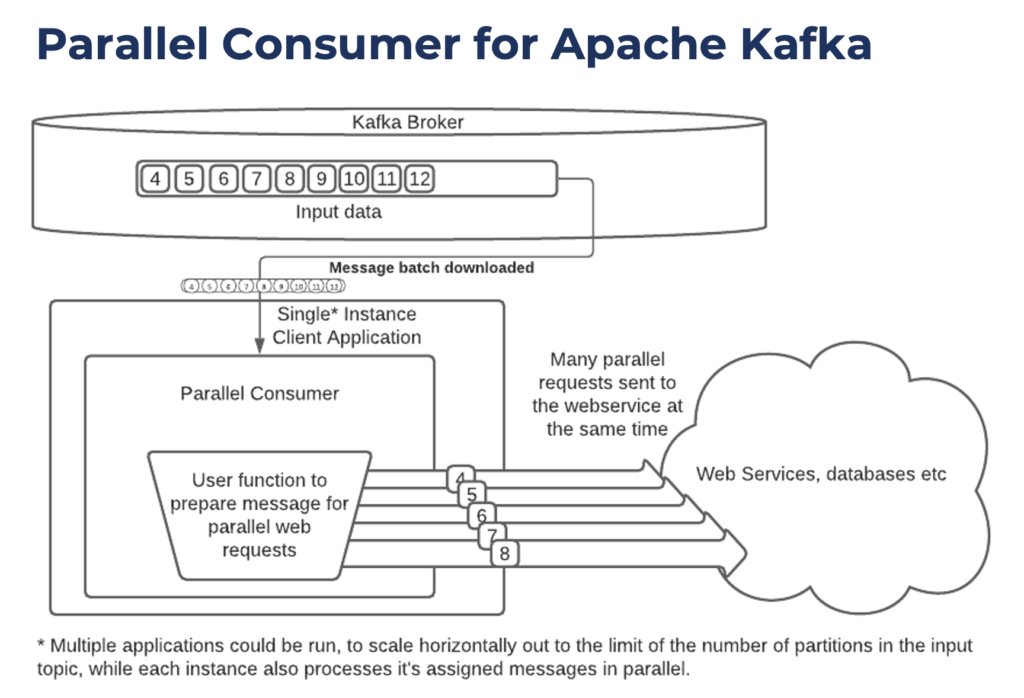
The Parallel Consumer client has powerful retry logic. This includes configurable delays and dynamic er or handling. Errors can also be sent to a dead letter queue.
Consuming Messages from a Dead Letter Queue
You are not finished after sending errors to a dead letter queue! The bad messages need to be processed or at least monitored!
Dead Letter Queue is an excellent way to take data error processing out-of-band from the event processing which means the error handlers can be created or evolved separately from the event processing code.
Plenty of error-handling strategies exist for using dead letter queues. DOs and DONTs explore the best practices and lessons learned.
Error handling strategies
Several options are available for handling messages stored in a dead letter queue:
- Re-process: Some messages in the DLQ need to be re-processed. However, first, the issue needs to be fixed. The solution can be an automatic script, human interaction to edit the message, or returning an error to the producer asking for re-sending the (corrected) message.
- Drop the bad messages (after further analysis): Bad messages might be expected depending on your setup. However, before dropping them, a business process should examine them. For instance, a dashboard app can consume the error messages and visualize them.
- Advanced analytics: Instead of processing each message in the DLQ, another option is to analyze the incoming data for real-time insights or issues. For instance, a simple ksqlDB application can apply stream processing for calculations, such as the average number of error messages per hour or any other insights that help decide on the errors in your Kafka applications.
- Stop the workflow: If bad messages are rarely expected, the consequence might be stopping the overall business process. The action can either be automated or decided by a human. Of course, stopping the workflow could also be done in the Kafka application that throws the error. The DLQ externalizes the problem and decision-making if needed.
- Ignore: This might sound like the worst option. Just let the dead letter queue fill up and do nothing. However, even this is fine in some use cases, like monitoring the overall behavior of the Kafka application. Keep in mind that a Kafka topic has a retention time, and messages are removed from the topic aft r that time. Just set this up the right way for you. And monitor the DLQ topic for unexpected behavior (like filling up way too quickly).
Best Practices for a Dead Letter Queue in Apache Kafka
Here are some best practices and lessons learned for error handling using a Dead Letter Queue within Kafka applications:
- Define a business process for dealing with invalid messages (automated vs. human)
- Reality: Often, nobody handles DLQ messages at all
- Alternative 1: The data owners need to receive the alerts, not just the infrastructure team
- Alternative 2: An alert should notify the system of record team that the data was bad, and they will need to re-send/fix the data from the system of record.
