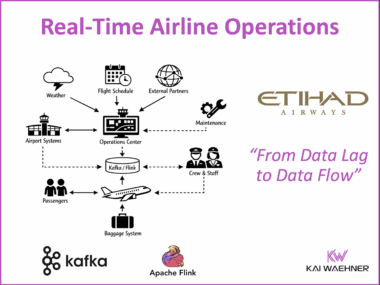
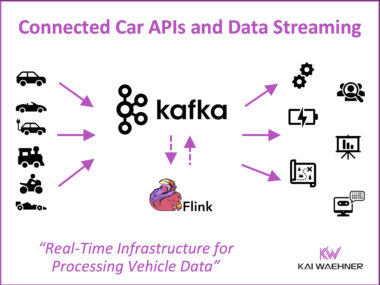
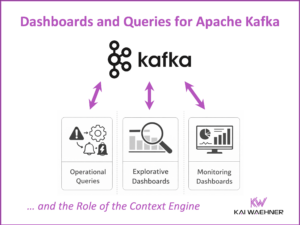
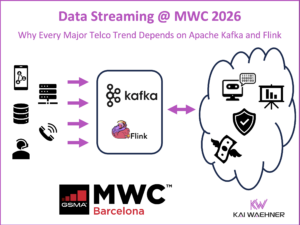
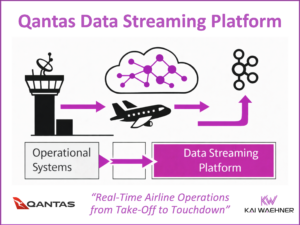
The Ultimate Data Streaming Guide is Back – Second Edition of the Book and Industry Editions Now Available
The second edition of The Ultimate Data Streaming Guide is now available as a free eBook. It includes over 70 use cases, over 20 customer stories, a detailed use case / customer matrix, and a stronger focus on AI topics like GenAI and Agentic AI. The book shows how organizations use Apache Kafka, Apache Flink, and the Confluent Data Streaming Platform to build real-time solutions with business impact. New Industry Editions are also available for Financial Services, Manufacturing and Automotive, Telecom and Media, and Digital Natives.