
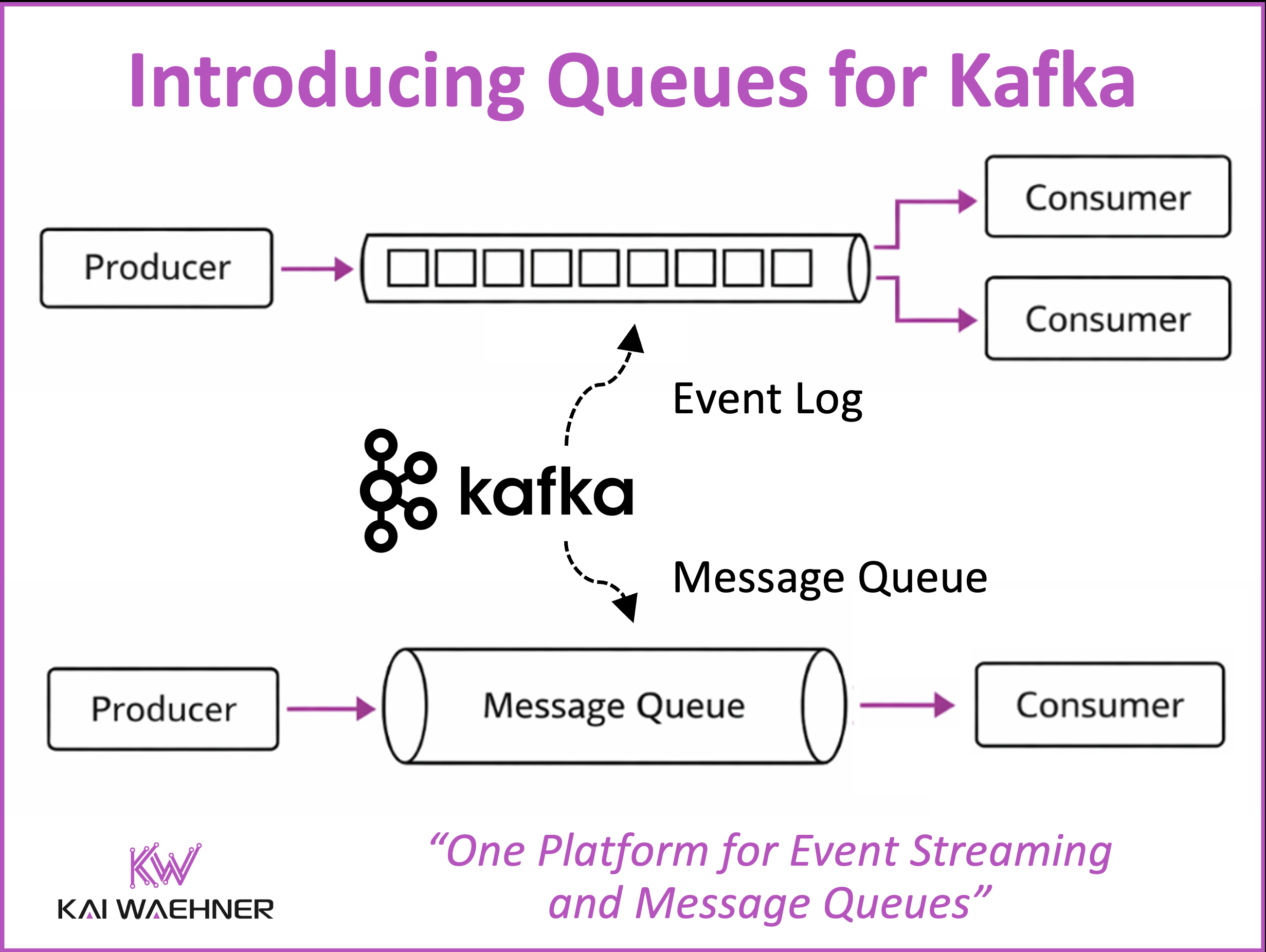
Apache Kafka
Apache Kafka has long been the foundation for real-time data streaming. With the release of Queues for Kafka (QfK) in Apache Kafka 4.2, it now
Apache Kafka has long been the foundation for real-time data streaming. With the release of Queues for Kafka (QfK) in Apache Kafka 4.2, it now

A Message broker has very different characteristics and use cases than a data streaming platform like Apache Kafka. Data integration, processing, governance, and security must

How can I do request-response communication with Apache Kafka? That’s one of the most common questions I get regularly. This blog post explores when (not)

Recognizing and handling errors is essential for any reliable data streaming pipeline. This blog post explores best practices for implementing error handling using a Dead
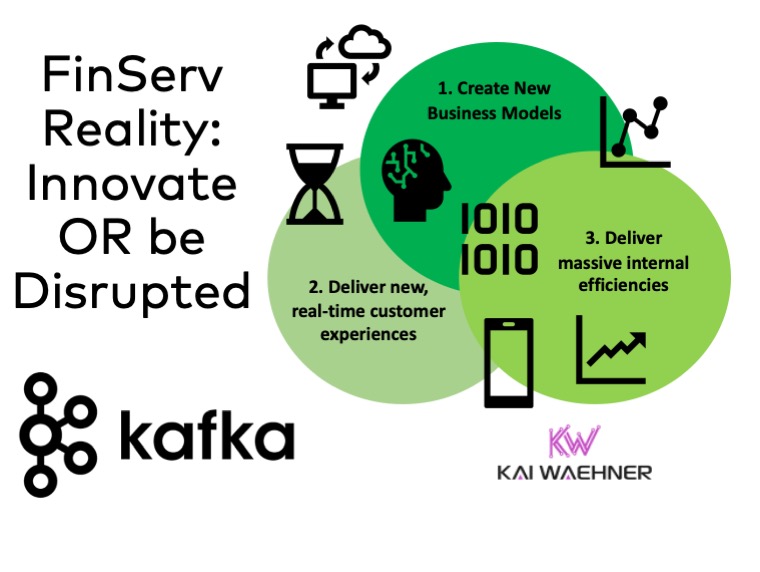
The rise of event streaming in financial services is growing like crazy. Continuous real-time data integration and processing are mandatory for many use cases. Apache

Pulsar vs Kafka – which one is better? This blog post explores pros and cons, popular myths, and non-technical criteria to find the best tool





You need to load content from reCAPTCHA to submit the form. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Turnstile. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Vimeo. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from YouTube. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou need to load content from reCAPTCHA to submit the form. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Elfsight. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Facebook. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More Information