
Artificial Intelligence
XML, JSON, and YAML were built for different jobs in different eras. This post covers where each came from, how they compare, and where each

XML, JSON, and YAML were built for different jobs in different eras. This post covers where each came from, how they compare, and where each
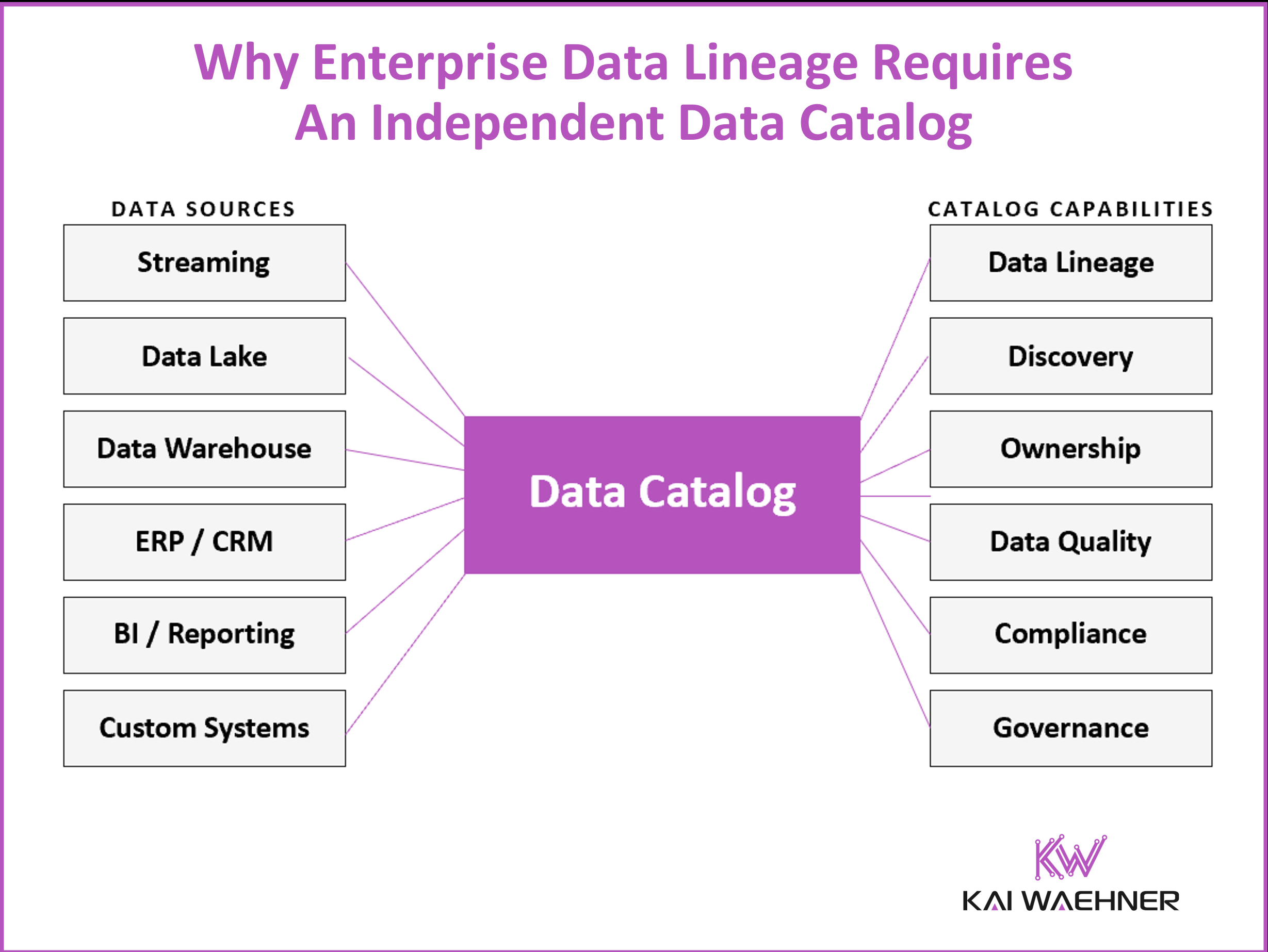
Most organizations start their data governance journey by asking how to track where data comes from and where it goes. They quickly discover a harder