- If nobody cares or complains, consider questioning and reviewing the need for the existence of the DLQ. Instead, these messages could also be ignored in the initial Kafka application. This saves a lot of network load, infrastructure, and money.
- Build a dashboard with proper alerts and integrate the relevant teams (e.g., via email or Slack alerts)
- Define the error handling priority per Kafka topic (stop vs. drop vs. re-process)
- Only push non-retryable error messages to a DLQ – connection issues are the responsibility of the consumer application.
- Keep the original messages and store them in the DLQ (with additional headers such as the error message, time of the error, application name where the error occurred, etc.) – this makes re-processing and troubleshooting much more accessible.
- Think about how many Dead Letter Queue Kafka topics you need. There are always trade-offs. But storing all errors in a single DLQ might not make sense for further analysis and re-processing.
Remember that a DLQ kills processing in guaranteed order and makes any sort of offline processing much harder. Hence, a Kafka DLQ is not perfect for every use case.
When NOT to use a Dead Letter Queue in Kafka?
Let’s explore what kinds of messages you should NOT put into a Dead Letter Queue in Kafka:
- DLQ for backpressure handling? Using the DLQ for throttling because of a peak of a high volume of messages is not a good idea. The storage behind the Kafka log handles backpressure automatically. The consumer pulls data in the way it can take it at its pace (or it is misconfigured). Scale consumers elastically if possible. A DLQ does not help, even if your storage gets full. That’s its problem, independent of whether or not to use a DLQ.
- DLQ for connection failures? Putting messages into a DLQ because of failed connectivity does not help (even after several retries). The following message also can not connect to that system. You need to fix the connection issue instead. The messages can be stored in the regular topic as long as necessary (depending on the retention time).
Schema Registry for Data Governance and Error Prevention
Last but not least, let’s explore the possibility to reduce or even eliminate the need for a Dead Letter Queue in some scenarios.
The Schema Registry for Kafka is a way to ensure data cleansing to prevent errors in the payload from producers. It enforces the correct message structure in the Kafka producer:
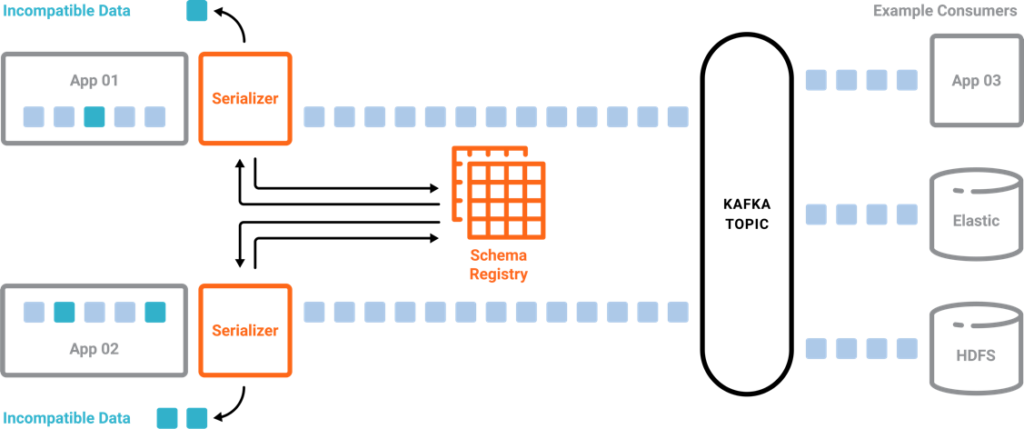
Schema Registry is a client-side check of the schema. Some implementations like Confluent Server provide an additional schema check on the broker side to reject invalid or malicious messages that come from a producer which is not using the Schema Registry.
Case Studies for a Dead Letter Queue in Kafka
Let’s look at four case studies from Uber, CrowdStrike, Santander Bank, and Robinhood for real-world deployment of Dead Letter Queues in a Kafka infrastructure. Keep in mind that those are very mature examples. Not every project needs that much complexity.
Uber – Building Reliable Reprocessing and Dead Letter Queues
In distributed systems, retries are inevitable. From network errors to replication issues and even outages in downstream dependencies, services operating at a massive scale must be prepared to encounter, identify, and handle failure as gracefully as possible.
Given the scope and pace at which Uber operates, its systems must be fault-tolerant and uncompromising when failing intelligently. Uber leverages Apache Kafka for various use cases at an extreme scale to accomplish this.