Each year brings new momentum to the data streaming space. In 2026, six key trends stand out. Platforms and vendors are consolidating. Diskless Kafka and
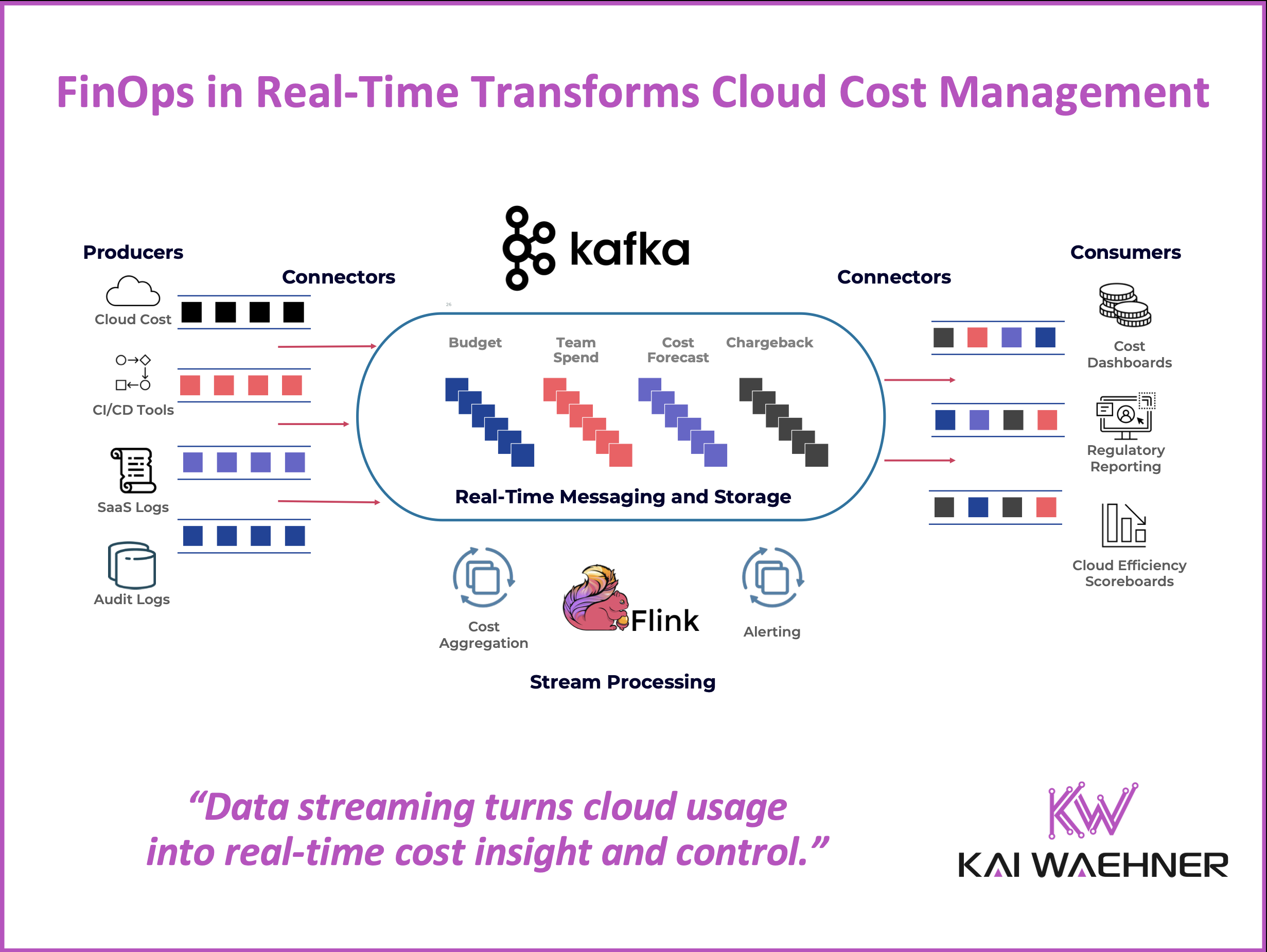
FinOps bridges the gap between finance and engineering to control cloud spend in real time. However, many organizations still rely on delayed, batch-driven data pipelines
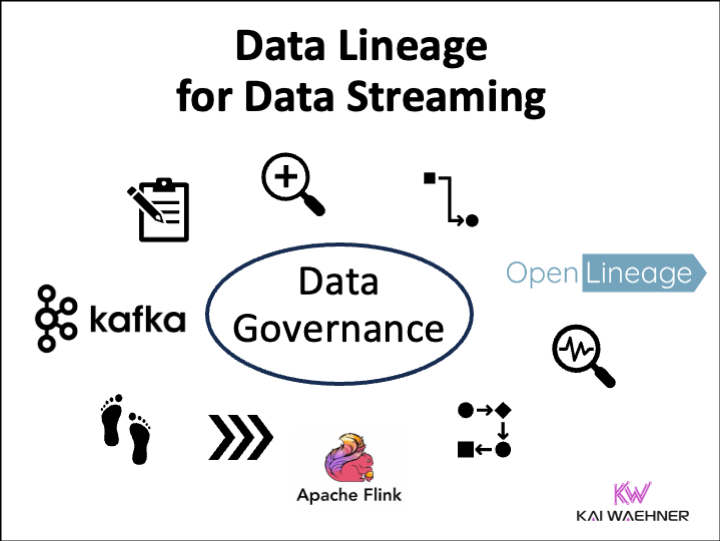
One of the greatest wishes of companies is end-to-end visibility in their operational and analytical workflows. Where does data come from? Where does it go?