Using these properties, the Uber Insurance Engineering team extended Kafka’s role in their existing event-driven architecture by using non-blocking request reprocessing and Dead Letter Queues to achieve decoupled, observable error handling without disrupting real-time traffic. This strategy helps their opt-in Driver Injury Protection program run reliably in over 200 cities, deducting per-mile premiums per trip for enrolled drivers.
Here is an example of Uber’s error handling. Errors trickle-down levels of retry topics until landing in the DLQ:
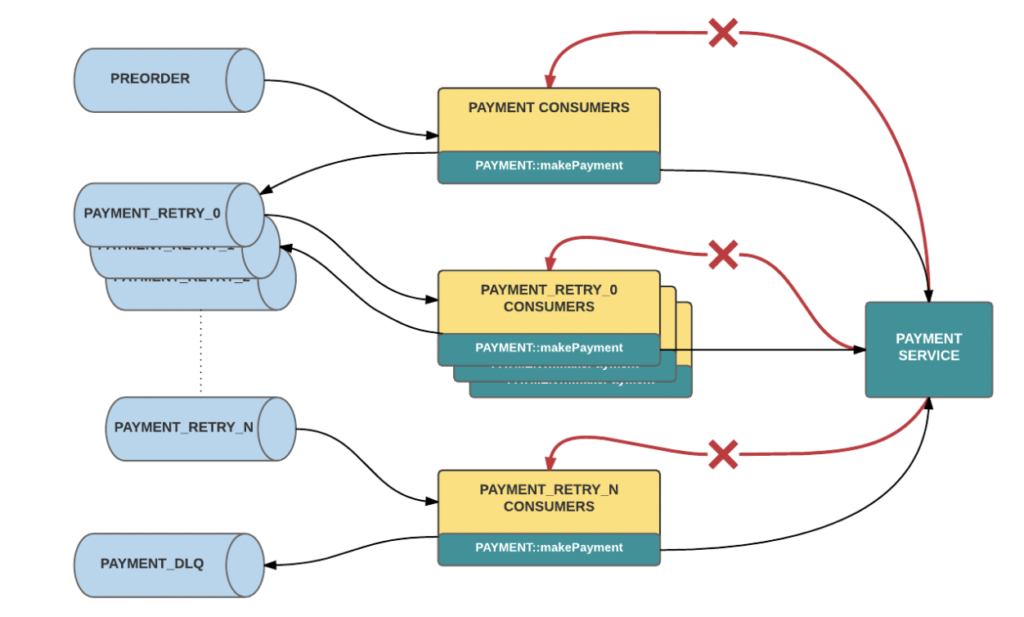
For more information, read Uber’s very detailed technical article: ‘Building Reliable Reprocessing and Dead Letter Queues with Apache Kafka‘.
CrowdStrike – Handling Errors for Trillions of Events
CrowdStrike is a cybersecurity technology company based in Austin, Texas. It provides cloud workload and endpoint security, threat intelligence, and cyberattack response services.
CrowdStrike’s infrastructure processes trillions of events daily with Apache Kafka. I covered related use cases for creating situational awareness and threat intelligence in real-time at any scale in my ‘Cybersecurity with Apache Kaka blog series‘.
CrowdStrike defines three best practices to implement Dead Letter Queues and error handling successfully:
- Store error message in the right system: Define the infrastructure and code to capture and retrieve dead letters. CrowdStrike uses an S3 object store for their potentially vast volumes of error messages. Note that Tiered Storage for Kafka solves this problem out-of-the-box without needing another storage interface (for instance, leveraging Infinite Storage in Confluent Cloud).
- Use automation: Put tooling in place to make remediation foolproof, as error handling can be very error-prone when done manually.
- Document the business process and engage relevant teams: Standardize and document the process to ensure ease of use. Not all engineers will be familiar with the organization’s strategy for dealing with dead letter messages.
In a cybersecurity platform like CrowdStrike, real-time data processing at scale is crucial. This requirement is valid for error handling, too. The next cyberattack might be a malicious message that intentionally includes inappropriate or invalid content (like a JavaScript exploit). Hence, handling errors in real-time via a Dead Letter Queue is a MUST.
Santander Bank – Mailbox 2.0 for a Combination of Retry and DLQ
Santander Bank had enormous challenges with their synchronous data processing in their mailbox application to process mass volumes of data. They rearchitected their infrastructure and built a decoupled and scalable architecture called “Santander Mailbox 2.0”.