Good data quality is one of the most critical requirements in decoupled architectures, like microservices or data mesh. Apache Kafka became the de facto standard
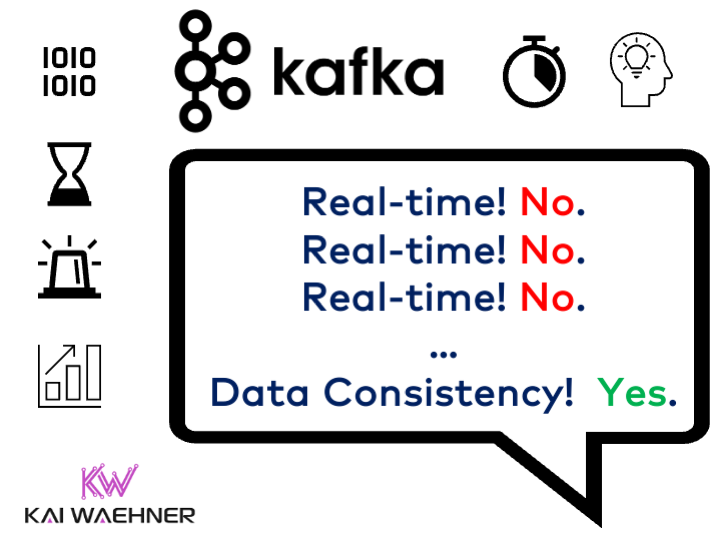
Real-time data beats slow data in almost all use cases. But as essential is data consistency across all systems, including non-real-time legacy systems and modern

Data Streaming is one of the most relevant buzzwords in tech to build scalable real-time applications in the cloud and innovative business models. Do you




You need to load content from reCAPTCHA to submit the form. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Turnstile. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Vimeo. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from YouTube. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou need to load content from reCAPTCHA to submit the form. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Elfsight. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More InformationYou are currently viewing a placeholder content from Facebook. To access the actual content, click the button below. Please note that doing so will share data with third-party providers.
More Information