Santander’s workloads and moved to Event Sourcing powered by Apache Kafka:

A key challenge in the new asynchronous event-based architecture was error handling. Santander solved the issues using error-handling built with retry and DLQ Kafka topics:
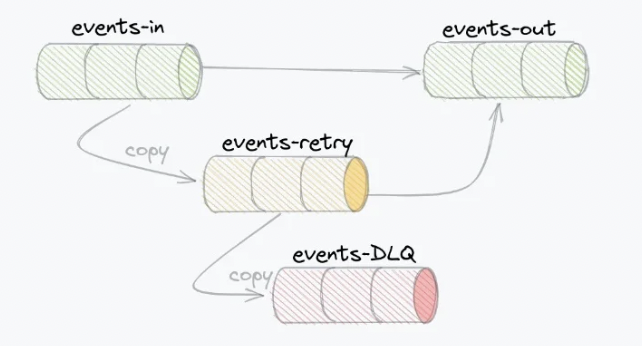
Check out the details in the Kafka Summit talk “Reliable Event Delivery in Apache Kafka Based on Retry Policy and Dead Letter Topics” from Santander’s integration partner Consdata.
Robinhood – Postgresql Database and GUI for Error Handling
Blog post UPDATE October 2022:
Robinhood, a financial services company (famous for its trading app), presented another approach for handling errors in Kafka messages at Current 2022. Instead of using only Kafka topics for error handling, they insert failed messages in a Postgresql database. A client application including CLI fixes the issues and republishes the messages to the Kafka topic:
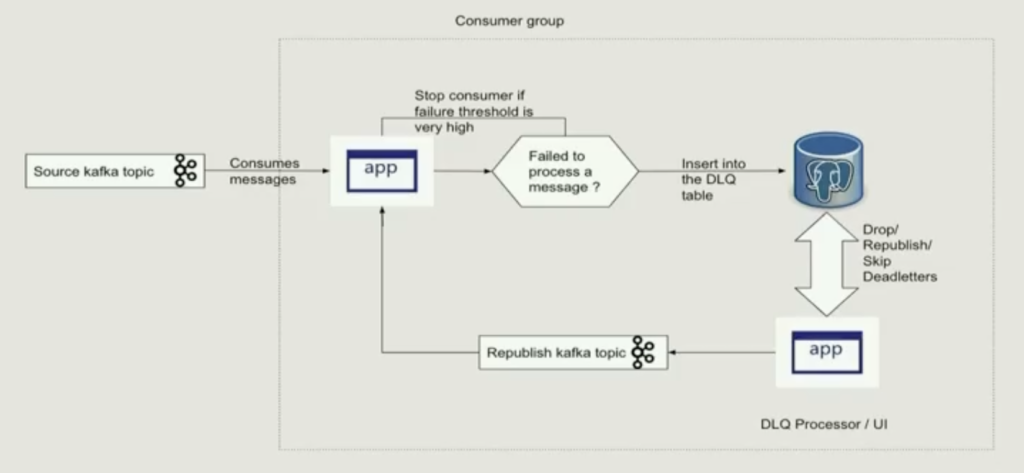
Real-world use cases at Robinhood include:
- Accounting issue that needs manual fixes
- Back office operations uploads documents, and human error results in duplicate entries
- Runtime checks for users have failed after an order was placed before it was executed
Currently, the error handling application is “only” usable via the command line and is relatively inflexible. New features will improve the DQL handling in the future:
- UI + Operational ease of use: Access controls around dead letter management (possible sensitive info in Kafka messages). Easier ordering requirements.
- Configurable data stores: Drop-in replacements for Postgres (e.g. DynamoDB). Direct integration of DLQ Kafka topics.
Robinhood’s DLQ implementation shows that error handling is worth investing in a dedicated project in some scenarios.
Reliable and Scalable Error Handling in Apache Kafka
Error handling is crucial for building reliable data streaming pipelines and platforms. Different alternatives exist for solving this problem. The solution includes a custom implementation of a Dead Letter Queue or leveraging frameworks in use anyway, such as Kafka Streams, Kafka Connect, the Spring framework, or the Parallel Consumer for Kafka.
The case studies from Uber, CrowdStrike, Santander Bank, and Robinhood showed that error handling is not always easy to implement. It needs to be thought through from the beginning when you design a new application or architecture. Real-time data streaming with Apache Kafka is compelling but only successful if you can handle unexpected behavior. Dead Letter Queues are an excellent option for many scenarios.
Do you use the Dead Letter Queue design pattern in your Apache Kafka applications? What are the use cases and limitations? How do you implement error handling in your Kafka applications? When do you prefer a message queue instead, and why? Let’s connect on LinkedIn and discuss it! S ay informed about new blog posts by subscribing to my newsletter.





